-
The effect of game-based scenario writing on the clinical reasoning of internship nursing students in cardiovascular emergencies and critical care units
CONCLUSIONS: The current study’s findings support the argument that the gamified scenario-writing method can be an effective and dynamic learning method. It appears that employing this approach in nursing education could potentially enhance the CR of nursing students during their internship courses. Therefore, applying this method is recommended to nursing educators, especially for cardiac emergencies… →

-
Clinical Efficacy of Acupuncture Therapy Based on the Principles of Primary Point Selection, Local Point Selection, and Syndrome Differentiation in Rheumatoid Arthritis
CONCLUSION: Acupuncture treatment based on primary point selection, local point selection, and syndrome differentiation significantly alleviates clinical symptoms and inflammatory states in patients with RA, thereby improving quality of life. →

-
«It gives me the strength and courage to take care of myself»: a qualitative exploration of experiences with STI testing among women who initiated PrEP during pregnancy in Western Kenya
CONCLUSIONS: In this qualitative evaluation among women who initiated PrEP in pregnancy, STI testing encouraged PrEP use, even when results were negative. Incorporating STI testing within PrEP delivery in antenatal care represents an opportunity for addressing HIV/STI in this priority population. →

-
A New Citibank Report/Guide Shares How Agentic AI Will Reshape Finance with Autonomous Analysis and Intelligent Automation…
A New Citibank Report/Guide Shares How Agentic AI Will Reshape Finance with Autonomous Analysis and Intelligent Automation In its latest & AI Finance & the ‘Do It For Me’ Economy&; report, Citibank explores a significant paradigm shift underway in financial services: the rise of agentic AI. Unlike conventional AI systems that rely on prompts or… →

-
A Coding Guide to Asynchronous Web Data Extraction Using Crawl4AI: An Open-Source Web Crawling and Scraping Toolkit Designed for…
A Coding Guide to Asynchronous Web Data Extraction Using Crawl4AI: An Open-Source Web Crawling and Scraping Toolkit Designed for LLM Workflows In this tutorial, we demonstrate how to harness , a modern, Python‑based web crawling toolkit, to extract structured data from web pages directly within Google Colab. Leveraging the power of asyncio for asynchronous I/O,… →

