AI News
Category Added in a WPeMatico Campaign
-
Hugging Face Releases nanoVLM: A Pure PyTorch Library to Train a Vision-Language Model from Scratch in 750 Lines of Code
In a notable step toward democratizing vision-language model development, Hugging Face has released nanoVLM, a compact and educational PyTorch-based framework that allows researchers and developers to train a vision-language model (VLM) from scratch in just 750 lines of code. This release follows the spirit of projects like nanoGPT by Andrej Karpathy—prioritizing readability and modularity without…
-
NVIDIA Open-Sources Open Code Reasoning Models (32B, 14B, 7B)
NVIDIA continues to push the boundaries of open AI development by open-sourcing its Open Code Reasoning (OCR) model suite — a trio of high-performance large language models purpose-built for code reasoning and problem-solving. The 32B, 14B, and 7B variants, all released under the Apache 2.0 license. Benchmarked to Beat the Best The Open Code Reasoning…
-
This AI Paper Introduce WebThinker: A Deep Research Agent that Empowers Large Reasoning Models (LRMs) for Autonomous Search and Report Generation
Large reasoning models (LRMs) have shown impressive capabilities in mathematics, coding, and scientific reasoning. However, they face significant limitations when addressing complex information research needs when relying solely on internal knowledge. These models struggle with conducting thorough web information retrieval and generating accurate scientific reports through multi-step reasoning processes. So, the deep integration of LRM’s…
-
A Step-by-Step Guide to Implement Intelligent Request Routing with Claude
This article demonstrates how to build an intelligent routing system powered by Anthropic’s Claude models. This system improves response efficiency and quality by automatically classifying user requests and directing them to specialised handlers. The workflow analyses incoming queries, determines their intent, and routes them to appropriate processing pipelines—whether for customer support, technical assistance, or other…
-

How to Create a Custom Model Context Protocol (MCP) Client Using Gemini
How to Create a Custom Model Context Protocol (MCP) Client Using Gemini In this tutorial, we will be implementing a custom Model Context Protocol (MCP) Client using Gemini. By the end of this tutorial, you will be able to connect your own AI applications with MCP servers, unlocking powerful new capabilities to supercharge your projects.…
-

UniME: A Two-Stage Framework for Enhancing Multimodal Representation Learning with MLLMs
UniME: A Two-Stage Framework for Enhancing Multimodal Representation Learning with MLLMs The CLIP framework has become foundational in multimodal representation learning, particularly for tasks such as image-text retrieval. However, it faces several limitations: a strict 77-token cap on text input, a dual-encoder design that separates image and text processing, and a limited compositional understanding that…
-

ThinkPRM: A Generative Process Reward Models for Scalable Reasoning Verification
ThinkPRM: A Generative Process Reward Models for Scalable Reasoning Verification Reasoning with LLMs can benefit from utilizing more test compute, which depends on high-quality process reward models (PRMs) to select promising paths for search or ranking. PRMs score problem-solution pairs to indicate whether the solution is correct, and have been implemented as discriminative classifiers. However,…
-

A Coding Guide to Different Function Calling Methods to Create Real-Time, Tool-Enabled Conversational AI Agents…
A Coding Guide to Different Function Calling Methods to Create Real-Time, Tool-Enabled Conversational AI Agents Function calling lets an LLM act as a bridge between natural-language prompts and real-world code or APIs. Instead of simply generating text, the model decides when to invoke a predefined function, emits a structured JSON call with the function name…
-
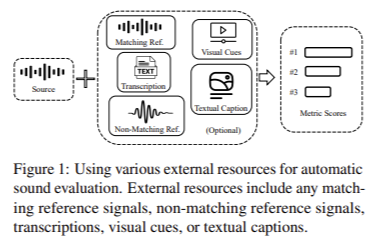
The WAVLab Team is Releases of VERSA: A Comprehensive and Versatile Evaluation Toolkit for Assessing Speech, Audio, and Music Si…
The WAVLab Team is Releases of VERSA: A Comprehensive and Versatile Evaluation Toolkit for Assessing Speech, Audio, and Music Signals AI models have made remarkable strides in generating speech, music, and other forms of audio content, expanding possibilities across communication, entertainment, and human-computer interaction. The ability to create human-like audio through deep generative models is no…
-
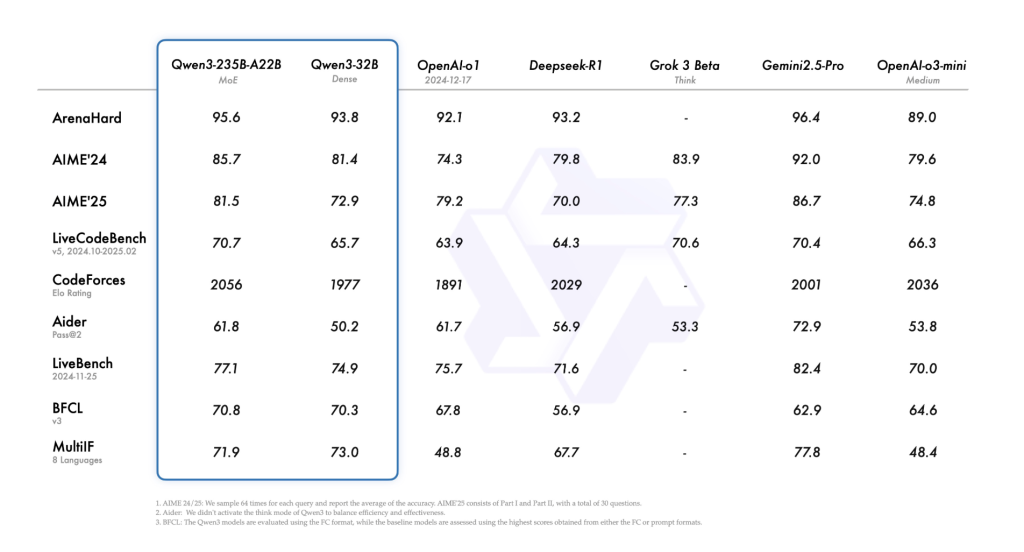
Alibaba Qwen Team Just Released Qwen3: The Latest Generation of Large Language Models in Qwen Series, Offering a Comprehensive S…
Alibaba Qwen Team Just Released Qwen3: The Latest Generation of Large Language Models in Qwen Series, Offering a Comprehensive Suite of Dense and Mixture-of-Experts (MoE) Models Despite the remarkable progress in large language models (LLMs), critical challenges remain. Many models exhibit limitations in nuanced reasoning, multilingual proficiency, and computational efficiency. Often, models are either highly…