-
Top 5 Metaphysical Properties Of Silver You Should Know
Top 5 Metaphysical Properties Of Silver You Should Know Silver has been cherished for its beauty, but it also holds a deeper significance. Silver is prized for its metaphysical properties in addition to its use in jewelry. It has the spiritual properties of silver that connect us to higher realms. And let me tell you,… →

-
Comparison of extracorporeal shock wave therapy and high-intensity laser therapy in the treatment of calcaneal spur-related symptoms: clinical outcomes and functional improvement
CONCLUSION: ESWT and HILT are effective non-invasive options for treating calcaneal spur with ESWT providing slightly greater functional benefits. →

-
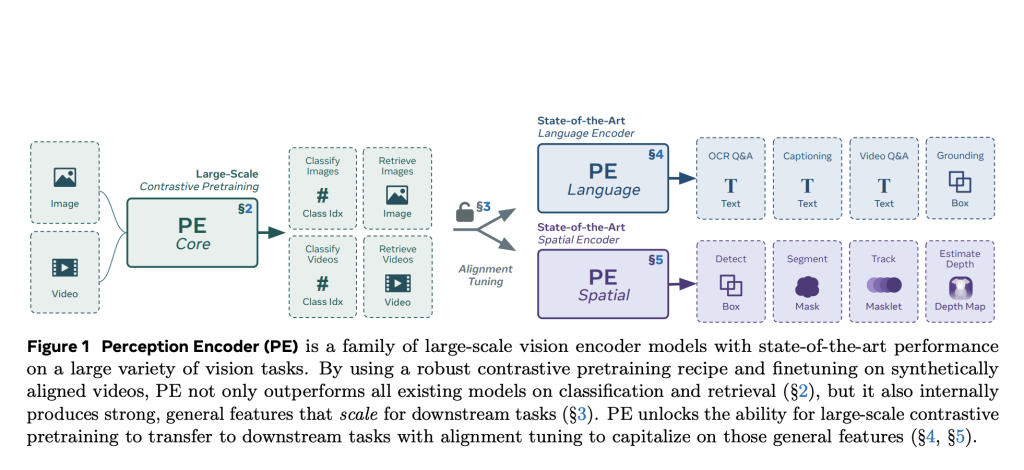
LLMs Can Now Solve Challenging Math Problems with Minimal Data: Researchers from UC Berkeley and Ai2 Unveil a Fine-Tuning Recipe…
LLMs Can Now Solve Challenging Math Problems with Minimal Data: Researchers from UC Berkeley and Ai2 Unveil a Fine-Tuning Recipe That Unlocks Mathematical Reasoning Across Difficulty Levels Language models have made significant strides in tackling reasoning tasks, with even small-scale supervised fine-tuning (SFT) approaches such as LIMO and s1 demonstrating remarkable improvements in mathematical problem-solving… →
-
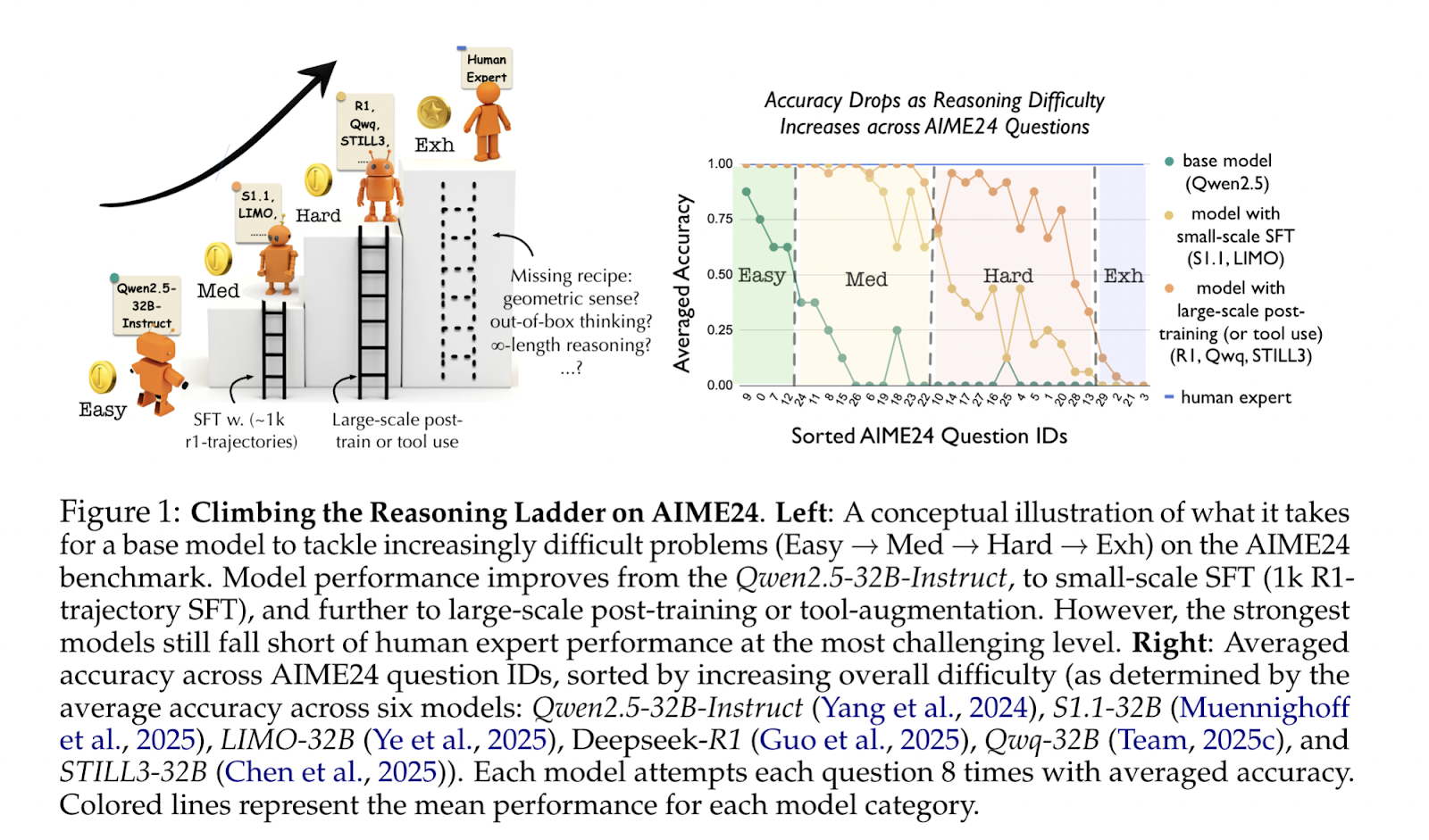
LLMs Can Now Learn to Try Again: Researchers from Menlo Introduce ReZero, a Reinforcement Learning Framework That Rewards Query …
