As MLOps becomes an integral part of more businesses, the demand for professionals who can proficiently manage, deploy, and scale machine learning operations is growing rapidly.
This guide is for those who have experience in MLOps and are preparing for technical interviews aimed at mid-level to senior positions. It explores advanced interview questions deep into model governance, scalability, performance optimization, and regulatory compliance—areas where seasoned professionals can showcase their expertise. Through detailed explanations, strategic answer hints, and insightful discussions, this article will help you articulate your experiences and demonstrate your problem-solving skills effectively.
Let’s equip you with the knowledge to not only answer MLOps questions but to stand out in your next job interview.
Model Governance in MLOps
Question 1: How do you implement model governance in MLOps?
Model governance not only maintains control but also enhances reliability and trustworthiness of models in production. It’s crucial for managing risks related to data privacy and operational efficiency, and is a key skill for senior-level roles in MLOps, demonstrating both technical expertise and strategic oversight.
- Model Version Control: Use systems that track model versions along with their datasets and parameters to ensure transparency and allow for rollback if necessary.
- Audit Trails: Keep detailed logs of all model activities, including training and deployment, to aid in troubleshooting and meet regulatory compliance.
- Compliance and Standardization: Establish standards for model processes to adhere to internal and external regulatory requirements.
- Performance Monitoring: Set up ongoing monitoring of model performance to quickly address issues like model drift.

Answer Hints:
- Highlight tools like Kubeflow, for tracking experiments and managing deployments.
- Emphasize collaboration between data scientists, operations, and IT to ensure effective implementation of governance policies.
Handling Model Drift
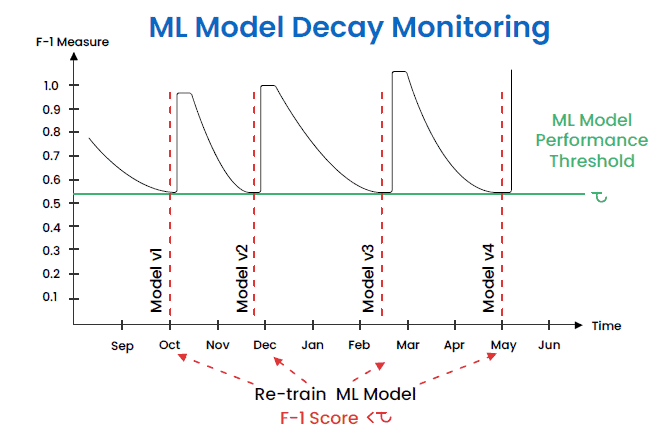
Question 2: What strategies do you use to handle model drift in production?
Addressing model drift is essential for maintaining the accuracy and relevance of models in dynamic environments. It showcases an MLOps professional’s ability to ensure long-term model performance and adaptability.
- Continuous Monitoring: Implement automated systems to regularly assess model performance and detect drift.
- Feedback Loops: Use real-time feedback from model outputs to quickly identify and address issues.
- Model Re-training: Schedule regular updates and re-train models with new data to maintain accuracy and relevance.
Answer Hints:
- Mention tools like Apache Kafka for real-time data streaming, monitoring, and alerting with Grafana.
- Discuss the role of A/B testing in evaluating model updates before full-scale deployment.
Scalability and Performance
Question 3: How do you ensure scalability and performance of machine learning models in a production environment?
Scalability and performance are crucial for supporting the growing needs of an organization and demonstrate an MLOps professional’s capability to manage and enhance machine learning infrastructure.
- Resource Management: Utilize dynamic resource allocation to efficiently handle varying loads.
- Load Balancing: Implement load balancing and multithreading to distribute data processing across multiple servers.
- Efficient Algorithms: Opt for algorithms and data structures that scale well with increased data.
Answer Hints:
- Discuss the use of containerization technologies like Docker and Kubernetes for scaling applications.
- Explain how cloud services can be leveraged for elastic scalability and performance optimization.
Latency vs. Throughput in MLOps
Question 4: Discuss the trade-offs between latency and throughput in MLOps.
Balancing latency and throughput is a critical aspect of optimizing machine learning models for production environments. Here’s how these factors play against each other:
- Latency: Refers to the time it takes for a single data point to be processed through the model. Lower latency is crucial for applications that require real-time decision-making, such as fraud detection or autonomous driving.
- Throughput: Measures how much data the system can process in a given time frame. Higher throughput with BigQuery platform is essential for applications needing to handle large volumes of data efficiently, like batch processing in data analytics.
