-
The effect of education using the interactive avatar application on self-care and the ability to identify and respond to the symptoms of heart attack in patients with acute coronary syndrome: a randomized clinical trial
CONCLUSIONS: The interactive avatar application proved effective in improving knowledge, attitudes, beliefs, and self-care behaviors among ACS patients. This innovative educational tool holds promise for enhancing patient outcomes in ACS management. →

-
Evaluating efficacy of laser-assisted new attachment procedure and adjunctive low-level laser therapy in treating periodontitis: A single-blind randomized controlled clinical study
CONCLUSION: In deep pockets, laser-treated groups provide additional benefits to SRP. The application of LLLT positively affected recession (REC). →

-
Clinical evaluation of in-office bleaching with low, medium, and high concentrate hydrogen peroxide: a 6-month a double-blinded randomized controlled trial
CONCLUSION: Low, medium, and high concentrations of HP did not affect both the final tooth color and the reported TS intensity, regardless of the evaluation time. In-office bleaching provides positive effects on aesthetic perception and different HP concentrations have not influenced this positive effect. →

-
A WeChat-Based Decision Aid Intervention to Promote Informed Decision-Making for Family Members Regarding the Genetic Testing of Patients With Colorectal Cancer: Randomized Controlled Trial
CONCLUSIONS: A DA tool may be a safe, effective, and resource-efficient approach to facilitate informed decision-making about genetic testing. However, the current DA tool requires optimization and further evaluation-for example, by leveraging more advanced technology than WeChat to develop a simpler and more intelligent DA system. →

-
LLMs Can Now Retain High Accuracy at 2-Bit Precision: Researchers from UNC Chapel Hill Introduce TACQ, a Task-Aware Quantization…
LLMs Can Now Retain High Accuracy at 2-Bit Precision: Researchers from UNC Chapel Hill Introduce TACQ, a Task-Aware Quantization Approach that Preserves Critical Weight Circuits for Compression Without Performance Loss LLMs show impressive capabilities across numerous applications, yet they face challenges due to computational demands and memory requirements. This challenge is acute in scenarios requiring… →

-
Long-Context Multimodal Understanding No Longer Requires Massive Models: NVIDIA AI Introduces Eagle 2.5, a Generalist Vision-Lan…
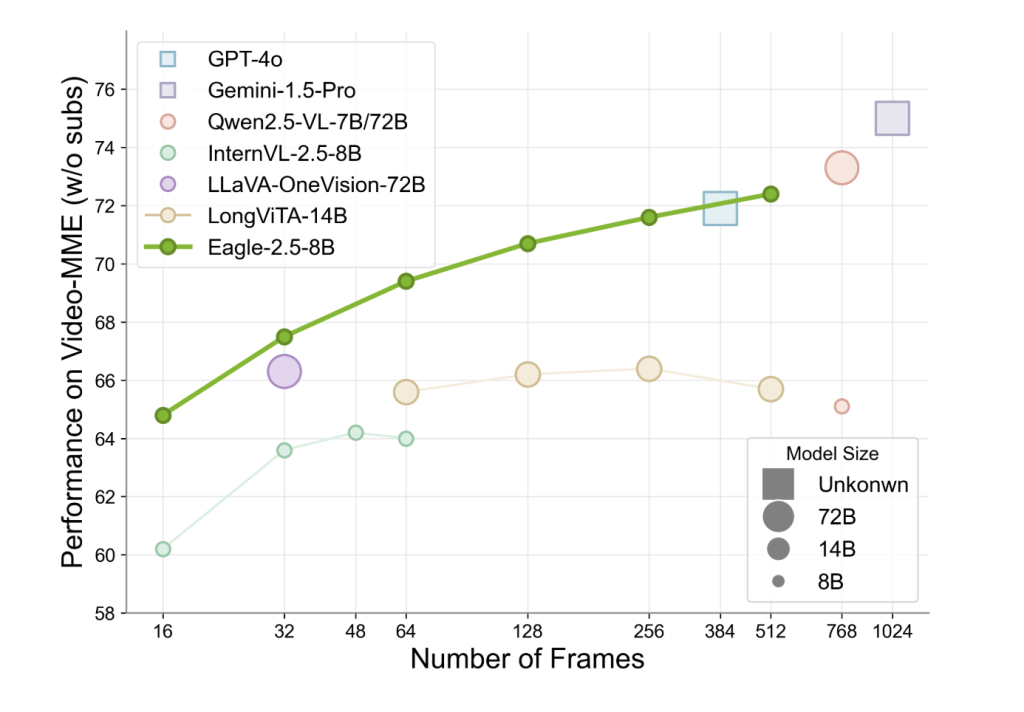
Long-Context Multimodal Understanding No Longer Requires Massive Models: NVIDIA AI Introduces Eagle 2.5, a Generalist Vision-Language Model that Matches GPT-4o on Video Tasks Using Just 8B Parameters In recent years, vision-language models (VLMs) have advanced significantly in bridging image, video, and textual modalities. Yet, a persistent limitation remains: the inability to effectively process long-context multimodal… →
-
Biohacking and Microplastic Exposure: The Need for a Microplastic Blood Test Kit
Biohacking and Microplastic Exposure: The Need for a Microplastic Blood Test Kit In the modern world, biohacking has become more than just a trend. It’s a movement dedicated to taking control of personal health, longevity, and well-being using cutting-edge science and technologies. Biohackers seek to enhance their bodies&; natural abilities by optimizing lifestyle choices, tracking… →

-
Efficacy of an Intelligent and Integrated Older Adult Care Model on Quality of Life Among Home-Dwelling Older Adults: Randomized Controlled Trial
CONCLUSIONS: The personalized and integrated older adult care by the SMART system demonstrated significant efficacy in improving QOL, health self-management ability, and social support, while reducing instrumental activities of daily living disability among home-dwelling older adults. →

-
Capecitabine metronomic chemotherapy for metastatic colorectal cancer patients reaching NED: A protocol for a prospective, randomized, controlled trial
INTRODUCTION: An increasing number of patients with metastatic colorectal cancer (mCRC) have achieved no evidence of diseases (NED) status after surgery or other treatments. However, the latest guidelines for colorectal cancer do not recommend an appropriate treatment for patients with mCRC who achieve NED status. Capecitabine metronomic chemotherapy has the advantages of significant efficacy and… →

-
One-Day Online Cognitive Behavioral Therapy-Based Workshops for the Prevention of Postpartum Depression: A Randomized Controlled Trial
Background: Postpartum depression (PPD) affects up to 1 in 5 birthing parents and is associated with more future depressive episodes. We aimed to determine if PPD could be prevented with online 1-day cognitive behavioral therapy (CBT)-based workshops. →
