AI News
Category Added in a WPeMatico Campaign
-

RARE (Retrieval-Augmented Reasoning Modeling): A Scalable AI Framework for Domain-Specific Reasoning in Lightweight Language Mod…
RARE (Retrieval-Augmented Reasoning Modeling): A Scalable AI Framework for Domain-Specific Reasoning in Lightweight Language Models LLMs have demonstrated strong general-purpose performance across various tasks, including mathematical reasoning and automation. However, they struggle in domain-specific applications where specialized knowledge and nuanced reasoning are essential. These challenges arise primarily from the difficulty of accurately representing long-tail domain…
-

University of Michigan Researchers Introduce OceanSim: A High-Performance GPU-Accelerated Underwater Simulator for Advanced Mari…
University of Michigan Researchers Introduce OceanSim: A High-Performance GPU-Accelerated Underwater Simulator for Advanced Marine Robotics Marine robotic platforms support various applications, including marine exploration, underwater infrastructure inspection, and ocean environment monitoring. While reliable perception systems enable robots to sense their surroundings, detect objects, and navigate complex underwater terrains independently, developing these systems presents unique difficulties…
-

A Step-by-Step Coding Guide to Building a Gemini-Powered AI Startup Pitch Generator Using LiteLLM Framework, Gradio, and FPDF in…
