AI News
Category Added in a WPeMatico Campaign
-
A Step-by-Step Guide on Building, Customizing, and Publishing an AI-Focused Blogging Website with Lovable.dev and Seamless GitHub Integration
In this tutorial, we will guide you step-by-step through creating and publishing a sleek, modern AI blogging website using Lovable.dev. Lovable.dev simplifies website creation, enabling users to effortlessly develop visually appealing and responsive web pages tailored to specific niches, like AI and technology. We’ll demonstrate how to build a homepage quickly, integrate interactive components, and…
-
Multimodal AI Needs More Than Modality Support: Researchers Propose General-Level and General-Bench to Evaluate True Synergy in Generalist Models
Artificial intelligence has grown beyond language-focused systems, evolving into models capable of processing multiple input types, such as text, images, audio, and video. This area, known as multimodal learning, aims to replicate the natural human ability to integrate and interpret varied sensory data. Unlike conventional AI models that handle a single modality, multimodal generalists are…
-
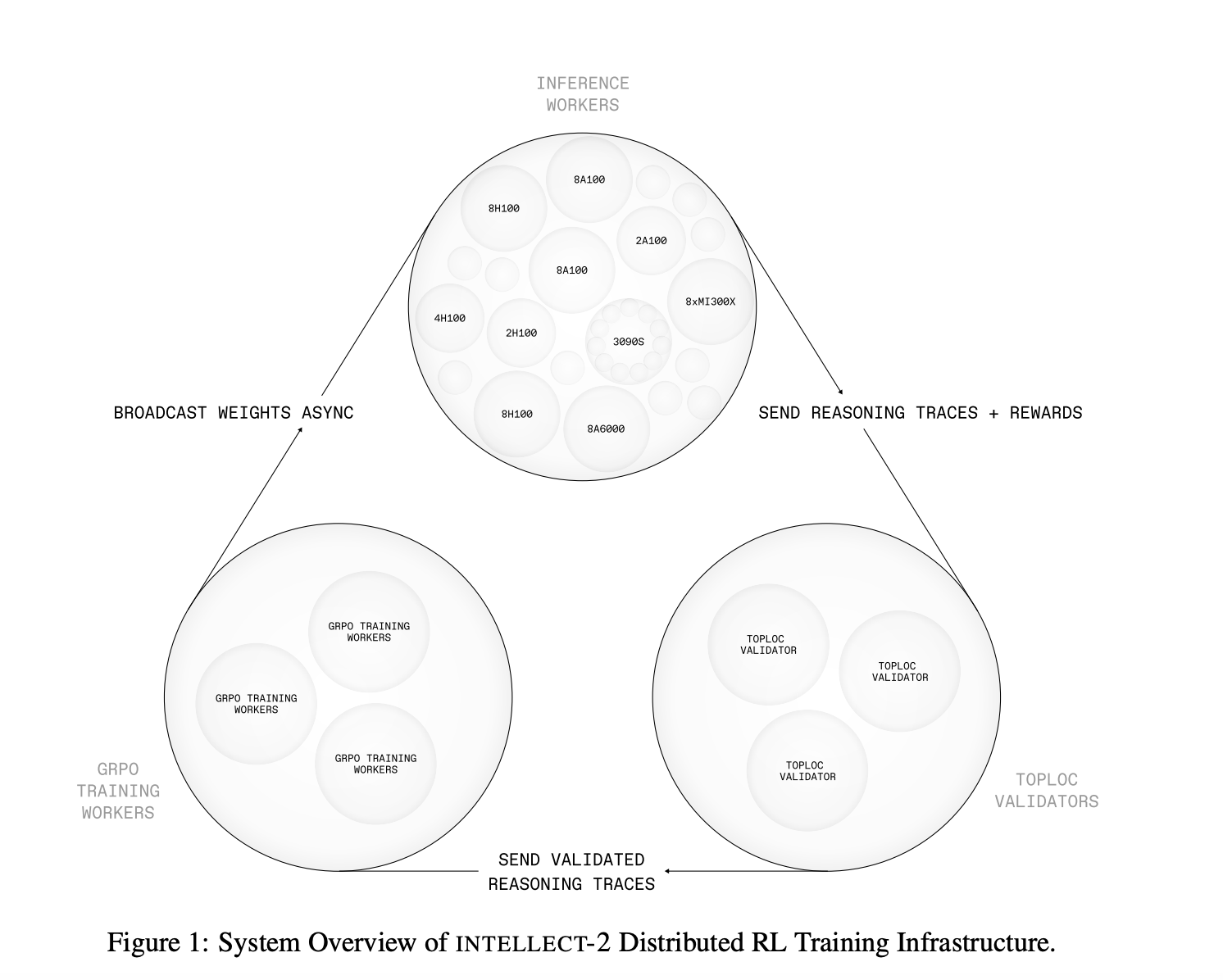
PrimeIntellect Releases INTELLECT-2: A 32B Reasoning Model Trained via Distributed Asynchronous Reinforcement Learning
As language models scale in parameter count and reasoning complexity, traditional centralized training pipelines face increasing constraints. High-performance model training often depends on tightly coupled compute clusters with fast interconnects, which are costly, limited in availability, and prone to scalability bottlenecks. Furthermore, centralized architectures restrict the possibility of widespread collaboration and experimentation, particularly in open-source…
-
AG-UI (Agent-User Interaction Protocol): An Open, Lightweight, Event-based Protocol that Standardizes How AI Agents Connect to Front-End Applications
The current generation of AI agents has made significant progress in automating backend tasks such as summarization, data migration, and scheduling. While effective, these agents typically operate behind the scenes—triggered by predefined workflows and returning results without user involvement. However, as AI applications become more interactive, a clear need has emerged for agents that can…
-
NVIDIA AI Introduces Audio-SDS: A Unified Diffusion-Based Framework for Prompt-Guided Audio Synthesis and Source Separation without Specialized Datasets
Audio diffusion models have achieved high-quality speech, music, and Foley sound synthesis, yet they predominantly excel at sample generation rather than parameter optimization. Tasks like physically informed impact sound generation or prompt-driven source separation require models that can adjust explicit, interpretable parameters under structural constraints. Score Distillation Sampling (SDS)—which has powered text-to-3D and image editing…
