
Evaluating NLP models has become increasingly complex due to issues like benchmark saturation, data contamination, and the variability in test quality. As interest in language generation grows, standard model benchmarking faces challenges from rapidly saturated evaluation datasets, where top models reach near-human performance levels. Creating new, high-quality datasets is resource-intensive, demanding human annotation, data cleaning, and validation. Additionally, with the rise of text-generation systems, ensuring that evaluation data is purely human-made is more difficult. One solution is dataset filtering, which can revitalize existing benchmarks, offering a practical alternative to creating entirely new evaluation sets.
Recent benchmark datasets, like MMLU, GSM8K, MATH, and GPQA, were developed to assess language model capabilities. Yet, concerns about their reliability have emerged due to issues like annotation errors and sensitivity to answer order. Some studies reveal that models may perform well due to biases, such as favoring certain answer choices or succeeding with answer-only prompts, raising concerns about data contamination and benchmark validity. Filtering easier examples from datasets is one proposed solution. Unlike past methods that required retraining and human verification, this approach efficiently identifies high-quality subsets, improving reliability without intensive computational or human resources.
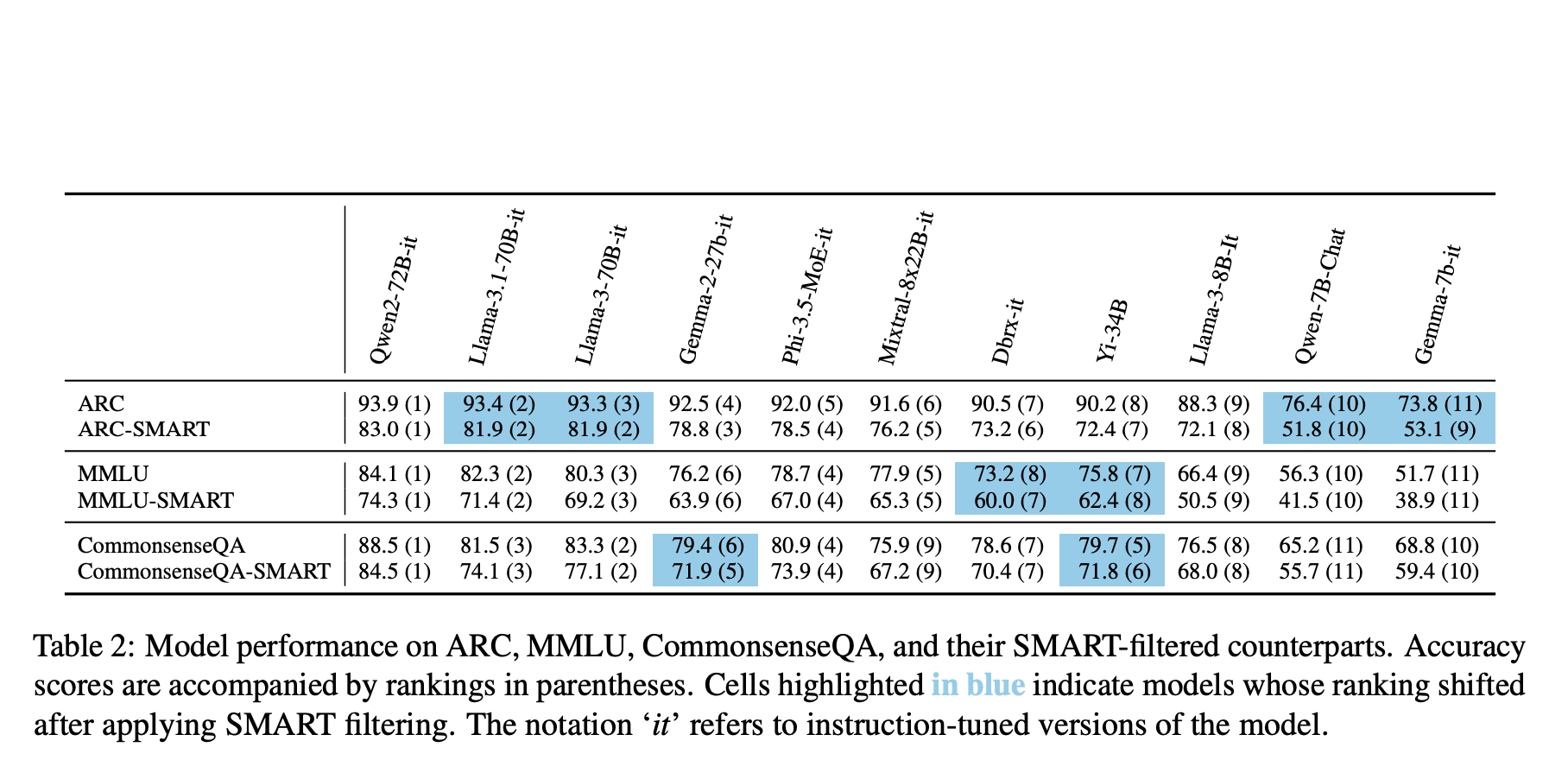
Researchers from Meta AI, Pennsylvania State University, and UC Berkeley introduced SMART filtering, a method for refining benchmark datasets by removing overly easy, contaminated, or too similar examples. This filtering process identifies a high-quality subset without human oversight, aiming to make benchmarks more informative and efficient. Tested on datasets like ARC, MMLU, and CommonsenseQA, SMART filtering reduced dataset size by 48% on average while maintaining or improving model ranking consistency. By increasing alignment with human evaluations from ChatBot Arena, SMART filtering proves useful for revitalizing older benchmarks and enhancing new datasets before they are standardized.
The SMART filtering method employs three independent steps to refine NLP datasets for more efficient model benchmarking. First, “easy” examples—which top models consistently answer correctly with high confidence—are removed, as they add little value for distinguishing model performance. Second, potentially “data-contaminated” examples, likely seen during model training, are filtered by testing models on answers alone without the question context. Lastly, highly similar examples are identified and deduplicated using embeddings, helping to reduce redundancy. These steps enhance the dataset’s challenge level and reduce computation costs while preserving valuable benchmarking insights.
The study applies SMART filtering to improve efficiency across multiple-choice question-answering datasets like ARC, MMLU, and CommonsenseQA. By testing seven top open-source models, SMART filtering identified low-quality data, reducing ARC size by up to 68.9% while maintaining model rankings. For example, 64.4% of ARC and 4.37% of MMLU were either “easy” or contaminated, respectively. Model agreement decreased, enhancing model differentiation. SMART filtering also correlated highly with ChatBot Arena’s human preference-based model scores, further validating its effectiveness. Additionally, results are robust, as varying models and embedding methods achieved similar outcomes.
The SMART filtering method enhances dataset quality by removing easy, contaminated, and similar examples, which can be applied pre- or post-release and iteratively for adapting to new models. This approach reduces computational demands, cutting evaluation costs by up to 68.9% for ARC while preserving model ranking. Additionally, SMART filtering correlates well with real-world performance metrics like ChatBot Arena scores. Notably, model accuracy declines on filtered datasets, suggesting benchmarks still need to be saturated. Though promising, this method may require adjustments for non-QA datasets and improved strategies for addressing annotation errors.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post SMART Filtering: Enhancing Benchmark Quality and Efficiency for NLP Model Evaluation appeared first on MarkTechPost.