AI News
Category Added in a WPeMatico Campaign
-

A Code Implementation for Advanced Human Pose Estimation Using MediaPipe, OpenCV and Matplotlib
A Code Implementation for Advanced Human Pose Estimation Using MediaPipe, OpenCV and Matplotlib Human pose estimation is a cutting-edge computer vision technology that transforms visual data into actionable insights about human movement. By utilizing advanced models like MediaPipe& BlazePose and powerful libraries such as OpenCV, developers can track body key points with unprecedented accuracy. In…
-
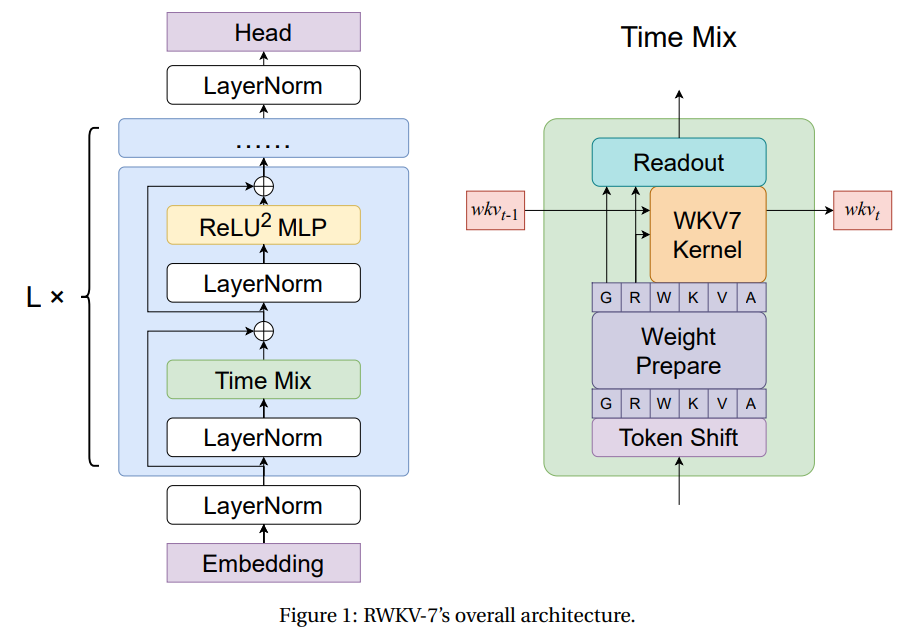
RWKV-7: Advancing Recurrent Neural Networks for Efficient Sequence Modeling
RWKV-7: Advancing Recurrent Neural Networks for Efficient Sequence Modeling Autoregressive Transformers have become the leading approach for sequence modeling due to their strong in-context learning and parallelizable training enabled by softmax attention. However, softmax attention has quadratic complexity in sequence length, leading to high computational and memory demands, especially for long sequences. While GPU optimizations…
-
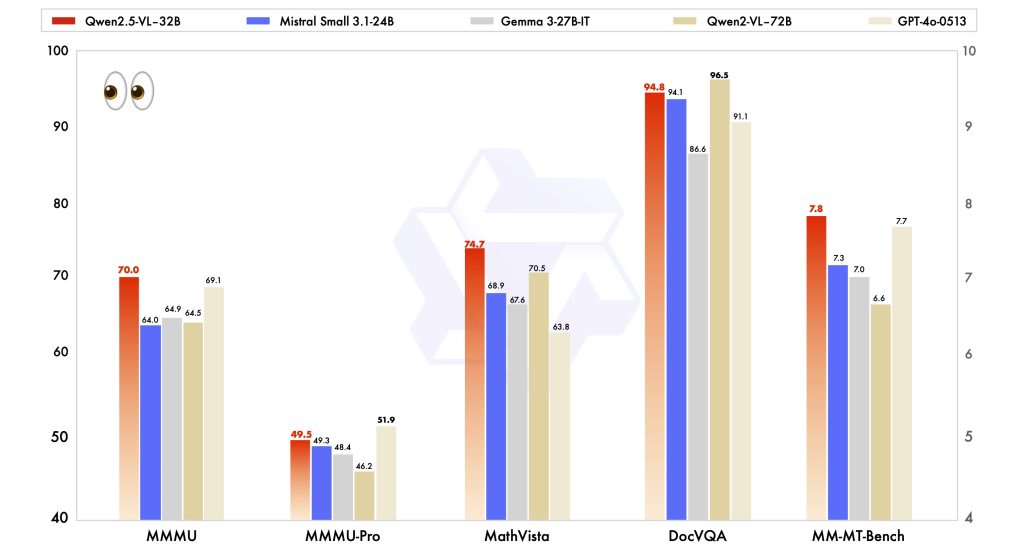
