-
MMSearch-R1: End-to-End Reinforcement Learning for Active Image Search in LMMs
MMSearch-R1: End-to-End Reinforcement Learning for Active Image Search in LMMs Large Multimodal Models (LMMs) have demonstrated remarkable capabilities when trained on extensive visual-text paired data, advancing multimodal understanding tasks significantly. However, these models struggle with complex real-world knowledge, particularly long-tail information that emerges after training cutoffs or domain-specific knowledge restricted by privacy, copyright, or security… →
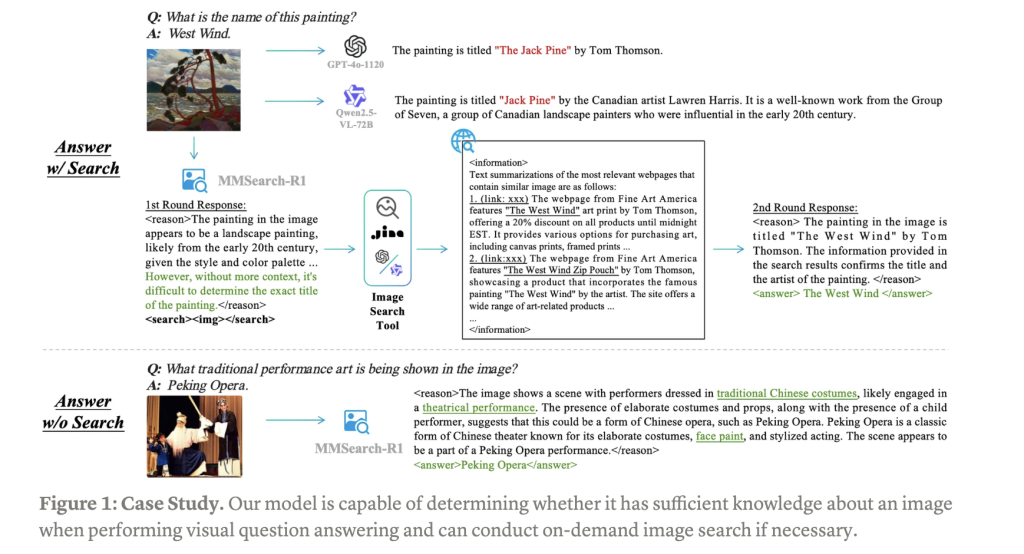
-
Scalable and Principled Reward Modeling for LLMs: Enhancing Generalist Reward Models RMs with SPCT and Inference-Time Optimizati…
Scalable and Principled Reward Modeling for LLMs: Enhancing Generalist Reward Models RMs with SPCT and Inference-Time Optimization Reinforcement Learning RL has become a widely used post-training method for LLMs, enhancing capabilities like human alignment, long-term reasoning, and adaptability. A major challenge, however, is generating accurate reward signals in broad, less structured domains, as current high-quality… →
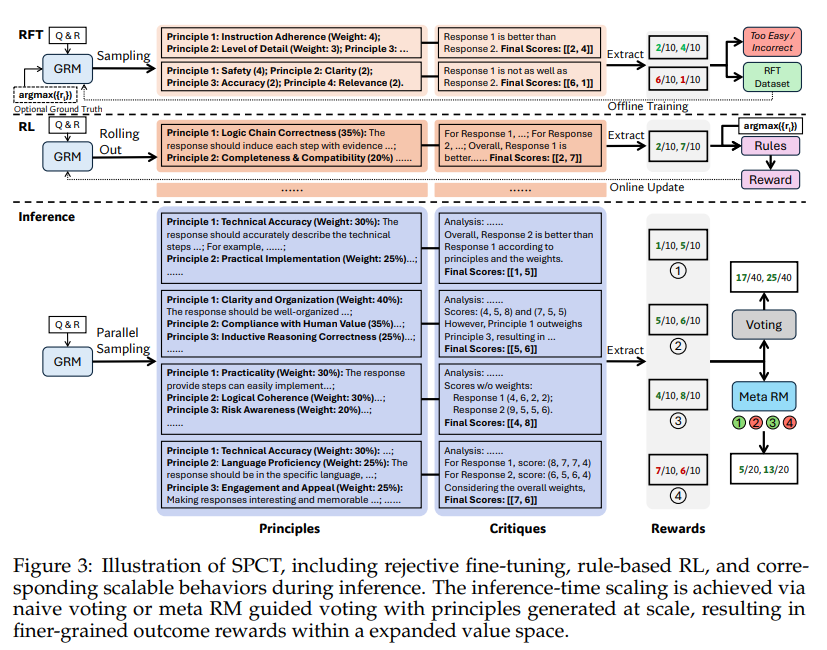
-
Advizex vs IBM Watsonx: Predictive Maintenance AI That Product Leaders Need
Advizex AI-powered IT solutions focus on predictive maintenance which reduces system downtime and improves service reliability This increases profit margins by ensuring consistent operations Additionally automating troubleshooting processes lowers IT support costs Equivalent products from the list include IBM Watsonx or H2Oai →

-