A Step-by-Step Coding Guide to Building a Gemini-Powered AI Startup Pitch Generator Using LiteLLM Framework, Gradio, and FPDF in Google Colab with PDF Export Support In this tutorial, we built a powerful and interactive AI application that generates startup pitch ideas using Google’s Gemini Pro model through the versatile LiteLLM framework. is the backbone of…
-
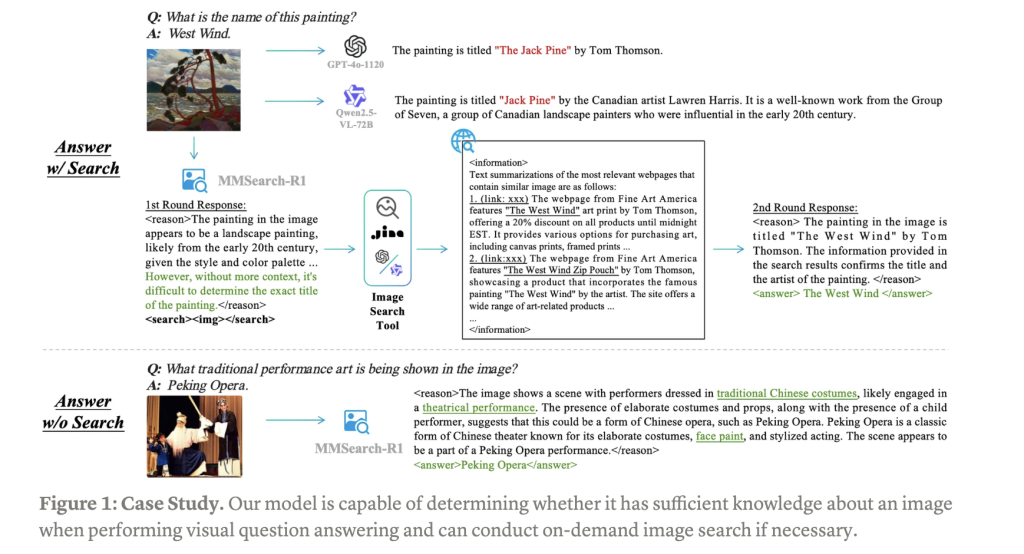
MMSearch-R1: End-to-End Reinforcement Learning for Active Image Search in LMMs
MMSearch-R1: End-to-End Reinforcement Learning for Active Image Search in LMMs Large Multimodal Models (LMMs) have demonstrated remarkable capabilities when trained on extensive visual-text paired data, advancing multimodal understanding tasks significantly. However, these models struggle with complex real-world knowledge, particularly long-tail information that emerges after training cutoffs or domain-specific knowledge restricted by privacy, copyright, or security…
-
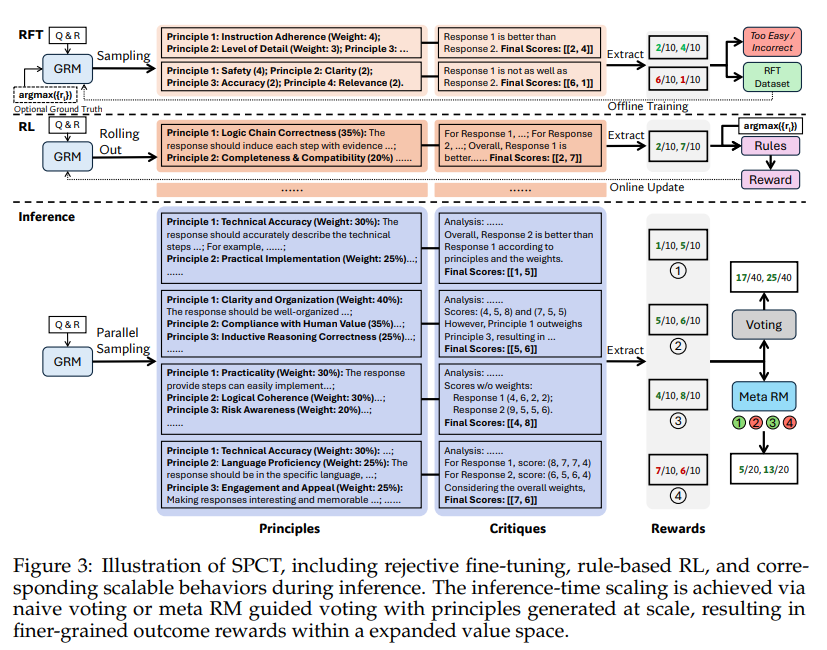
Scalable and Principled Reward Modeling for LLMs: Enhancing Generalist Reward Models RMs with SPCT and Inference-Time Optimizati…
Scalable and Principled Reward Modeling for LLMs: Enhancing Generalist Reward Models RMs with SPCT and Inference-Time Optimization Reinforcement Learning RL has become a widely used post-training method for LLMs, enhancing capabilities like human alignment, long-term reasoning, and adaptability. A major challenge, however, is generating accurate reward signals in broad, less structured domains, as current high-quality…