Answer Hints:
- When optimizing for latency, consider techniques such as model simplification, using more efficient algorithms, or hardware acceleration.
- For throughput, strategies like lossless quantization,parallel processing, increasing hardware capacity, or optimizing data pipeline management can be effective.
Tools and Frameworks
Question 5: Compare and contrast different MLOps platforms you have used (e.g., Kubeflow, MLflow, TFX).
Effective use of MLOps platforms involves understanding their strengths and weaknesses in various scenarios. Key points include:
- Kubeflow: Best for end-to-end orchestration of machine learning pipelines on Kubernetes.
- MLflow: Strong for experiment tracking, model versioning, and serving.
- TFX: Ideal for integrating with TensorFlow, providing components for deploying production-ready ML pipelines.

Answer Hints:
- Highlight the integration capabilities of each platform with existing enterprise systems.
- Discuss the learning curve and community support associated with each tool.
Comparing MLOps Platforms
Question 6: Compare and contrast different MLOps platforms you have used (e.g., Kubeflow, MLflow, TFX).
Choosing the right MLOps platform is crucial for the efficient management of machine learning models from development to deployment. Here’s a comparison of three popular platforms:
- Kubeflow: Ideal for users deeply integrated into the Kubernetes ecosystem, Kubeflow offers robust tools for building and deploying scalable machine learning workflows.
- MLflow: Excelling in experiment tracking and model management, MLflow is versatile for managing the ML lifecycle, including model versioning and serving.
- TFX (TensorFlow Extended): Specifically designed to support TensorFlow models, TFX provides end-to-end components needed to deploy production-ready ML pipelines.
Answer Hints:
- Kubeflow is great for those who need tight integration with Kubernetes’ scaling and managing capabilities.
- MLflow’s flexibility makes it suitable for various environments, not tying the user to any particular ML library or framework.
- TFX offers comprehensive support for TensorFlow, making it the go-to for TensorFlow users looking for advanced pipeline capabilities.
Leveraging Apache Spark for MLOps
Question 7: How do you leverage distributed computing frameworks like Apache Spark for MLOps?
Apache Spark is a powerful tool for handling large-scale data processing, which is a cornerstone of effective MLOps practices. Here’s how Spark enhances MLOps:
- Data Processing at Scale: Spark’s ability to process large datasets quickly and efficiently is invaluable for training complex machine learning models that require handling vast amounts of data.
- Stream Processing: With Spark Streaming, you can develop and deploy real-time analytics solutions, crucial for models requiring continuous input and immediate response.
- Integration with ML Libraries: Spark integrates seamlessly with popular machine learning libraries like MLlib, providing a range of algorithms that are optimized for distributed environments.
Answer Hints:
- Emphasize Spark’s scalability, explaining how it supports both batch and stream processing, which can be crucial for deploying models that need to operate in dynamic environments.
- Discuss the benefit of Spark’s built-in MLlib for machine learning tasks, which simplifies the development of scalable ML models.
Security and Compliance
Question 8: How do you address security concerns when deploying ML models in production?
Addressing security in machine learning deployments involves several strategic measures:
- Data Encryption: Use encryption for data at rest and in transit to protect sensitive information.
- Access Controls: Implement strict access controls and authentication protocols to limit who can interact with the models and data.
- Regular Audits: Conduct regular security audits and vulnerability assessments to identify and mitigate risks.
Answer Hints:
- Mention tools like HashiCorp Vault for managing secrets and AWS Identity and Access Management (IAM) for access controls.
- Discuss the importance of adhering to security best practices and frameworks like the NIST cybersecurity framework.
Ensuring Compliance with Data Protection Regulations in MLOps
Question 9: Explain how you ensure compliance with data protection regulations (e.g., GDPR) in MLOps.
Ensuring compliance with data protection regulations like GDPR is crucial in MLOps to protect user data and avoid legal penalties. Here’s how this can be achieved:
- Data Anonymization and Encryption: Implement strong data anonymization techniques to redact personally identifiable information (PII) from datasets used in training and testing models. Use encryption to secure data at rest and in transit.
- Access Controls and Auditing: Establish strict access controls to ensure that only authorized personnel have access to sensitive data. Maintain comprehensive audit logs to track access and modifications to data, which is essential for compliance.
