-
The efficacy of methylprednisolone acetate nanogel in treating patients with sudden sensorineural hearing loss
Intratympanic injection of methylprednisolone acetate is considered to be one of the effective drugs in the treatment of sudden sensorineural hearing loss. In this study, the efficacy of intratympanic injection of methylprednisolone acetate nanogel in patients with sudden sensorineural hearing loss was investigated. It is a double-blind randomized clinical trial in one of Iran’s hospitals.… →

-
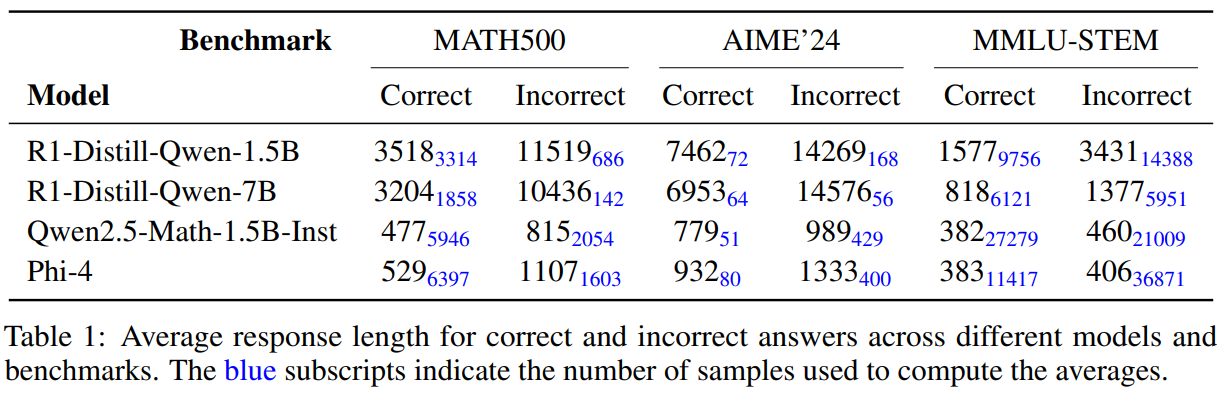
Balancing Accuracy and Efficiency in Language Models: A Two-Phase RL Post-Training Approach for Concise Reasoning…
Balancing Accuracy and Efficiency in Language Models: A Two-Phase RL Post-Training Approach for Concise Reasoning Recent advancements in LLMs have significantly enhanced their reasoning capabilities, particularly through RL-based fine-tuning. Initially trained with supervised learning for token prediction, these models undergo RL post-training, exploring various reasoning paths to arrive at correct answers, similar to how an… →
-
RoR-Bench: Revealing Recitation Over Reasoning in Large Language Models Through Subtle Context Shifts…
RoR-Bench: Revealing Recitation Over Reasoning in Large Language Models Through Subtle Context Shifts In recent years, the rapid progress of LLMs has given the impression that we are nearing the achievement of Artificial General Intelligence (AGI), with models seemingly capable of solving increasingly complex tasks. However, a fundamental question remains: Are LLMs genuinely reasoning like… →

-
Complete Guide: Working with CSV/Excel Files and EDA in Python
Complete Guide: Working with CSV/Excel Files and EDA in Python This hands-on tutorial will walk you through the entire process of working with CSV/Excel files and conducting exploratory data analysis (EDA) in Python. We& use a realistic e-commerce sales dataset that includes transactions, customer information, inventory data, and more. Table of contents [] [ Up… →

-
Selective removal of dental caries in permanent teeth: an 18-month clinical trial
CONCLUSION: SRCT was clinically effective in both mid-depth (D2) and deep (D3) lesions, addressing pulp sensitivity and restoration quality. In D3 lesions, it minimized the risk of pulp exposure while preserving dentin integrity, while in D2 lesions, it preserved tooth structure without compromising restoration performance. →

