
Speech recognition technology has become crucial in various modern applications, particularly real-time transcription and voice-activated command systems. It is essential in accessibility tools for individuals with hearing impairments, real-time captions during presentations, and voice-based controls in smart devices. These applications require immediate, precise feedback, often on devices with limited computing power. As these technologies expand into smaller and more cost-effective hardware, the need for efficient and fast speech recognition systems becomes even more critical. Devices that operate without a stable internet connection face additional challenges, making it necessary to develop solutions that can function well in such constrained environments.
One of the primary challenges in real-time speech recognition is reducing latency, the delay between spoken words and their transcription. Traditional models need help to balance speed with accuracy, especially in environments with limited computational resources. For applications that demand near-instantaneous results, any delay in transcription can significantly hamper user experience. Moreover, many existing systems process audio in fixed-length chunks, regardless of the actual length of speech, leading to unnecessary computational work. While functional for long audio segments, this approach results in inefficiencies when dealing with shorter or varied-length inputs, creating unnecessary delays and reducing performance.
Due to its accuracy, OpenAI’s Whisper has been a go-to model for general-purpose speech recognition. However, it employs a fixed-length encoder that processes audio in 30-second chunks, necessitating zero-padding for shorter sequences. This padding creates a constant computational overhead, even when the audio input is much shorter, increasing the overall processing time and lowering efficiency. Despite Whisper’s high accuracy, especially for long-form transcription, it struggles to meet the low-latency demands of on-device applications where real-time feedback is crucial.
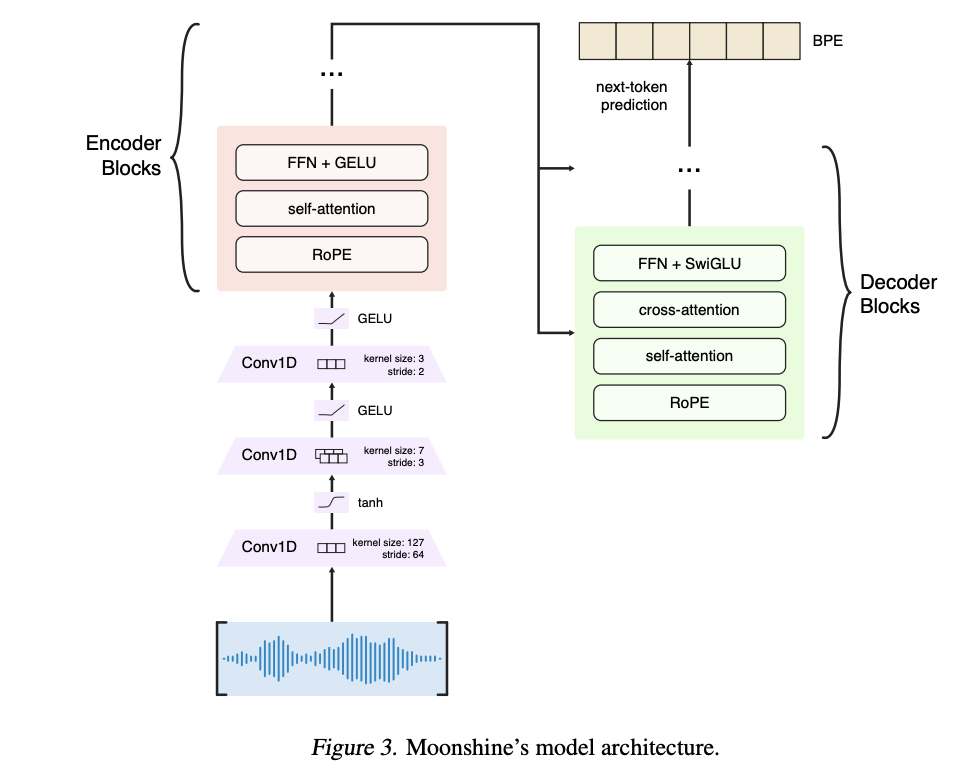
Researchers at Useful Sensors have introduced the Moonshine family of speech recognition models to tackle these inefficiencies. The Moonshine models employ a variable-length encoder that scales computational processing to the actual length of the audio input, thereby avoiding the need for zero-padding. This breakthrough allows the models to perform faster and more efficiently, especially in resource-constrained environments like low-cost devices. Moonshine is designed to match Whisper’s high transcription accuracy but with significantly reduced computational demand, making it a more suitable option for real-time transcription tasks. By employing advanced technologies like Rotary Position Embedding (RoPE), the model ensures that each speech segment is handled efficiently, improving overall performance.
The core architecture of Moonshine is based on an encoder-decoder transformer model that eliminates traditional hand-engineered features like Mel spectrograms. Instead, Moonshine directly processes raw audio inputs, using three convolution layers to compress the audio by a factor of 384x, compared to Whisper’s 320x compression. Also, Moonshine is trained on a comprehensive dataset of over 90,000 hours from publicly available ASR datasets and an additional 100,000 hours from the researchers’ dataset, amounting to 200,000 hours of training data. This vast and diverse dataset enables Moonshine to handle various audio inputs, from varying lengths to diverse accents, with improved accuracy.