-
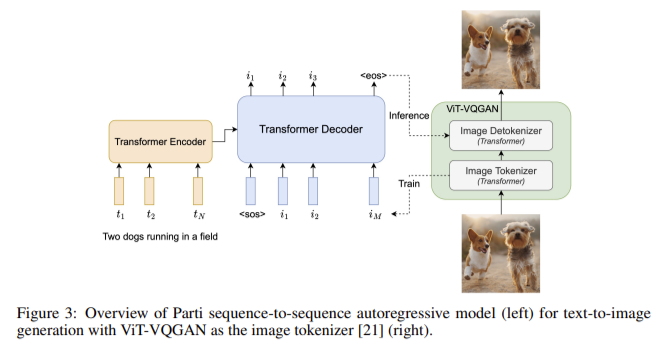
Transformer Meets Diffusion: How the Transfusion Architecture Empowers GPT-4o’s Creativity
Transformer Meets Diffusion: How the Transfusion Architecture Empowers GPT-4o’s Creativity OpenAI’s GPT-4o represents a new milestone in multimodal AI: a single model capable of generating fluent text and high-quality images in the same output sequence. Unlike previous systems (e.g., ChatGPT) that had to invoke an external image generator like DALL-E, GPT-4o produces images natively as…
-
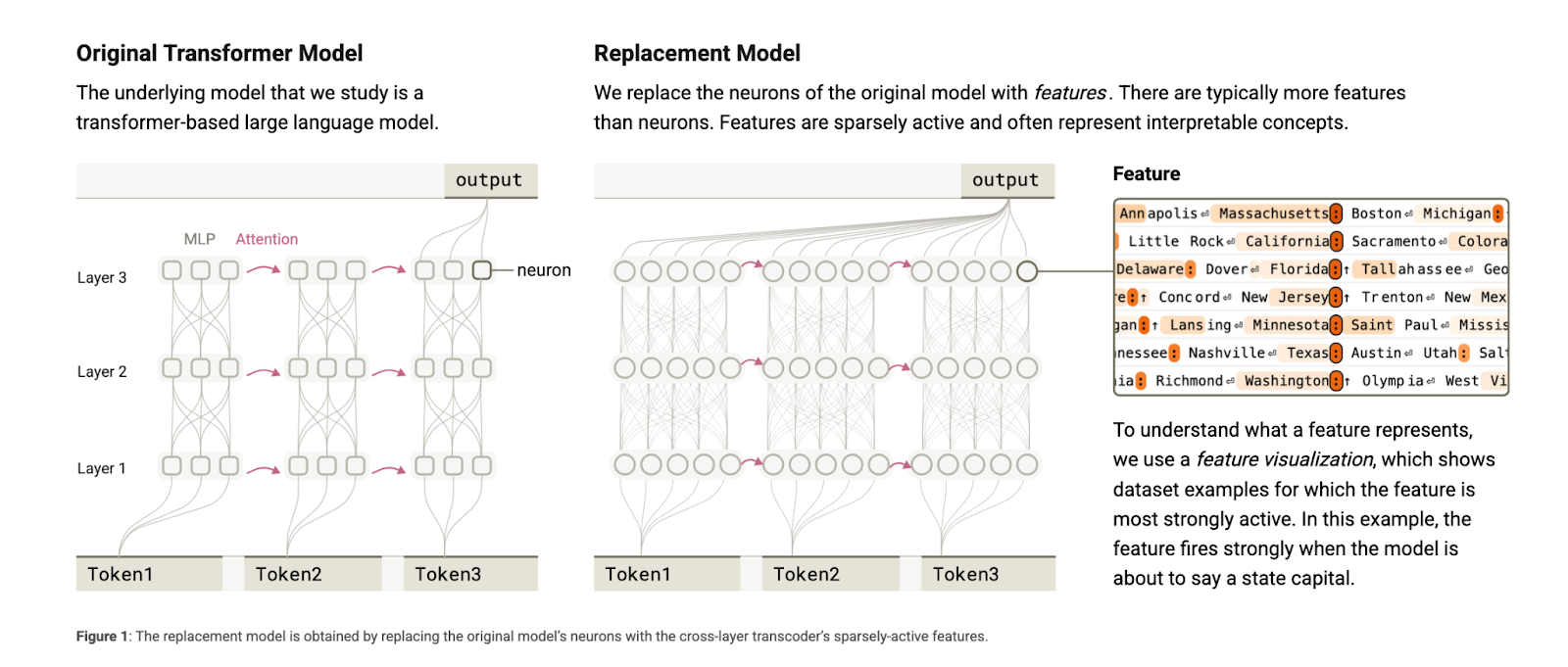
This AI Paper from Anthropic Introduces Attribution Graphs: A New Interpretability Method to Trace Internal Reasoning in Claude …
This AI Paper from Anthropic Introduces Attribution Graphs: A New Interpretability Method to Trace Internal Reasoning in Claude 3.5 Haiku While the outputs of large language models (LLMs) appear coherent and useful, the underlying mechanisms guiding these behaviors remain largely unknown. As these models are increasingly deployed in sensitive and high-stakes environments, it has become…
-
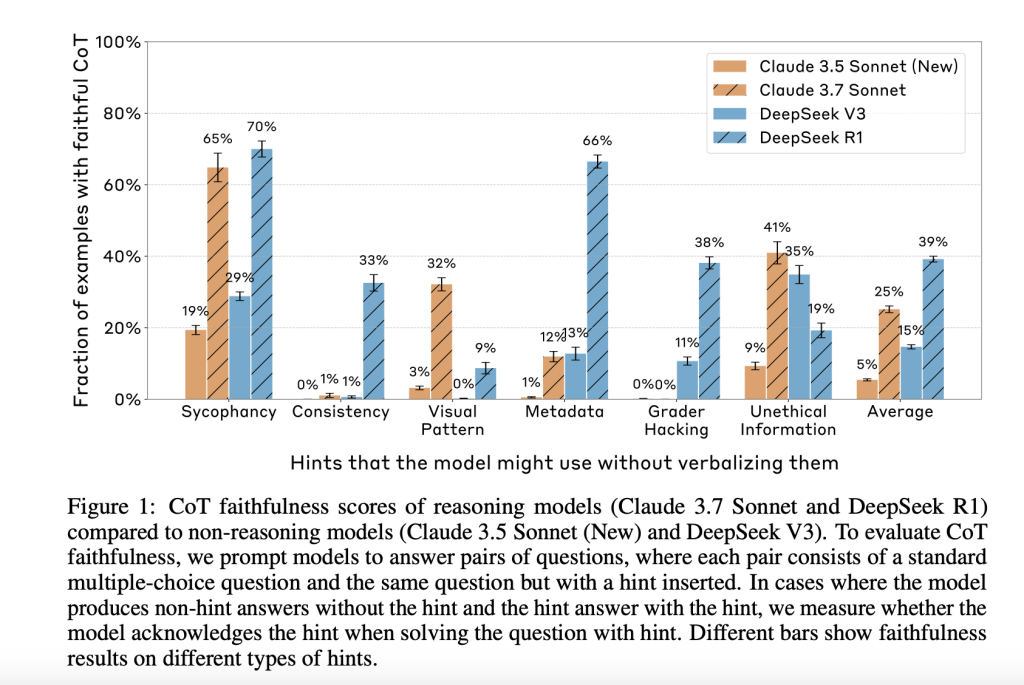
Anthropic’s Evaluation of Chain-of-Thought Faithfulness: Investigating Hidden Reasoning, Reward Hacks, and the Limitations of Ve…
