
Language models (LMs) are widely utilized across domains like mathematics, coding, and reasoning to handle complex tasks. These models rely on deep learning techniques to generate high-quality outputs, but their performance can vary significantly depending on the complexity of the input. While some queries are simple and require minimal computation, others are far more complex, requiring significant computational resources to achieve optimal results. The challenge lies in efficiently allocating computational power to different tasks without overloading the system.
One of the major issues in the current approach to language models is that they use a fixed computational procedure for every input, regardless of the difficulty. This approach wastes resources on simpler tasks while under-allocating computational effort to more complex queries. As a result, there is a need for an adaptive system that can adjust the computation based on the problem’s complexity, thus improving efficiency while maintaining output quality.
Several existing methods have been developed to handle the issue of computation allocation in language models. For instance, the best-of-k sampling method generates multiple samples for each input and selects the best one based on reranking models. Another common method involves expensive decoding techniques, such as chain-of-thought reasoning, which helps LMs produce better responses. However, these approaches apply the same level of computation to every query, which leads to inefficiency when dealing with diverse tasks with varying difficulty levels.
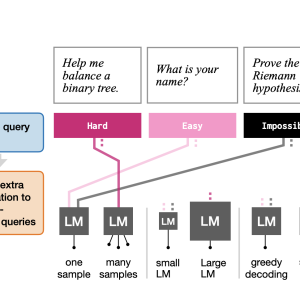
Researchers from the Massachusetts Institute of Technology (MIT) introduced an innovative AI approach to address this problem by adapting the computation allocation based on input complexity. The proposed method allows the LM to predict how much computation is needed for a particular input and allocate computational resources accordingly. This solution employs two main techniques: adaptive best-of-k sampling and a query-routing method. These techniques ensure that simpler queries receive minimal computation while complex ones receive the resources for high-quality responses.
In greater detail, the adaptive best-of-k sampling method involves generating a flexible number of samples for each query. Instead of assigning a fixed number of samples, as is done in standard methods, this adaptive approach dynamically selects how many samples should be generated based on the estimated difficulty of the query. The research team also introduced a routing method, where the model can decide to process the query through a less powerful but cheaper LM or a more powerful but expensive LM, depending on the difficult query. The adaptive system uses lightweight probes on top of pre-trained models to assess the complexity of the input and adjust the resources accordingly.
The adaptive computation framework was tested on various programming, mathematics, and dialog tasks to assess its effectiveness. Across these domains, the researchers achieved significant improvements. For instance, the adaptive best-of-k sampling method was shown to reduce computation by up to 50% in mathematics and coding tasks while maintaining the same level of accuracy as non-adaptive methods. In dialog-based tasks, the adaptive system reduced computation by up to 10% while matching the quality of responses generated by conventional methods. Furthermore, in certain routing experiments, the system achieved the same performance as more expensive decoding models, even though it used them only 50% to 75% of the time.
The research results provide concrete evidence that adaptive computation can significantly enhance the efficiency of language models. In coding tasks, for instance, adaptive sampling delivered the same performance as traditional methods, using 50% less computational power. The routing system matched the output of a more expensive decoding process for chat-based tasks but required only half of the computational resources. In cases where the system used weaker and stronger models, it could route complex queries to the stronger model while leaving simpler ones for the weaker, more efficient model. This strategy improved overall performance and reduced computational costs.
In conclusion, this research highlights a significant advancement in language model efficiency by introducing adaptive computation methods. The team from MIT successfully developed techniques that tailor computational resources to input difficulty, allowing for better allocation of resources. This approach addresses the inefficiency of current systems and provides a solution that balances performance with computational costs. By reducing computation by up to 50% without sacrificing output quality, this adaptive system sets a new standard for optimizing language models in various domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post This AI Paper by MIT Introduces Adaptive Computation for Efficient and Cost-Effective Language Models appeared first on MarkTechPost.