In an increasingly interconnected world, understanding and making sense of different types of information simultaneously is crucial for the next wave of AI development. Traditional AI models often struggle with integrating information across multiple data modalities—primarily text and images—to create a unified representation that captures the best of both worlds. In practice, this means that understanding an article with accompanying diagrams or memes that convey information through both text and images can be quite difficult for an AI. This limited ability to understand these complex relationships constrains the capabilities of applications in search, recommendation systems, and content moderation.
Cohere has officially launched Multimodal Embed 3, an AI model designed to bring the power of language and visual data together to create a unified, rich embedding. The release of Multimodal Embed 3 comes as part of Cohere’s broader mission to make language AI accessible while enhancing its capabilities to work across different modalities. This model represents a significant step forward from its predecessors by effectively linking visual and textual data in a way that facilitates richer, more intuitive data representations. By embedding text and image inputs into the same space, Multimodal Embed 3 enables a host of applications where understanding the interplay between these types of data is critical.
The technical underpinnings of Multimodal Embed 3 reveal its promise for solving representation problems across diverse data types. Built on advancements in large-scale contrastive learning, Multimodal Embed 3 is trained using billions of paired text and image samples, allowing it to derive meaningful relationships between visual elements and their linguistic counterparts. One key feature of this model is its ability to embed both image and text into the same vector space, making similarity searches or comparisons between text and image data computationally straightforward. For example, searching for an image based on a textual description or finding similar textual captions for an image can be performed with remarkable precision. The embeddings are highly dense, ensuring that the representations are effective even for complex, nuanced content. Moreover, the architecture of Multimodal Embed 3 has been optimized for scalability, ensuring that even large datasets can be processed efficiently to provide fast, relevant responses for applications in content recommendation, image captioning, and visual question answering.

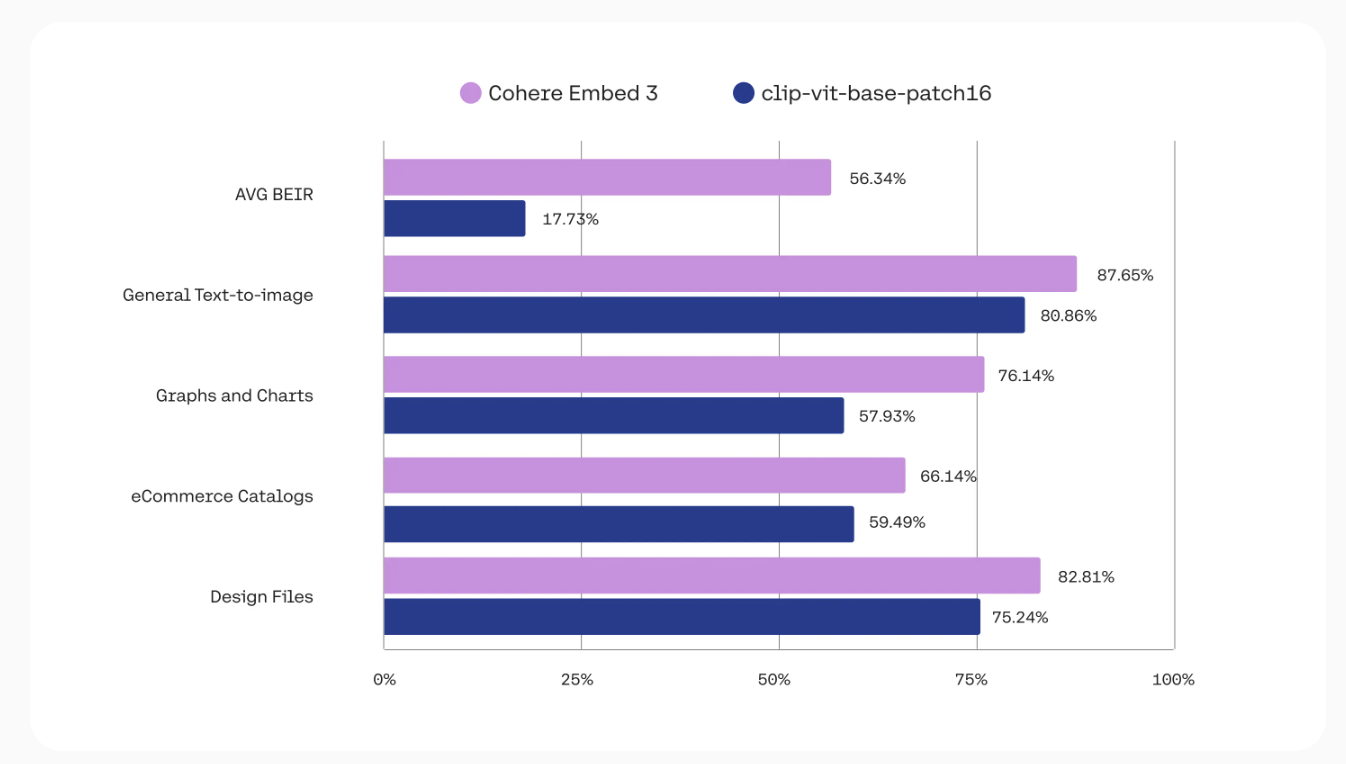
There are several reasons why Cohere’s Multimodal Embed 3 is a major milestone in the AI landscape. Firstly, its ability to generate unified representations from images and text makes it ideal for improving a wide range of applications, from enhancing search engines to enabling more accurate recommendation systems. Imagine a search engine capable of not just recognizing keywords but also truly understanding images associated with those keywords—this is what Multimodal Embed 3 enables. According to Cohere, this model delivers state-of-the-art performance across multiple benchmarks, including improvements in cross-modal retrieval accuracy. These capabilities translate into real-world gains for businesses that rely on AI-driven tools for content management, advertising, and user engagement. Multimodal Embed 3 not only improves accuracy but also introduces computation efficiencies that make deployment more cost-effective. The ability to handle nuanced, cross-modal interactions means fewer mismatches in recommended content, leading to better user satisfaction metrics and, ultimately, higher engagement.

In conclusion, Cohere’s Multimodal Embed 3 marks a significant step forward in the ongoing quest to unify AI understanding across different modalities of data. Bridging the gap between images and text provides a robust and efficient mechanism for integrating and processing diverse information sources in a unified way. This innovation has important implications for improving everything from search and recommendation engines to social media moderation and educational tools. As the need for more context-aware, multimodal AI applications grows, Cohere’s Multimodal Embed 3 paves the way for richer, more interconnected AI experiences that can understand and act on information in a more human-like manner. It’s a leap forward for the industry, bringing us closer to AI systems that can genuinely comprehend the world as we do—through a blend of text, visuals, and context.
Check out the Details. Embed 3 with new image search capabilities is available today on Cohere’s platform and on Amazon SageMaker. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Cohere Releases Multimodal Embed 3: A State-of-the-Art Multimodal AI Search Model Unlocking Real Business Value for Image Data appeared first on MarkTechPost.