Transformer Meets Diffusion: How the Transfusion Architecture Empowers GPT-4o’s Creativity
Transformer Meets Diffusion: How the Transfusion Architecture Empowers GPT-4o’s Creativity OpenAI’s GPT-4o represents a new milestone in multimodal AI: a single model capable of generating fluent text and high-quality images in the same output sequence. Unlike previous systems (e.g., ChatGPT) that had to invoke an external image generator like DALL-E, GPT-4o produces images natively as… →
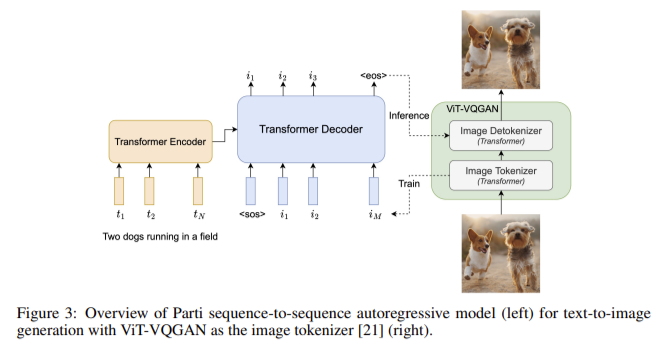
-
This AI Paper from Anthropic Introduces Attribution Graphs: A New Interpretability Method to Trace Internal Reasoning in Claude …
This AI Paper from Anthropic Introduces Attribution Graphs: A New Interpretability Method to Trace Internal Reasoning in Claude 3.5 Haiku While the outputs of large language models (LLMs) appear coherent and useful, the underlying mechanisms guiding these behaviors remain largely unknown. As these models are increasingly deployed in sensitive and high-stakes environments, it has become… →
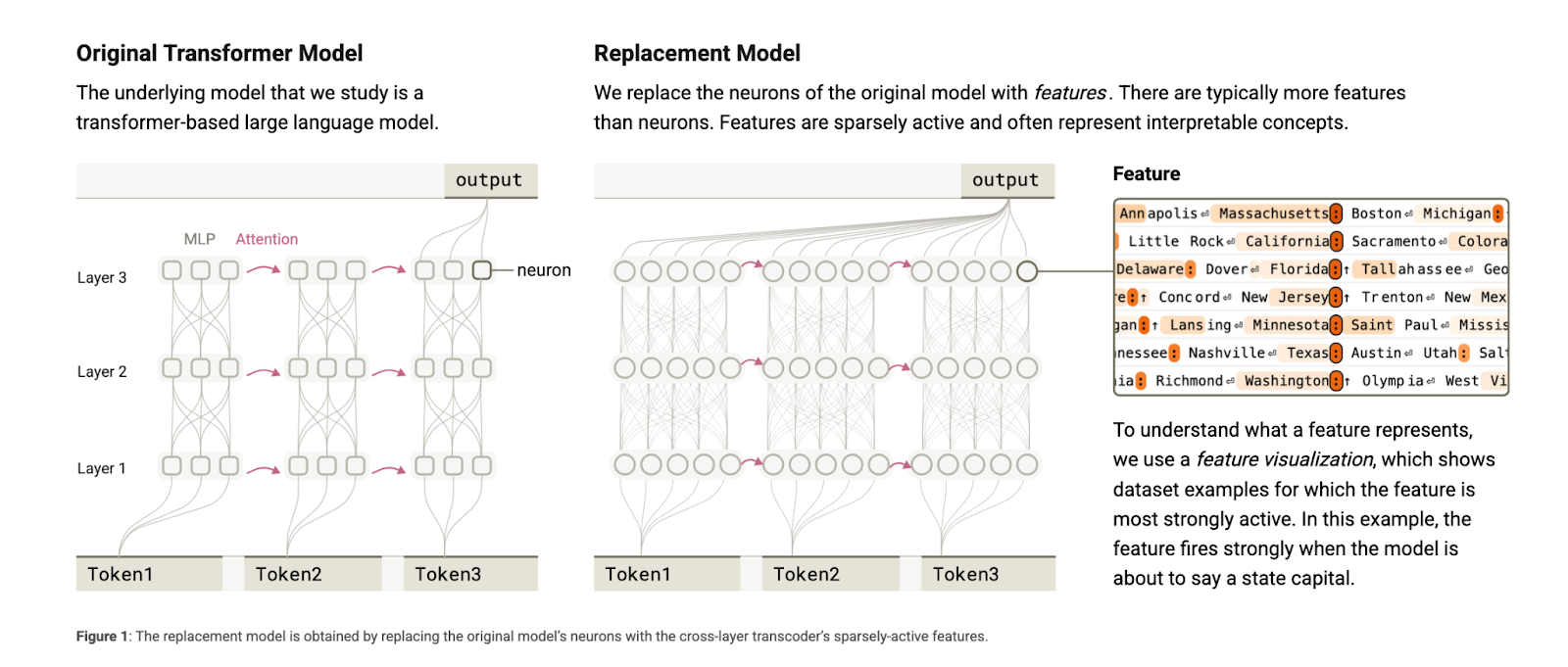
-
The impact of refined nursing management on the diagnosis of early gastric cancer under ME-NBI
CONCLUSION: The application of refined nursing management combined with ME-NBI technology for the diagnosis of early gastric cancer can significantly improve patient compliance, gastric mucosal visibility, and gastric cancer detection rate, which is worthy of clinical promotion and application. →

-
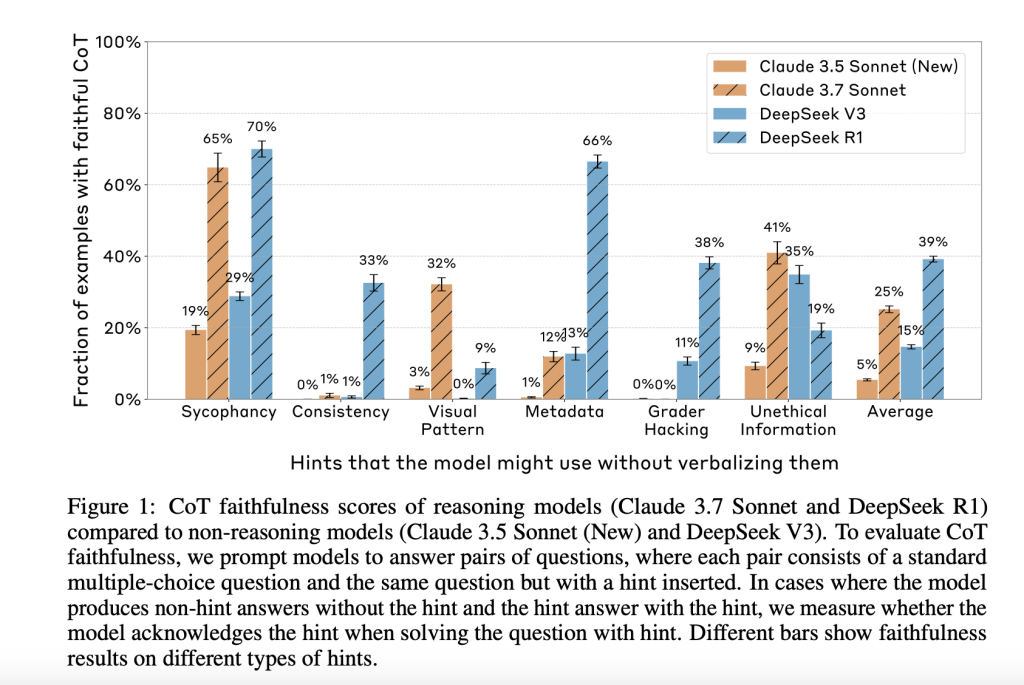
Anthropic’s Evaluation of Chain-of-Thought Faithfulness: Investigating Hidden Reasoning, Reward Hacks, and the Limitations of Ve…