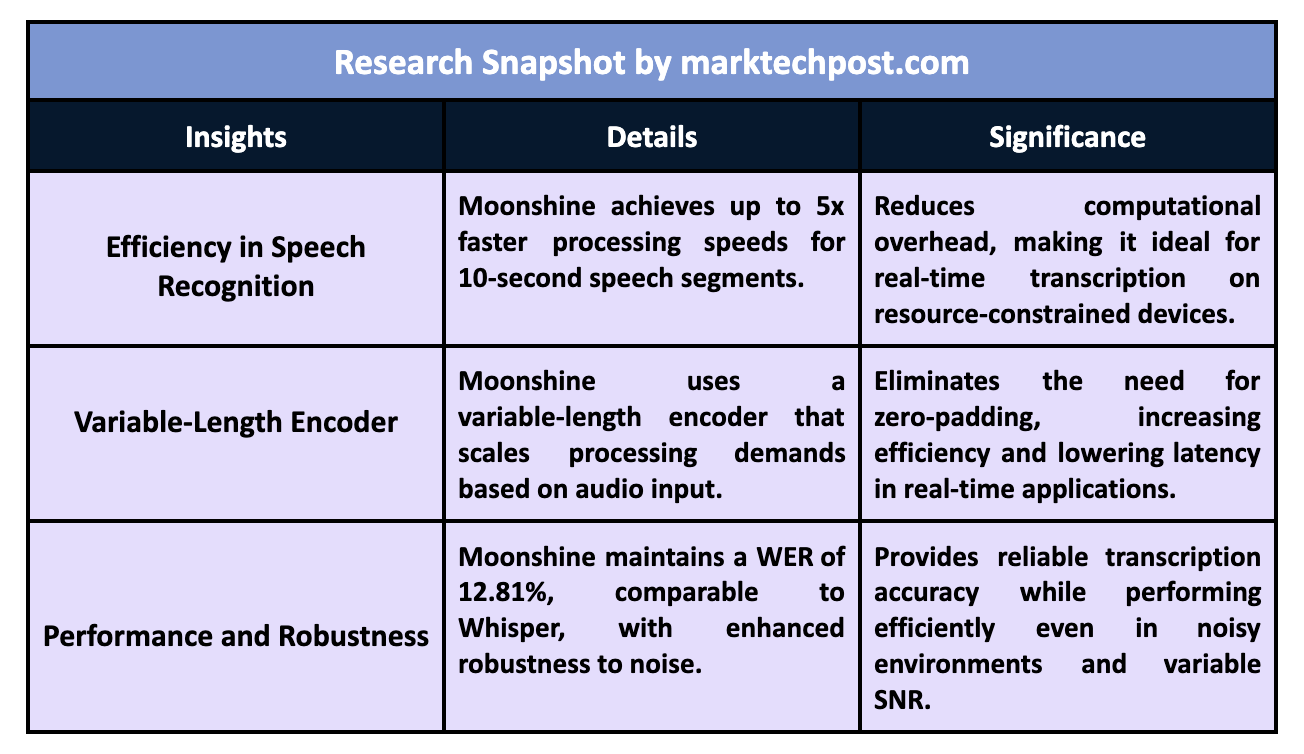
When tested against OpenAI’s Whisper, the results demonstrated that Moonshine achieves up to five times faster processing speeds for 10-second speech segments without an increase in word error rates (WER). For example, Moonshine Tiny, the smallest model in the family, demonstrated a fivefold reduction in computational requirements compared to Whisper Tiny while maintaining similar WER scores. Regarding specific benchmarks, Moonshine models outperformed Whisper in most datasets, including LibriSpeech, TEDLIUM, and GigaSpeech, with lower WER across different audio durations. Moonshine Tiny achieved an average WER of 12.81%, while Whisper Tiny had a WER of 12.66%. Although the two models performed similarly, Moonshine’s advantage lies in its processing speed and scalability for shorter inputs.
The researchers also highlighted Moonshine’s performance in noisy environments. When evaluated against audio with varying signal-to-noise ratios (SNR), such as the background noise from a computer fan, Moonshine maintained superior transcription accuracy at lower SNR levels. Its robustness to noise, combined with its ability to handle variable-length inputs efficiently, makes Moonshine an ideal solution for real-time applications that demand high performance even in less-than-ideal conditions.
Key Takeaways from the research on Moonshine:
- Moonshine models achieve up to 5x faster processing speeds than Whisper models for 10-second speech segments.
- The variable-length encoder eliminates the need for zero-padding, reducing computational overhead.
- Moonshine is trained on 200,000 hours of data, including open and internally collected data.
- The smallest Moonshine model (Tiny) maintains an average WER of 12.81% across various datasets, comparable to Whisper Tiny’s 12.66%.
- Moonshine models demonstrate superior robustness to noise and varying SNR levels, making them ideal for real-time applications on resource-constrained devices.
In conclusion, the research team addressed a significant challenge in real-time speech recognition: reducing latency while maintaining accuracy. The Moonshine models provide a highly efficient alternative to traditional ASR models like Whisper by using a variable-length encoder that scales with the length of the audio input. This innovation results in faster processing speeds, reduced computational demands, and comparable accuracy, making Moonshine an ideal solution for low-resource environments. By training on an extensive dataset and using cutting-edge transformer architecture, the researchers have developed a family of models that are highly applicable to real-world speech recognition tasks, from live transcription to smart device integration.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Moonshine: A Fast, Accurate, and Lightweight Speech-to-Text Models for Transcription and Voice Command Processing on Edge Devices appeared first on MarkTechPost.