- Data Minimization and Retention Policies: Adhere to the principle of data minimization by collecting only the data necessary for specific purposes. Implement clear data retention policies to ensure data is not kept longer than necessary.
Answer Hints:
- Highlight the use of technologies like secure enclaves for processing sensitive data and tools like Databricks for implementing and enforcing data governance.
- Discuss the role of continuous monitoring and regular audits to ensure ongoing compliance with data protection laws.
Optimization and Automation
Question 10: What techniques do you use for hyperparameter optimization at scale?
Optimizing hyperparameters efficiently at scale requires advanced techniques:
- Grid Search and Random Search: For exhaustive or random exploration of parameter space.
- Bayesian Optimization: For smarter, probability-based exploration of parameter space, focusing on areas likely to yield improvements.
- Automated Machine Learning (AutoML): Utilizes algorithms to automatically test and adjust parameters to find optimal settings.
Answer Hints:
- Discuss the use of platforms like Google Cloud’s AI Platform or Azure Machine Learning for implementing these techniques at scale.
- Explain the trade-offs between computation time and model accuracy when choosing optimization methods.
Automating the ML Pipeline End-to-End
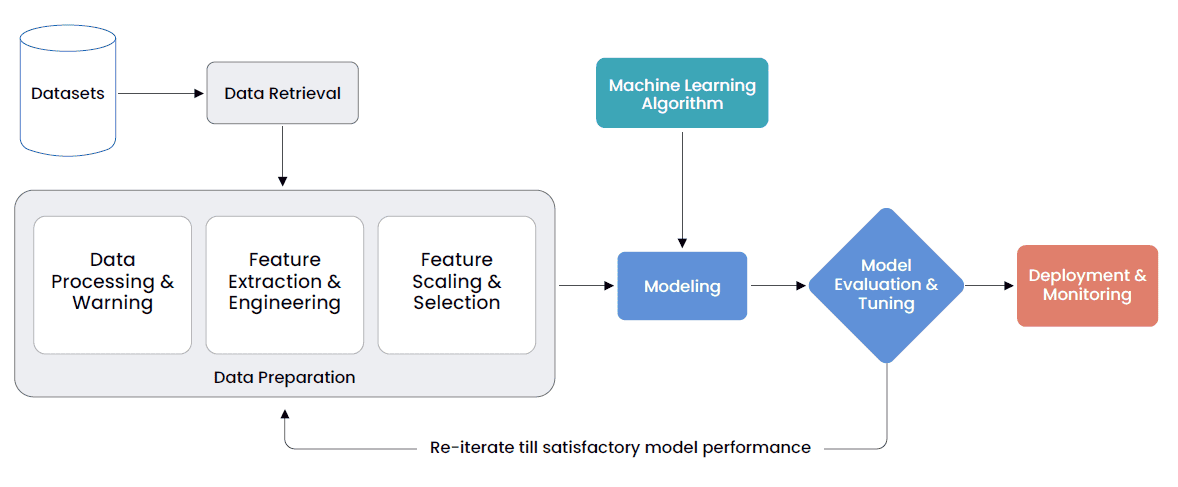
Question 11: Describe your approach to automating the ML pipeline end-to-end.
Automating the machine learning pipeline from data collection to model deployment is essential for improving efficiency and reducing errors in production environments. Here’s a structured approach:
- Data Collection and Preparation: Automate the ingestion and preprocessing of data using scripts or tools that clean, transform, and normalize data, preparing it for analysis and model training.
- Model Training and Evaluation: Use automated scripts or workflow orchestration tools to train models on prepared datasets. Automatically evaluate model performance using predefined metrics to ensure they meet the required standards before deployment.
- Model Deployment and Monitoring: Automate the deployment process through continuous integration and continuous deployment (CI/CD) pipelines. Implement automated monitoring to track model performance and health in real-time, triggering alerts for any significant deviations.
Answer Hints:
- Discuss the use of tools like Jenkins or GitLab for CI/CD, which streamline the deployment of machine learning models into production.
- Highlight the role of monitoring frameworks like Prometheus or custom dashboards in Kubernetes to oversee model performance continuously.
Case Studies and Real-World Scenarios
Question 12: Discuss a complex MLOps project you led. What were the challenges and how did you overcome them?
Sharing a real-world example can illustrate practical problem-solving:
- Scenario Description: Outline the project’s scope, objectives, and the specific MLOps challenges encountered.
- Solutions Implemented: Describe the strategies used to address challenges such as data heterogeneity, scalability issues, or model drift.