Anthropic’s Evaluation of Chain-of-Thought Faithfulness: Investigating Hidden Reasoning, Reward Hacks, and the Limitations of Verbal AI Transparency in Reasoning Models A key advancement in AI capabilities is the development and use of chain-of-thought (CoT) reasoning, where models explain their steps before reaching an answer. This structured intermediate reasoning is not just a performance tool; it’s…
-
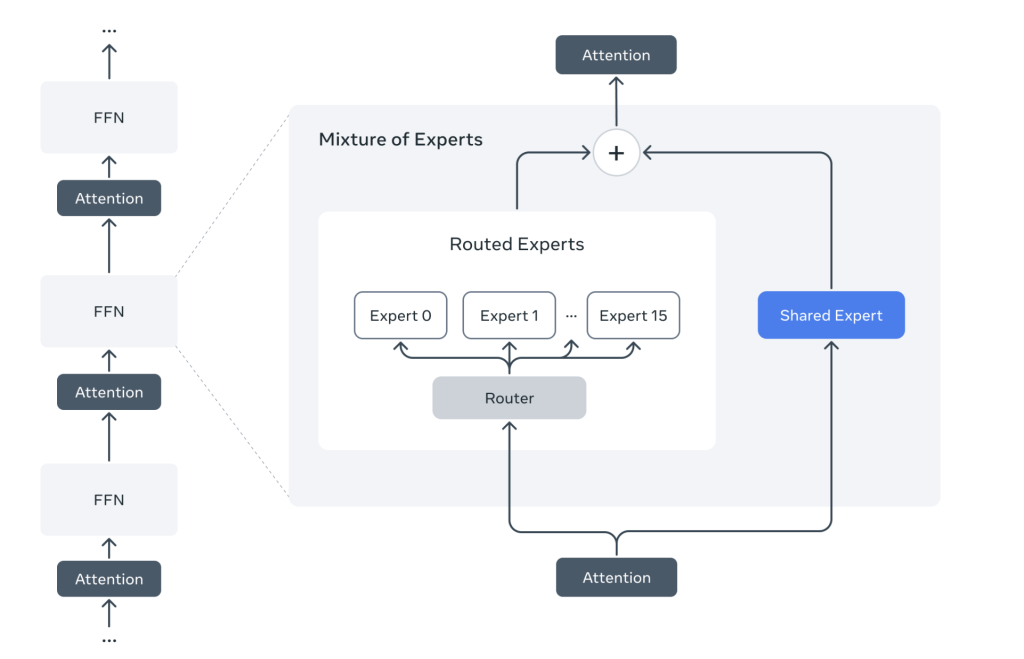
Meta AI Just Released Llama 4 Scout and Llama 4 Maverick: The First Set of Llama 4 Models
Meta AI Just Released Llama 4 Scout and Llama 4 Maverick: The First Set of Llama 4 Models Today, Meta AI announced the release of its latest generation multimodal models, Llama 4, featuring two variants: Llama 4 Scout and Llama 4 Maverick. These models represent significant technical advancements in multimodal AI, offering improved capabilities for…
-
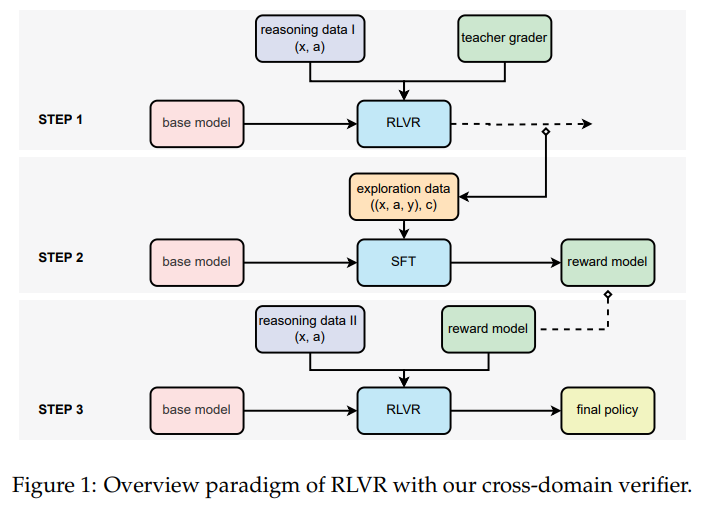
Scalable Reinforcement Learning with Verifiable Rewards: Generative Reward Modeling for Unstructured, Multi-Domain Tasks…
Scalable Reinforcement Learning with Verifiable Rewards: Generative Reward Modeling for Unstructured, Multi-Domain Tasks Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective in enhancing LLMs&; reasoning and coding abilities, particularly in domains where structured reference answers allow clear-cut verification. This approach relies on reference-based signals to determine if a model& response aligns with a known…