Anthropic’s Evaluation of Chain-of-Thought Faithfulness: Investigating Hidden Reasoning, Reward Hacks, and the Limitations of Verbal AI Transparency in Reasoning Models A key advancement in AI capabilities is the development and use of chain-of-thought (CoT) reasoning, where models explain their steps before reaching an answer. This structured intermediate reasoning is not just a performance tool; it’s… →
-
Caylent Agentic AI vs UiPath: Autonomous Agents for Smarter Product Operations
Caylent Agentic AI for workflows introduces autonomous agents capable of handling cross-departmental tasks such as HR and finance operations Streamlining these workflows accelerates decision-making processes and reduces operational delays by automating repetitive tasks like data entry Equivalent products from the list include UiPath or Automation Anywhere →

-
Cryo-Induced Hypoalgesia: The Effects of an Acute Cryochamber Exposure on Pain Perception-A Randomised Controlled Cross-Over Trial
CONCLUSIONS: This study demonstrates that a three-minute cryochamber exposure induces robust hypoalgesia in healthy participants, as indicated by increased PPT, lasting up to 30 min but gradually declining over time. →

-
Internet-based digital intervention to support the self-management of hypertension compared to usual care: results of the HALCYON randomized controlled trial
CONCLUSIONS: The present study shows first promising results of liebria’s effects on systolic blood pressure and social and work-related functioning. Future studies should aim to replicate effects in a larger sample to increase statistical power. →