Qwen Releases the Qwen2.5-VL-32B-Instruct: A 32B Parameter VLM that Surpasses Qwen2.5-VL-72B and Other Models like GPT-4o Mini…
Qwen Releases the Qwen2.5-VL-32B-Instruct: A 32B Parameter VLM that Surpasses Qwen2.5-VL-72B and Other Models like GPT-4o Mini In the evolving field of artificial intelligence, vision-language models (VLMs) have become essential tools, enabling machines to interpret and generate insights from both visual and textual data. Despite advancements, challenges remain in balancing model performance with computational efficiency,…
-
A Coding Implementation of Extracting Structured Data Using LangSmith, Pydantic, LangChain, and Claude 3.7 Sonnet…
A Coding Implementation of Extracting Structured Data Using LangSmith, Pydantic, LangChain, and Claude 3.7 Sonnet Unlock the power of structured data extraction with LangChain and Claude 3.7 Sonnet, transforming raw text into actionable insights. This tutorial focuses on tracing LLM tool calling using LangSmith, enabling real-time debugging and performance monitoring of your extraction system. We…
-
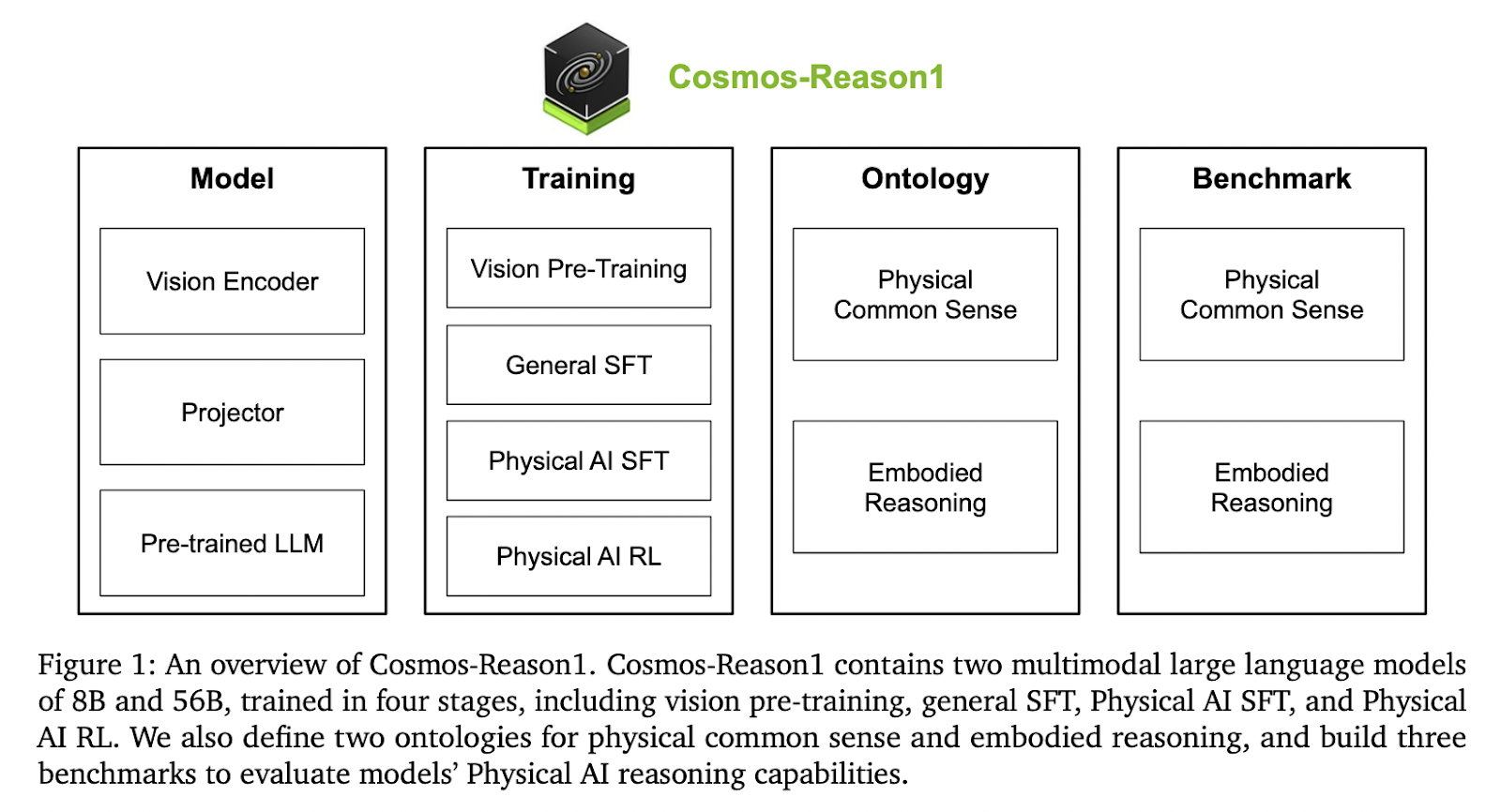
