Large language models (LLMs) are getting better at scaling and handling long contexts. As they are being used on a large scale, there has been a growing demand for efficient support of high-throughput inference. However, efficiently serving these long-context LLMs presents challenges related to the key-value (KV) cache, which stores previous key-value activations to avoid re-computation. But as the text they handle gets longer, the increasing memory footprint and the need to access it for each token generation both result in low throughput when serving long-context LLMs.
The existing methods face three major issues: accuracy degradation, inadequate memory reduction, and significant decoding latency overhead. Strategies to delete older cache data help save memory but can lead to accuracy loss, especially in tasks like conversations. Methods like Dynamic sparse attention, keep all cached data on the GPU, speeding up calculations but not reducing memory needs enough for handling very long texts. A basic solution for this is to move some data from the GPU to the CPU to save memory, but this method reduces speed because retrieving data from the CPU takes time.
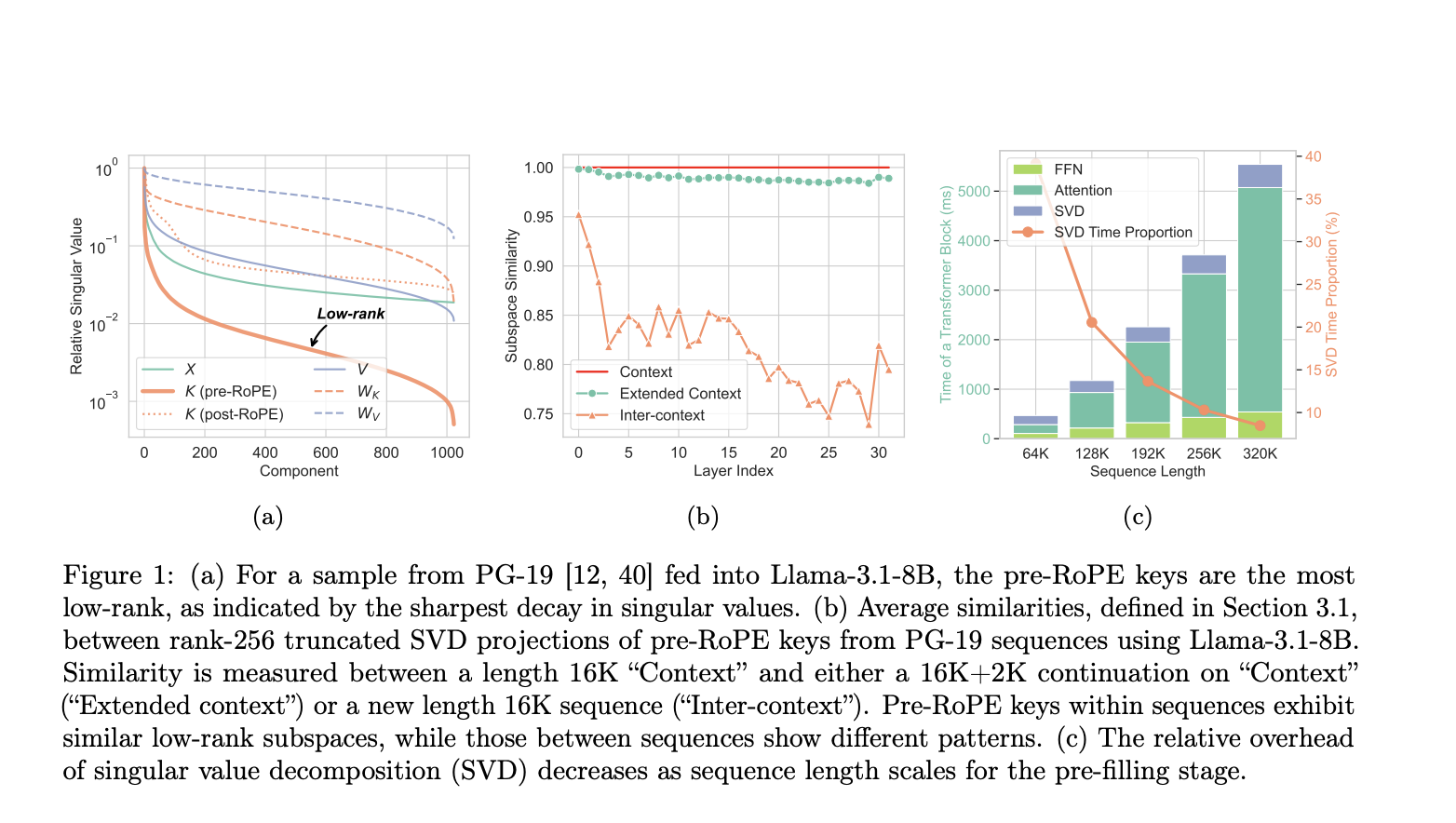
Pre-RoPE keys are a certain type of data that have a simpler structure, making them easy to compress and store efficiently. They are unique within a sequence but consistent across parts of that sequence, allowing them to compress highly within each sequence. This helps to keep only the important data on the GPU, while other data can be stored on the CPU without majorly affecting the speed and accuracy of the system. This approach achieves faster and more efficient handling of long texts with LLMs by improving memory use and carefully storing important data.
A group of researchers from Carnegie Mellon University and ByteDance proposed a method called ShadowKV, a high-throughput long-context LLM inference system that stores the low-rank key cache and offloads the value cache to reduce the memory footprint for larger batch sizes and longer sequences. To reduce decoding delays, ShadowKV uses a precise method for selecting key-value (KV) pairs, creating only the necessary sparse KV pairs as needed.
The algorithm of ShadowKV is divided into two main phases: pre-filling and decoding. In the pre-filing phase, it compresses key caches with low-rank representations and offloads value caches to CPU memory, performing SVD on the pre-RoPE key cache and segmenting post-RoPE key caches into chunks with calculated landmarks. Outliers, identified by cosine similarity within these chunks, are stored in a static cache on the GPU, while compact landmarks are kept in CPU memory. During decoding, ShadowKV computes an approximate attention score based on the top-k scoring chunks, reconstructs key caches from low-rank projections, and uses cache-aware CUDA kernels to reduce computation by 60%, creating only essential KV pairs. The “equivalent bandwidth” concept is used by ShadowKV, loading data efficiently to reach a bandwidth of 7.2 TB/s on an A100 GPU, which is 3.6 times its memory bandwidth. By evaluating ShadowKV on a broad range of benchmarks, including RULER, LongBench, and Needle In A Haystack, along with models like Llama-3.1-8B, Llama-3-8B-1M, GLM-4-9B-1M, Yi-9B-200K, Phi-3-Mini-128K, and Qwen2-7B-128K, it is demonstrated that ShadowKV can support up to 6 times larger batch sizes, even surpassing the performance achievable with infinite batch size under the assumption of infinite GPU memory.
In conclusion, the proposed method by researchers named ShadowKV is a high-throughput inference system for long-context LLM inference. ShadowKV optimizes GPU memory usage through the low-rank key cache and offloaded value cache, allowing larger batch sizes. It lowers decoding delays with precise sparse attention, increasing processing speed while keeping accuracy intact. This method may be a base for future research in the growing field of Large Language models!
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post ShadowKV: A High-Throughput Inference System for Long-Context LLM Inference appeared first on MarkTechPost.