In recent years, speech synthesis has undergone a profound transformation thanks to the emergence of large-scale generative models. This evolution has led to significant strides in zero-shot speech synthesis systems, including text-to-speech (TTS), voice conversion (VC), and editing. These systems aim to generate speech by incorporating unseen speaker characteristics from a reference audio segment during inference without requiring additional training data.
The latest advancements in this domain leverage language and diffusion-style models for in-context speech generation on large-scale datasets. However, due to the intrinsic mechanisms of language and diffusion models, the generation process of these methods often entails extensive computational time and cost.
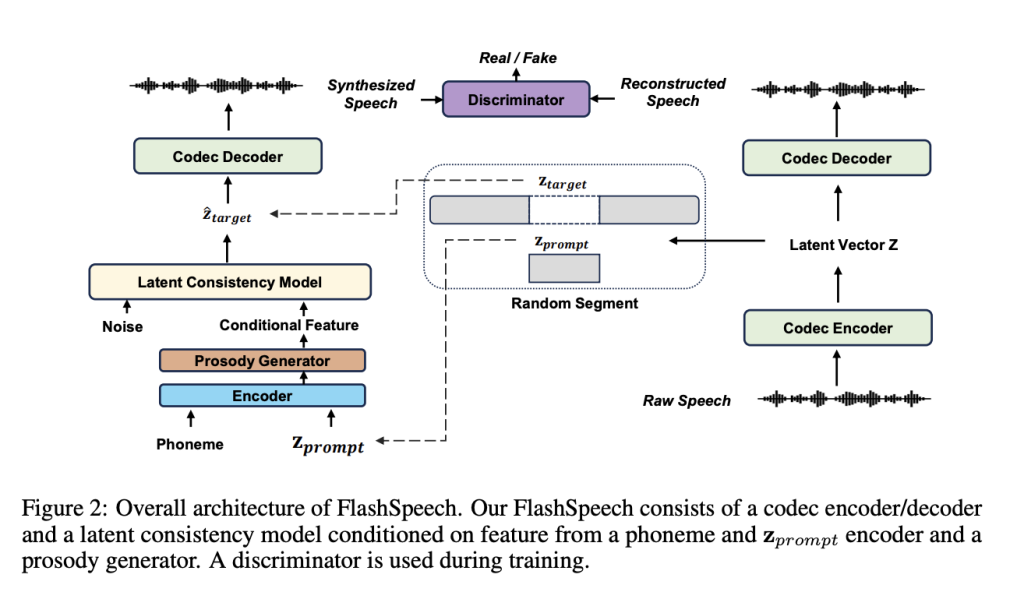
To tackle the challenge of slow generation speed while upholding high-quality speech synthesis, a team of researchers has introduced FlashSpeech as a groundbreaking stride towards efficient zero-shot speech synthesis. This novel approach builds upon recent advancements in generative models, particularly the latent consistency model (LCM), which paves a promising path for accelerating inference speed.
FlashSpeech leverages the LCM and adopts the encoder of a neural audio codec to convert speech waveforms into latent vectors as the training target. To train the model efficiently, the researchers introduce adversarial consistency training, a novel technique that combines consistency and adversarial training using pre-trained speech-language models as discriminators.
One of FlashSpeech’s key components is the prosody generator module, which enhances the diversity of prosody while maintaining stability. By conditioning the LCM on prior vectors obtained from a phoneme encoder, a prompt encoder, and the prosody generator, FlashSpeech achieves more diverse expressions and prosody in the generated speech.
When it comes to performance, FlashSpeech not only surpasses strong baselines in audio quality but also matches them in speaker similarity. What’s truly remarkable is that it achieves this at a speed approximately 20 times faster than comparable systems, marking an unprecedented level of efficiency in zero-shot speech synthesis.
The introduction of FlashSpeech signifies a significant leap forward in the field of zero-shot speech synthesis. By addressing the core limitations of existing approaches and harnessing recent innovations in generative modeling, FlashSpeech presents a compelling solution for real-world applications that demand rapid and high-quality speech synthesis.
With its efficient generation speed and superior performance, FlashSpeech holds immense promise for a variety of applications, including virtual assistants, audio content creation, and accessibility tools. As the field continues to evolve, FlashSpeech sets a new standard for efficient and effective zero-shot speech synthesis systems.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post FlashSpeech: A Novel Speech Generation System that Significantly Reduces Computational Costs while Maintaining High-Quality Speech Output appeared first on MarkTechPost.