Recent advancements in generative language modeling have propelled natural language processing, making it possible to create contextually rich and coherent text across various applications. Autoregressive (AR) models generate text in a left-to-right sequence and are widely used for tasks like coding and complex reasoning. However, these models face limitations due to their sequential nature, which makes them vulnerable to error accumulation with each step. The reliance on a strict order for generating tokens can restrict flexibility in sequence generation. To tackle these drawbacks, researchers have started exploring alternative methods, particularly those that allow parallel generation, enabling text to be created more easily and efficiently.
A critical challenge in language modeling is the progressive error accumulation inherent in autoregressive approaches. As each generated token directly depends on the preceding ones, minor initial errors can lead to significant deviations, impacting the quality of the generated text and reducing efficiency. Addressing these issues is crucial, as error buildup decreases accuracy and limits AR models’ usability for real-time applications that demand high-speed and reliable output. Therefore, researchers are investigating parallel text generation to retain high performance while mitigating errors. Although parallel generation models have shown promise, they often need to match the detailed contextual understanding achieved by traditional AR models.
Presently, discrete diffusion models stand out as an emerging solution for parallel text generation. These models generate entire sequences simultaneously, offering significant speed benefits. Discrete diffusion models start from a fully masked sequence and progressively uncover tokens in a non-sequential manner, allowing for bidirectional text generation. Despite this capability, current diffusion-based approaches face limitations due to their reliance on independent token predictions, which overlook the dependencies between tokens. This independence often results in decreased accuracy and the need for multiple sampling steps, leading to inefficiencies. While other models attempt to bridge the gap between quality and speed, most need help to reach the accuracy and fluency provided by autoregressive setups.
Researchers from Stanford University and NVIDIA introduced the Energy-based Diffusion Language Model (EDLM). EDLM represents an innovative approach that combines energy-based modeling with discrete diffusion to tackle the inherent challenges of parallel text generation. By integrating an energy function at each stage of the diffusion process, EDLM seeks to correct inter-token dependencies, thus enhancing the sequence’s quality and maintaining the advantages of parallel generation. The energy function allows the model to learn dependencies within the sequence by leveraging either a pretrained autoregressive model or a bidirectional transformer fine-tuned through noise contrastive estimation. EDLM’s architecture, therefore, merges the efficiency of diffusion with the sequence coherence typical of energy-based methods, making it a pioneering model in the field of language generation.
The EDLM framework involves an in-depth methodology focused on introducing an energy function that dynamically captures correlations among tokens throughout the generation process. This energy function operates as a corrective mechanism within each diffusion step, effectively addressing the challenges associated with token independence in other discrete diffusion models. By adopting a residual form, the energy function enables EDLM to refine predictions iteratively. The energy-based framework operates on pretrained autoregressive models, which allows EDLM to bypass the need for maximum likelihood training—a typically costly process. Instead, the model’s energy function operates directly on the sequence, allowing EDLM to conduct efficient parallel sampling through importance sampling, further enhancing the model’s accuracy. This efficient sampling method reduces decoding errors by optimizing the token dependency mechanism, setting EDLM apart from other diffusion-based methods.
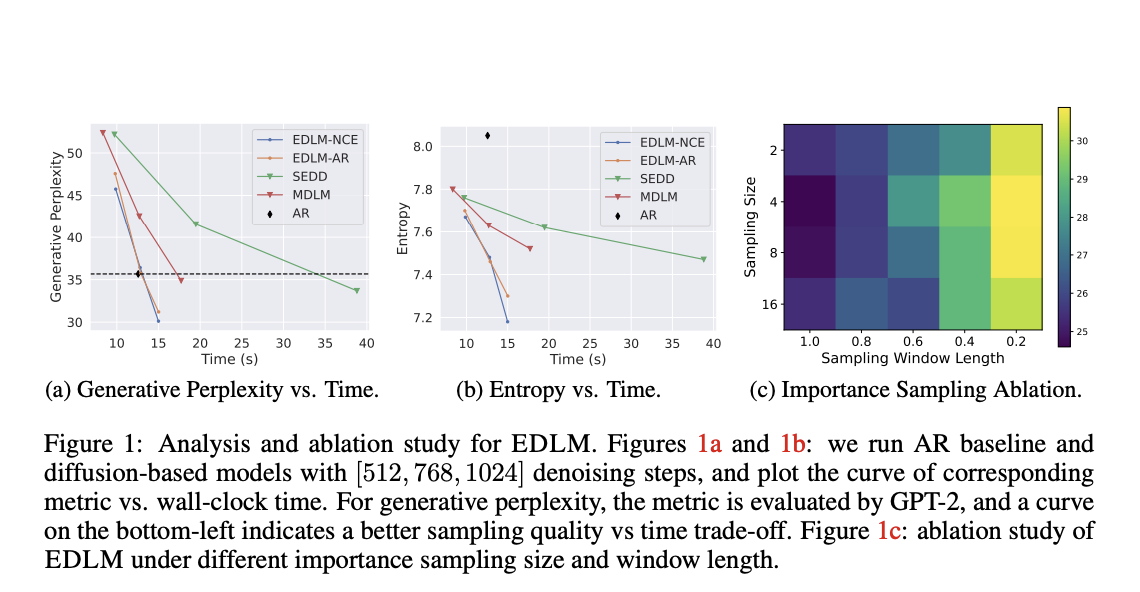
Performance evaluations of EDLM reveal substantial improvements in speed and quality of text generation. In trials against other models on language benchmarks, EDLM showed an up to 49% reduction in generative perplexity, marking a significant advance in the accuracy of text generation. Further, EDLM demonstrated a 1.3x speedup in sampling compared to conventional diffusion models, all without sacrificing performance. Benchmark tests further indicated that EDLM approaches the perplexity levels typically achieved by autoregressive models while maintaining the efficiency benefits inherent to parallel generation. For instance, in a comparison using the Text8 dataset, EDLM achieved the lowest bits-per-character score among tested models, highlighting its superior ability to maintain text coherence with fewer decoding errors. Furthermore, on the OpenWebText dataset, EDLM outperformed other state-of-the-art diffusion models, achieving competitive performance even against robust autoregressive models.
In conclusion, EDLM’s novel approach successfully addresses longstanding issues related to sequential dependency and error propagation in language generation models. By effectively combining energy-based corrections with the parallel capabilities of diffusion models, EDLM introduces a model that offers both accuracy and enhanced speed. This innovation by researchers from Stanford and NVIDIA demonstrates that energy-based approaches can play a crucial role in the evolution of language models, providing a promising alternative to autoregressive methods for applications requiring high performance and efficiency. EDLM’s contributions lay the groundwork for more adaptable, contextually aware language models that can achieve both accuracy and efficiency, underscoring the potential of energy-based frameworks in advancing generative text technologies.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post EDLM: A New Energy-based Language Model Embedded with Diffusion Framework appeared first on MarkTechPost.