-
Sequential-NIAH: A Benchmark for Evaluating LLMs in Extracting Sequential Information from Long Texts…
Sequential-NIAH: A Benchmark for Evaluating LLMs in Extracting Sequential Information from Long Texts Evaluating how well LLMs handle long contexts is essential, especially for retrieving specific, relevant information embedded in lengthy inputs. Many recent LLMs—such as Gemini-1.5, GPT-4, Claude-3.5, Qwen-2.5, and others—have pushed the boundaries of context length while striving to maintain strong reasoning abilities.… →
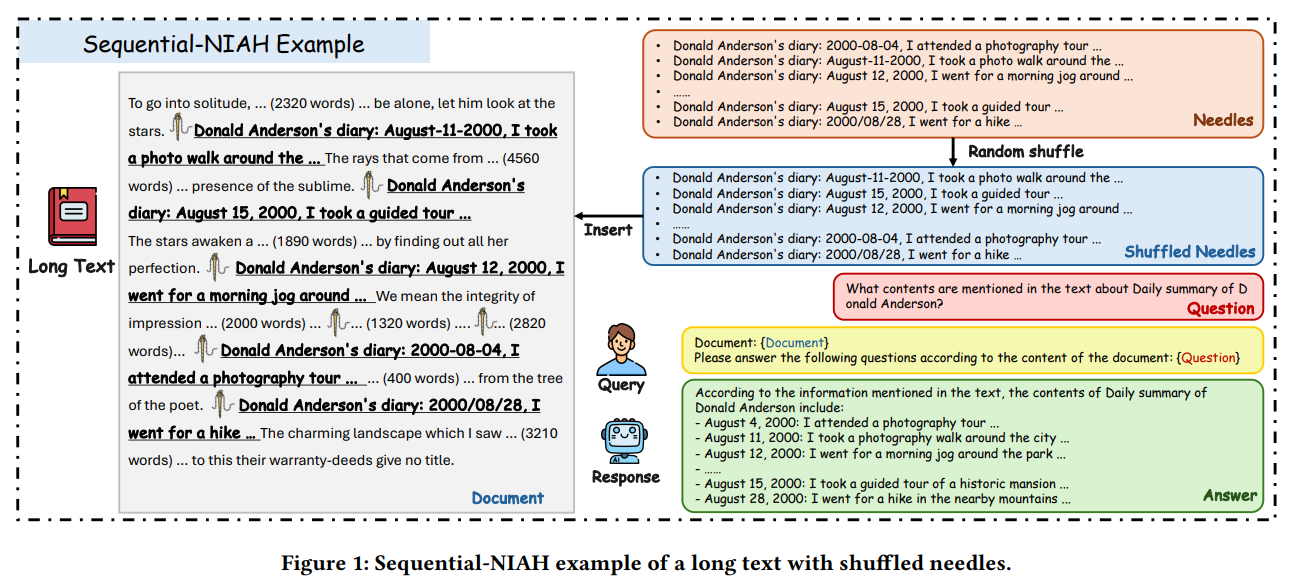
-
AWS Introduces SWE-PolyBench: A New Open-Source Multilingual Benchmark for Evaluating AI Coding Agents…
AWS Introduces SWE-PolyBench: A New Open-Source Multilingual Benchmark for Evaluating AI Coding Agents Recent advancements in large language models (LLMs) have enabled the development of AI-based coding agents that can generate, modify, and understand software code. However, the evaluation of these systems remains limited, often constrained to synthetic or narrowly scoped benchmarks, primarily in Python.… →
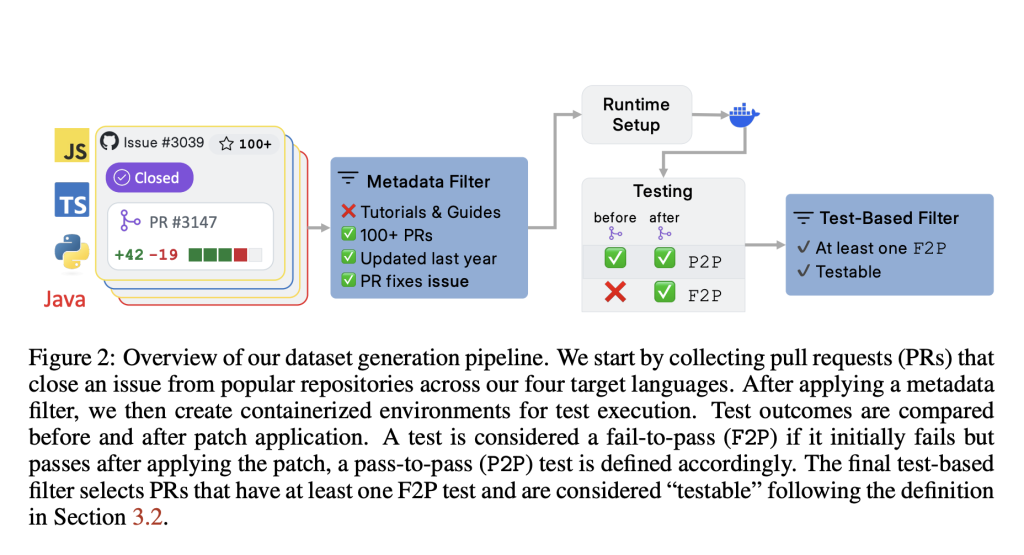
-
Appen vs Scale AI: Multilingual AI Training for Global Product Teams
Appen specializes in multilingual data for global AI applications like voice recognition This increases profitability by expanding market reach Streamlining data collection via crowdsourcing reduces operational expenses Equivalent products from the list include Scale AI or Amazon Mechanical Turk →

-
Meet Xata Agent: An Open Source Agent for Proactive PostgreSQL Monitoring, Automated Troubleshooting, and Seamless DevOps Integr…
Meet Xata Agent: An Open Source Agent for Proactive PostgreSQL Monitoring, Automated Troubleshooting, and Seamless DevOps Integration is an open-source AI assistant built to serve as a site reliability engineer for PostgreSQL databases. It constantly monitors logs and performance metrics, capturing signals such as slow queries, CPU and memory spikes, and abnormal connection counts, to… →