LLMs Can Now Learn to Try Again: Researchers from Menlo Introduce ReZero, a Reinforcement Learning Framework That Rewards Query Retrying to Improve Search-Based Reasoning in RAG Systems The domain of LLMs has rapidly evolved to include tools that empower these models to integrate external knowledge into their reasoning processes. A significant advancement in this direction… →
-
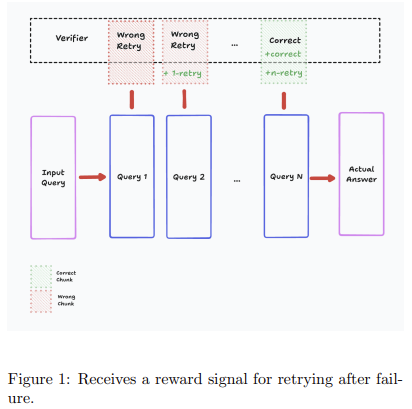
Meta AI Released the Perception Language Model (PLM): An Open and Reproducible Vision-Language Model to Tackle Challenging Visua…
Meta AI Released the Perception Language Model (PLM): An Open and Reproducible Vision-Language Model to Tackle Challenging Visual Recognition Tasks Despite rapid advances in vision-language modeling, much of the progress in this field has been shaped by models trained on proprietary datasets, often relying on distillation from closed-source systems. This reliance creates barriers to scientific… →
-
The New Rules of Brand Awareness in the AI Era
Hello and welcome to The GTM Newsletter by GTMnow – read by 50,000+ to scale their companies and careers. GTMnow shares insight around the go-to-market strategies responsible for explosive company growth. GTMnow highlights the strategies, along with the stories from the top 1% of GTM executives, VCs, and founders behind these strategies and companies. In… →