- Outcomes and Learnings: Highlight the results achieved and lessons learned from the project.
Answer Hints:
- Emphasize the collaborative aspect of the project, detailing how cross-functional team coordination was crucial.
- Discuss the iterative improvements made based on continuous feedback and monitoring.
Integrating A/B Testing and Continuous Experimentation in MLOps
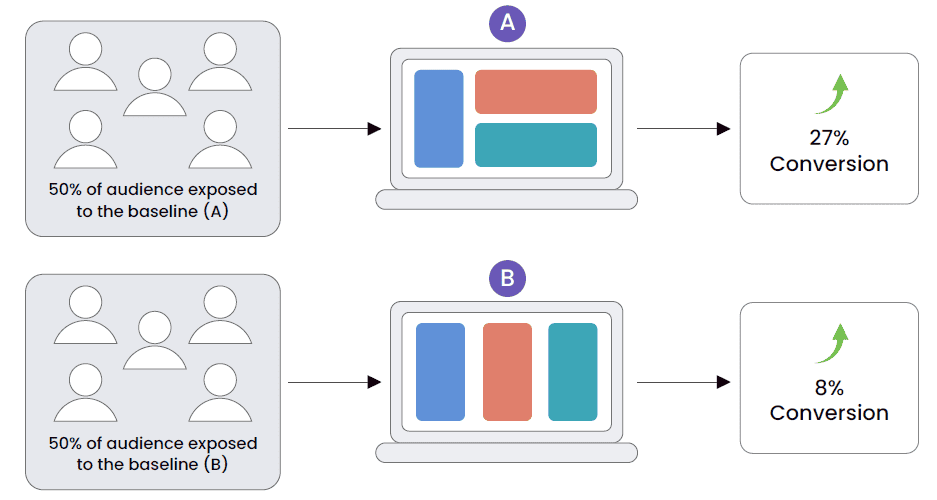
Question 13: How do you integrate A/B testing and continuous experimentation in MLOps?
Integrating A/B testing and continuous experimentation is crucial for optimizing and validating machine learning models in real-world settings. Here’s how this can be effectively implemented:
- Experiment Design: Start by clearly defining the objectives and hypotheses for the A/B tests. Determine what metrics will be used to measure success and how data will be split among different versions of the model.
- Implementation of Testing Framework: Use a robust platform that supports A/B testing and can route traffic between different model versions without disrupting user experience. Tools like TensorFlow Extended (TFX) or Kubeflow can manage deployments and experimentations seamlessly.
- Data Collection and Analysis: Ensure that data collected during the tests is clean and reliable. Analyze the performance of each model variant based on predefined metrics, using statistical tools to determine significant differences and make informed decisions.
- Iterative Improvements: Based on the results of A/B testing, continuously refine and retest models. Use insights from testing to enhance features, tune hyperparameters, or redesign parts of the model.
Answer Hints:
- Discuss the importance of using controlled environments and phased rollouts to minimize risks during testing.
- Mention the integration of continuous integration/continuous deployment (CI/CD) pipelines with A/B testing tools to automate the deployment and rollback of different model versions based on test results.
Best Practices and Trends
Question 14: What are the emerging trends in MLOps and how are you preparing for them?
Staying current with MLOps trends is key to advancing in the field:
- Automation and AI Operations: Increased use of automation in deploying and monitoring machine learning models.
- Federated Learning: This approach to training algorithms across multiple decentralized devices or servers ensures privacy and reduces data centralization risks.
- MLOps as a Service (MLOpsaaS): Rising popularity of cloud-based MLOps solutions, offering scalable and flexible model management.
Answer Hints:
- Highlight your ongoing education and training, such as participating in workshops and following industry leaders.
- Discuss how you incorporate these trends into your current projects or plans, demonstrating proactive adaptation.
Advance Your Career with OpenCV University
OpenCV University offers courses tailored for technology enthusiasts at every level:
FREE Courses:
OpenCV Bootcamp
TensorFlow Bootcamp
PREMIUM Courses: Take your expertise further with our specialized courses, offering in-depth training in cutting-edge areas. These are designed for individuals aiming to lead in their fields.
Our Computer Vision Master Bundle is the world’s most comprehensive curation of beginner to expert-level courses in Computer Vision, Deep Learning, and AI.
The post Advanced MLOps Interview Guide: Mastering Key Concepts for Technical Success appeared first on OpenCV.