-
LightOn AI Released GTE-ModernColBERT-v1: A Scalable Token-Level Semantic Search Model for Long-Document Retrieval and Benchmark-Leading Performance
Semantic retrieval focuses on understanding the meaning behind text rather than matching keywords, allowing systems to provide results that align with user intent. This ability is essential across domains that depend on large-scale information retrieval, such as scientific research, legal analysis, and digital assistants. Traditional keyword-based methods fail to capture the nuance of human language,…
-
This AI Paper Introduces Effective State-Size (ESS): A Metric to Quantify Memory Utilization in Sequence Models for Performance Optimization
In machine learning, sequence models are designed to process data with temporal structure, such as language, time series, or signals. These models track dependencies across time steps, making it possible to generate coherent outputs by learning from the progression of inputs. Neural architectures like recurrent neural networks and attention mechanisms manage temporal relationships through internal…
-
A Coding Implementation of Accelerating Active Learning Annotation with Adala and Google Gemini
In this tutorial, we’ll learn how to leverage the Adala framework to build a modular active learning pipeline for medical symptom classification. We begin by installing and verifying Adala alongside required dependencies, then integrate Google Gemini as a custom annotator to categorize symptoms into predefined medical domains. Through a simple three-iteration active learning loop, prioritizing…
-
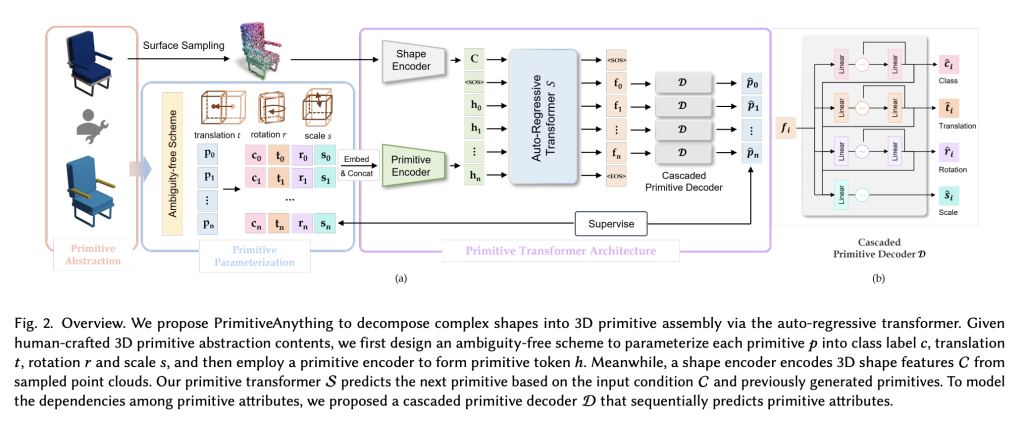
Tencent Released PrimitiveAnything: A New AI Framework That Reconstructs 3D Shapes Using Auto-Regressive Primitive Generation
Shape primitive abstraction, which breaks down complex 3D forms into simple, interpretable geometric units, is fundamental to human visual perception and has important implications for computer vision and graphics. While recent methods in 3D generation—using representations like meshes, point clouds, and neural fields—have enabled high-fidelity content creation, they often lack the semantic depth and interpretability…
-
Huawei Introduces Pangu Ultra MoE: A 718B-Parameter Sparse Language Model Trained Efficiently on Ascend NPUs Using Simulation-Driven Architecture and System-Level Optimization
Sparse large language models (LLMs) based on the Mixture of Experts (MoE) framework have gained traction for their ability to scale efficiently by activating only a subset of parameters per token. This dynamic sparsity allows MoE models to retain high representational capacity while limiting computation per token. However, with their increasing complexity and model size…