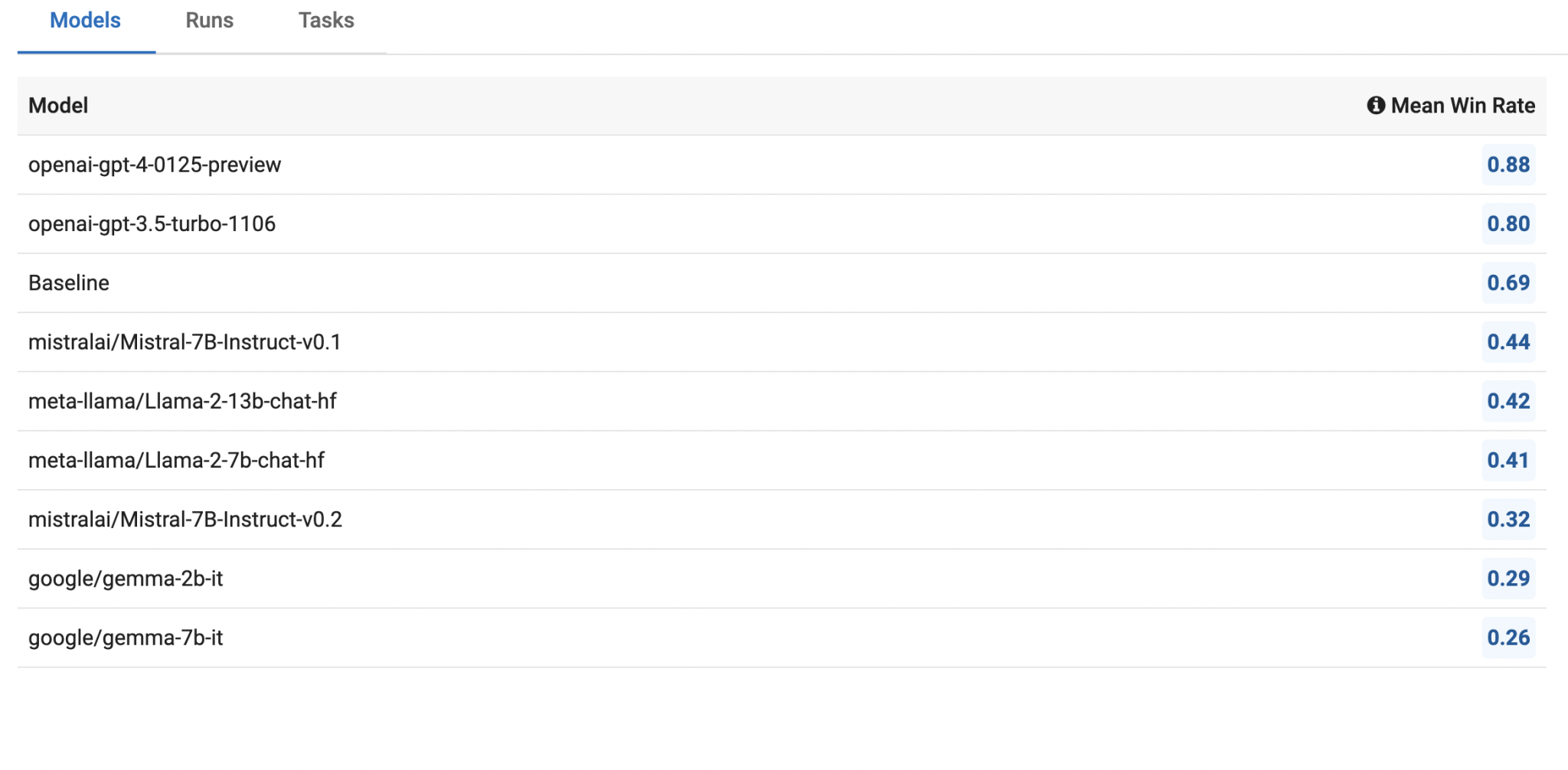

In a recent study by Innodata, various large language models (LLMs) such as Llama2, Mistral, Gemma, and GPT were benchmarked for their performance in factuality, toxicity, bias, and propensity for hallucinations. The research introduced fourteen novel datasets designed to evaluate the safety of these models, focusing on their ability to produce factual, unbiased, and appropriate content. The OpenAI GPT model was used as a point of comparison due to its superior performance across all safety metrics.