This AI Paper from NVIDIA Introduces Cosmos-Reason1: A Multimodal Model for Physical Common Sense and Embodied Reasoning…
This AI Paper from NVIDIA Introduces Cosmos-Reason1: A Multimodal Model for Physical Common Sense and Embodied Reasoning Artificial intelligence systems designed for physical settings require more than just perceptual abilities—they must also reason about objects, actions, and consequences in dynamic, real-world environments. These systems must understand spatial arrangements, cause-and-effect relationships, and the progression of events…
-

TokenSet: A Dynamic Set-Based Framework for Semantic-Aware Visual Representation
TokenSet: A Dynamic Set-Based Framework for Semantic-Aware Visual Representation Visual generation frameworks follow a two-stage approach: first compressing visual signals into latent representations and then modeling the low-dimensional distributions. However, conventional tokenization methods apply uniform spatial compression ratios regardless of the semantic complexity of different regions within an image. For instance, in a beach photo,…
-

Lyra: A Computationally Efficient Subquadratic Architecture for Biological Sequence Modeling
Lyra: A Computationally Efficient Subquadratic Architecture for Biological Sequence Modeling Deep learning architectures like CNNs and Transformers have significantly advanced biological sequence modeling by capturing local and long-range dependencies. However, their application in biological contexts is constrained by high computational demands and the need for large datasets. CNNs efficiently detect local sequence patterns with subquadratic…
-
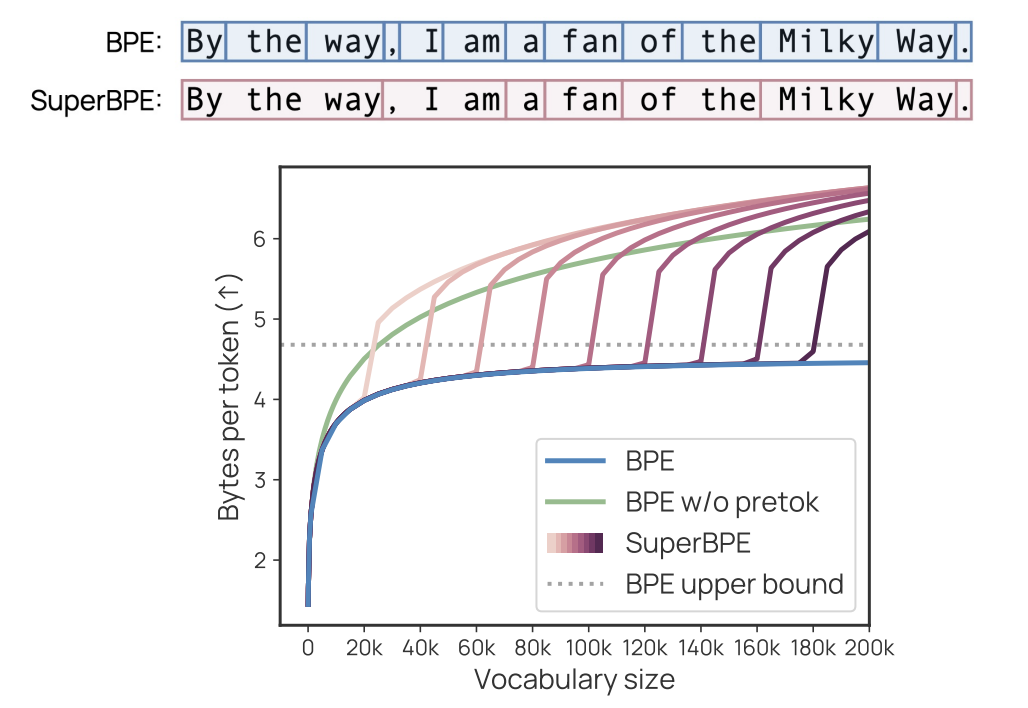
SuperBPE: Advancing Language Models with Cross-Word Tokenization
SuperBPE: Advancing Language Models with Cross-Word Tokenization Language models (LMs) face a fundamental challenge in how to perceive textual data through tokenization. Current subword tokenizers segment text into vocabulary tokens that cannot bridge whitespace, adhering to an artificial constraint that treats space as a semantic boundary. This practice ignores the reality that meaning often exceeds…
-
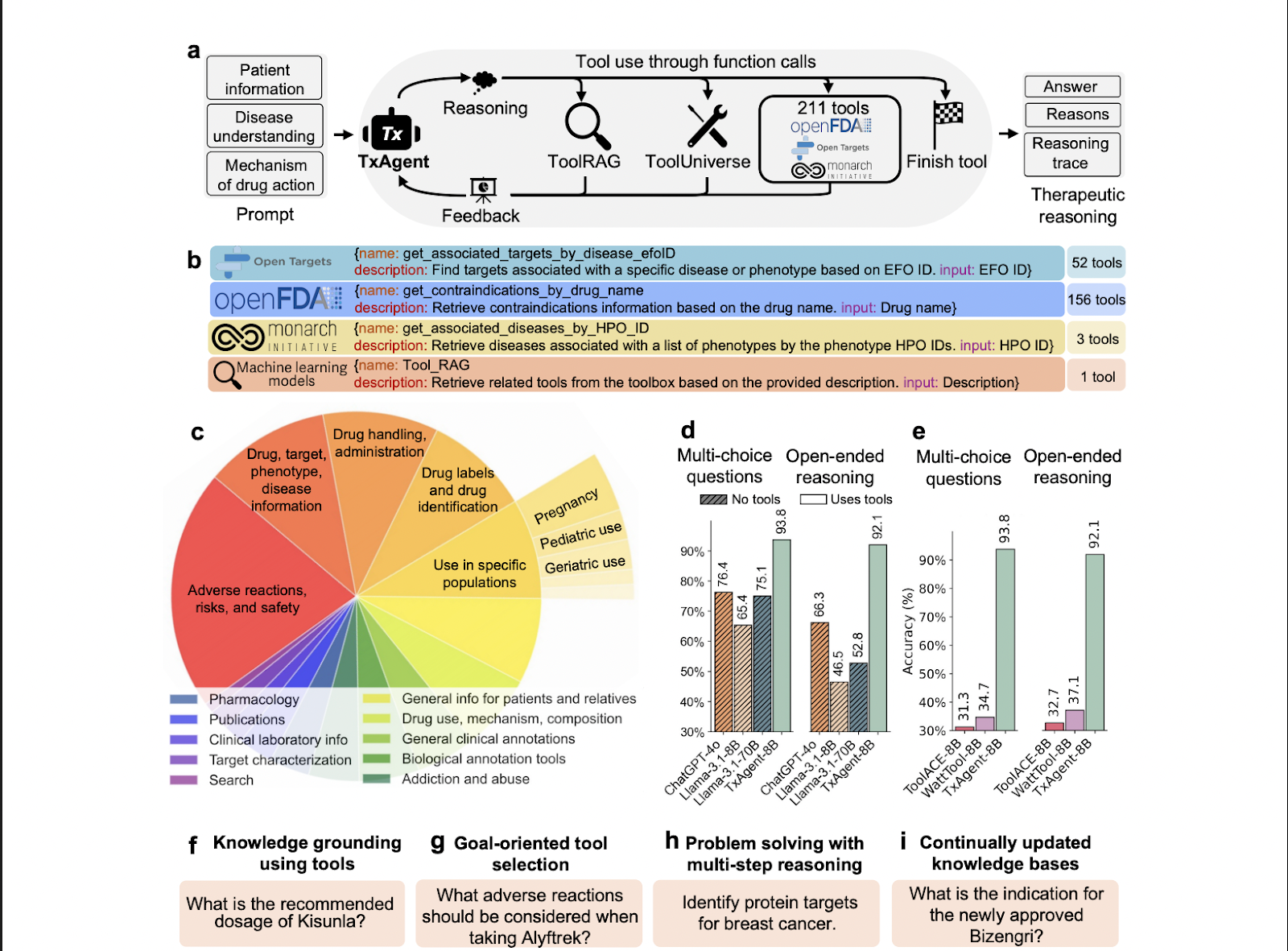