-
Immediate effect of ice and dry massage during rest breaks on recovery in MMA fighters : a randomized crossover clinical trial study
The MMA fight consists of 5 rounds of 5 min with minimal breaks between the rounds. The exertion load is excessive for the fighters, and the 1-minute breaks give little time for any intervention. This study aimed to examine the acute effects of two methods of regenerative strategies, ice massage and dry massage, and analyze… →

-
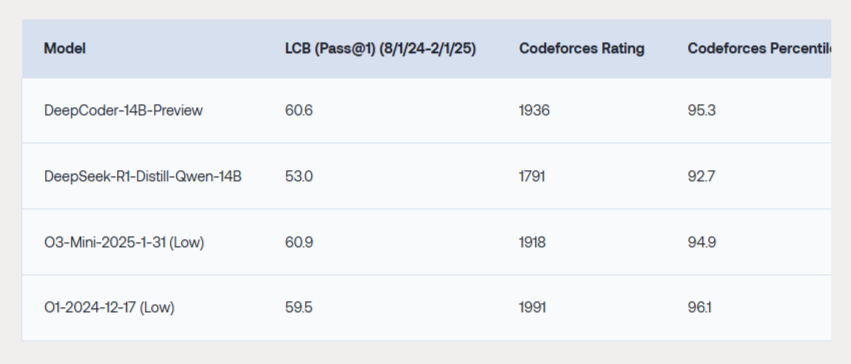
Together AI Released DeepCoder-14B-Preview: A Fully Open-Source Code Reasoning Model That Rivals o3-Mini With Just 14B Parameter…
Together AI Released DeepCoder-14B-Preview: A Fully Open-Source Code Reasoning Model That Rivals o3-Mini With Just 14B Parameters The demand for intelligent code generation and automated programming solutions has intensified, fueled by a rapid rise in software complexity and developer productivity needs. While natural language processing and general reasoning models have surged with significant breakthroughs, the… →
-
Alteryx vs Tableau: Optimize Supply Chain for Better Product Outcomes
Alteryx speeds up data blending and analytics improving supply chain visibility This leads to better decision-making and increased profitability Reducing manual data preparation time by 50% cuts labor costs Equivalent products from the list include Tableau or DataRobot →

-
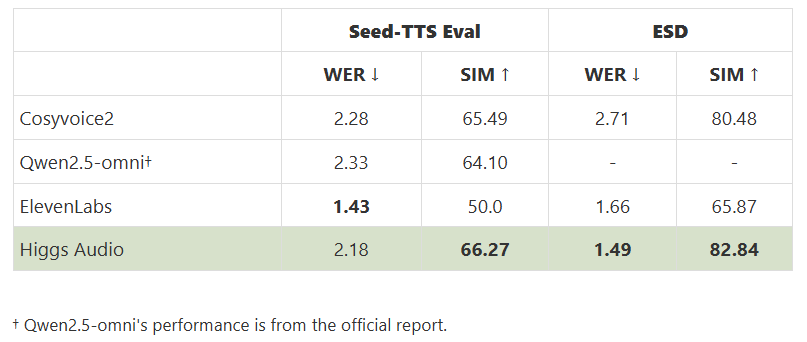
Boson AI Introduces Higgs Audio Understanding and Higgs Audio Generation: An Advanced AI Solution with Real-Time Audio Reasoning…
Boson AI Introduces Higgs Audio Understanding and Higgs Audio Generation: An Advanced AI Solution with Real-Time Audio Reasoning and Expressive Speech Synthesis for Enterprise Applications In today’s enterprise landscape— especially in insurance and customer support —voice and audio data are more than just recordings; they’re valuable touchpoints that can transform operations and customer experiences. With… →
-
Interview with Hamza Tahir: Co-founder and CTO of ZenML
Interview with Hamza Tahir: Co-founder and CTO of ZenML Bio: Hamza Tahir is a software developer turned ML engineer. An indie hacker by heart, he loves ideating, implementing, and launching data-driven products. His previous projects include , , , and . Based on his learnings from deploying ML in production for predictive maintenance use-cases in his… →