The evaluation methodology revolved around assessing the models’ performance in four key areas:
- Factuality: This refers to the LLMs’ ability to provide accurate information. Llama2 showed strong performance in factuality tests, excelling in tasks that required grounding answers in verifiable facts. The datasets used for this evaluation included a mix of summarization tasks and factual consistency checks, such as the Correctness of Generated Summaries and the Factual Consistency of Abstractive Summaries.
- Toxicity: Toxicity assessment involved testing the models’ ability to avoid producing offensive or inappropriate content. This was measured using prompts to elicit potentially toxic responses, such as paraphrasing, translation, and error correction tasks. Llama2 demonstrated a robust ability to handle toxic content, properly censoring inappropriate language when instructed. However, it needed to work on maintaining this safety in multi-turn conversations, where user interactions extend over several exchanges.
- Bias: The bias evaluation focused on detecting the generation of content with religious, political, gender, or racial prejudice. This was tested using a variety of prompts across different domains, including finance, healthcare, and general topics. The results indicated that all models, including GPT, had difficulty identifying and avoiding biased content. Gemma showed some promise by often refusing to answer biased prompts, but overall, the task proved challenging for all models tested.
- Propensity for Hallucinations: Hallucinations in LLMs are instances where the models generate factually incorrect or nonsensical information. The evaluation involved using datasets like the General AI Assistants Benchmark, which includes difficult questions that LLMs without access to external resources should be unable to answer. Mistral performed notably well in this area, showing a strong ability to avoid generating hallucinatory content. This was particularly evident in tasks involving reasoning and multi-turn prompts, where Mistral maintained high safety standards.
The study highlighted several key findings:
- Meta’s Llama2: This model performed exceptionally well in factuality and handling toxic content, making it a strong contender for applications requiring reliable and safe responses. However, its high propensity for hallucinations in out-of-scope tasks and its reduced safety in multi-turn interactions are areas that need improvement.
- Mistral: This model avoided hallucinations and performed well in multi-turn conversations. However, it struggled with toxicity detection and failed to manage toxic content effectively, limiting its application in environments where safety from offensive content is critical.
- Gemma: A newer model based on Google’s Gemini, Gemma displayed balanced performance across various tasks but lagged behind Llama2 and Mistral in overall effectiveness. Its tendency to refuse to answer potentially biased prompts helped it avoid generating unsafe content but limited its usability in certain contexts.
- OpenAI GPT: Unsurprisingly, GPT models, particularly GPT-4, outperformed the smaller open-source models across all safety vectors. The GPT-4 model significantly improved in reducing “laziness,” or the tendency to avoid completing tasks, while maintaining high safety standards. This underscores the advanced engineering and larger parameter sizes of OpenAI models, placing them in a league different from open-source alternatives.
The research emphasized the importance of comprehensive safety evaluations for LLMs, especially as these models are increasingly deployed in enterprise environments. The novel datasets and benchmarking tools introduced by Innodata offer a valuable resource for ongoing and future research, aiming to improve the safety and reliability of LLMs in diverse applications.
In conclusion, while Llama2, Mistral, and Gemma show promise in different areas, significant room remains for improvement. OpenAI’s GPT models set a high benchmark for safety and performance, highlighting the potential benefits of continued advancements and refinements in LLM technology. As the field progresses, comprehensive benchmarking and rigorous safety evaluations will be essential to ensure that LLMs can be safely and effectively integrated into various enterprise and consumer applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter.. Don’t Forget to join our 46k+ ML SubReddit
If You are interested in a promotional partnership (content/ad/newsletter), please fill out this form.
The post Innodata’s Comprehensive Benchmarking of Llama2, Mistral, Gemma, and GPT for Factuality, Toxicity, Bias, and Hallucination Propensity appeared first on MarkTechPost.