TxAgent: An AI Agent that Delivers Evidence-Grounded Treatment Recommendations by Combining Multi-Step Reasoning with Real-Time …
TxAgent: An AI Agent that Delivers Evidence-Grounded Treatment Recommendations by Combining Multi-Step Reasoning with Real-Time Biomedical Tool Integration Precision therapy has emerged as a critical approach in healthcare, tailoring treatments to individual patient profiles to optimise outcomes while reducing risks. However, determining the appropriate medication involves a complex analysis of numerous factors: patient characteristics, comorbidities,…
-
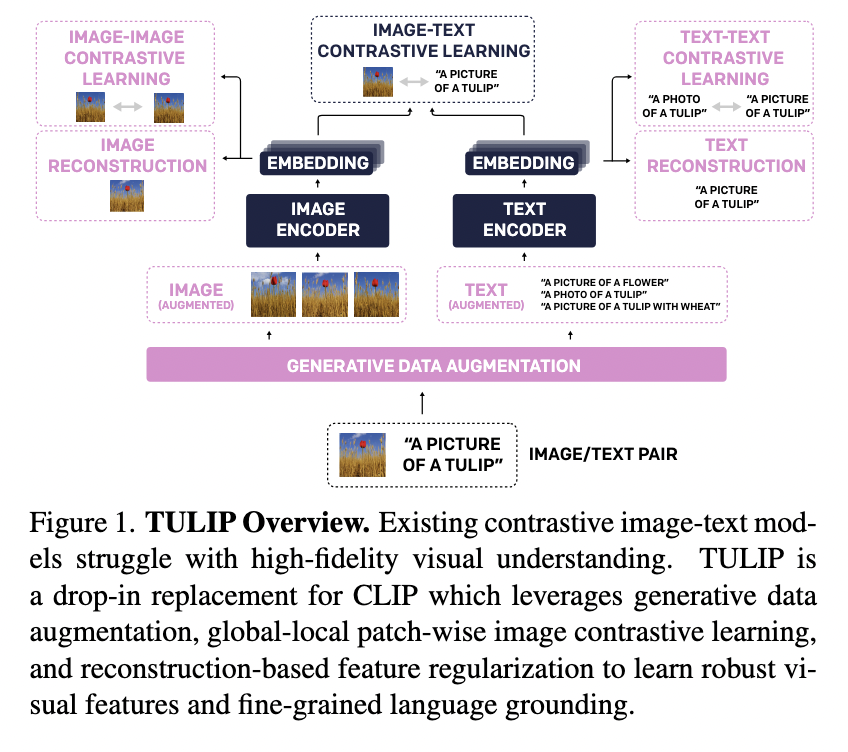
This AI Paper from UC Berkeley Introduces TULIP: A Unified Contrastive Learning Model for High-Fidelity Vision and Language Unde…
This AI Paper from UC Berkeley Introduces TULIP: A Unified Contrastive Learning Model for High-Fidelity Vision and Language Understanding Recent advancements in artificial intelligence have significantly improved how machines learn to associate visual content with language. Contrastive learning models have been pivotal in this transformation, particularly those aligning images and text through a shared embedding…