-
DataRobot vs H2O.ai: Predictive Modeling to Supercharge Product Insights
DataRobot automates predictive modeling for industries like insurance and marketing boosting profitability by providing accurate insights Reducing dependency on data scientists by 30% via AutoML cuts labor costs Equivalent products from the list include H2Oai or SAS Viya →

-
An In-Depth Guide to Firecrawl Playground: Exploring Scrape, Crawl, Map, and Extract Features for Smarter Web Data Extraction…
An In-Depth Guide to Firecrawl Playground: Exploring Scrape, Crawl, Map, and Extract Features for Smarter Web Data Extraction Web scraping and data extraction are crucial for transforming unstructured web content into actionable insights. Firecrawl Playground streamlines this process with a user-friendly interface, enabling developers and data practitioners to explore and preview API responses through various… →

-
Effect of Uncertainty-Aware AI Models on Pharmacists’ Reaction Time and Decision-Making in a Web-Based Mock Medication Verification Task: Randomized Controlled Trial
CONCLUSIONS: Pharmacists’ performance and reaction times varied by AI type and AI accuracy. Overall, uncertainty-aware AI resulted in faster decision-making and acted as a safeguard against bad AI advice to approve a misfilled medication. Conversely, black-box AI had the longest reaction times, and user performance degraded in the presence of bad AI advice. However, uncertainty-aware… →

-
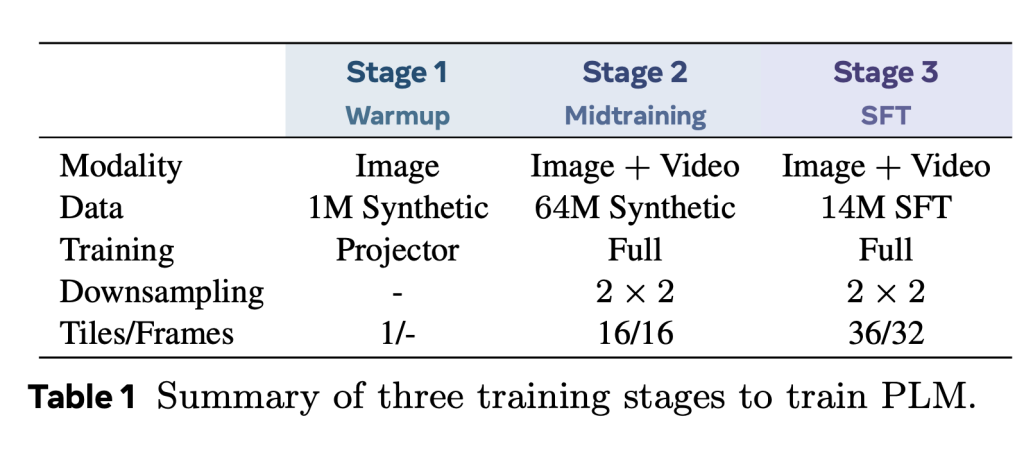
Meta AI Introduces Perception Encoder: A Large-Scale Vision Encoder that Excels Across Several Vision Tasks for Images and Video…
Meta AI Introduces Perception Encoder: A Large-Scale Vision Encoder that Excels Across Several Vision Tasks for Images and Video The Challenge of Designing General-Purpose Vision Encoders As AI systems grow increasingly multimodal, the role of visual perception models becomes more complex. Vision encoders are expected not only to recognize objects and scenes, but also to… →