
Retrieval-Augmented Generation (RAG) is a growing area of research focused on improving the capabilities of large language models (LLMs) by incorporating external knowledge sources. This approach involves two primary components: a retrieval module that finds relevant external information and a generation module that uses this information to produce accurate responses. RAG is particularly useful in open-domain question-answering (QA) tasks, where the model needs to pull information from large external datasets. This retrieval process enables models to provide more informed and precise answers, addressing the limitations of relying solely on their internal parameters.
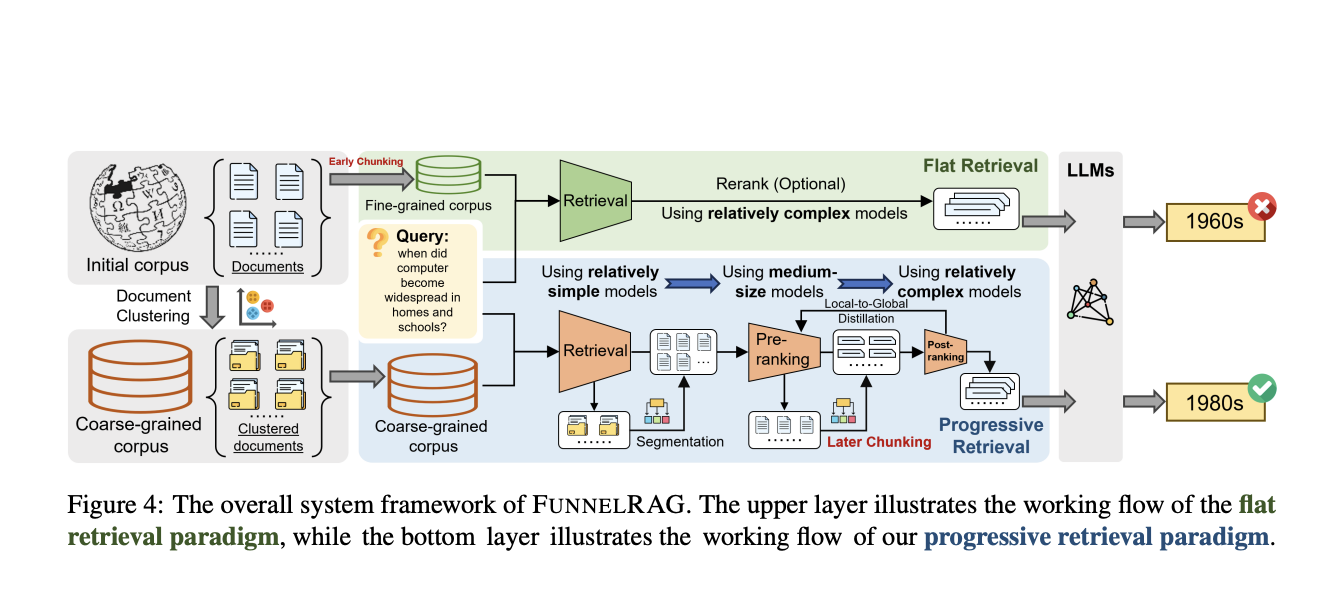
In existing retrieval systems, several inefficiencies persist. One of the most critical challenges is the flat retrieval paradigm, which treats the entire retrieval process as a single, static step. This method places a significant computational burden on individual retrievers, which must process millions of data points in one step. Further, the granularity of the retrieved information remains constant throughout the process, limiting the system’s potential to refine its results progressively. While effective to some degree, this flat approach often leads to inefficiencies in accuracy and time, particularly when the dataset is vast.
Traditional RAG systems have relied on methods like the Dense Passage Retriever (DPR), which ranks short, segmented pieces of text from large corpora, such as 100-word passages from millions of documents. While this method can retrieve relevant information, it needs to improve with scale and often introduces inefficiencies when processing large amounts of data. Other techniques use single retrievers for the entire retrieval process, exacerbating the issue by forcing one system to handle too much information at once, making it difficult to find the most relevant data quickly.
Researchers from the Harbin Institute of Technology and Peking University introduced a new retrieval framework called “FunnelRAG.” This method takes a progressive approach to retrieval, refining data in stages from a broad scope to more specific units. By gradually narrowing down the candidate data and employing mixed-capacity retrievers at each stage, FunnelRAG alleviates the computational burden that typically falls on one retriever in flat retrieval models. This innovation also increases retrieval accuracy by enabling retrievers to work in steps, progressively reducing the amount of data processed at each stage.
FunnelRAG works in several distinct stages, each refining the data further. The first stage involves a large-scale retrieval using sparse retrievers to process clusters of documents with around 4,000 tokens. This approach reduces the overall corpus size from millions of candidates to a more manageable 600,000. In the pre-ranking stage, the system uses more advanced models to rank these clusters at a finer level, processing document-level units of about 1,000 tokens. The final stage, post-ranking, segments documents into short, passage-level units before the system performs the final retrieval with high-capacity retrievers. This stage ensures the system extracts the most relevant information by focusing on fine-grained data. Using this coarse-to-fine approach, FunnelRAG balances efficiency and accuracy, ensuring that relevant information is retrieved without unnecessary computational overhead.
The performance of FunnelRAG has been thoroughly tested on various datasets, demonstrating significant improvements in both time efficiency and retrieval accuracy. Compared to flat retrieval methods, FunnelRAG reduced the overall time required for retrieval by nearly 40%. This time-saving is achieved without sacrificing performance; in fact, the system maintained or even outperformed traditional retrieval paradigms in several key areas. On the Natural Questions (NQ) and Trivia QA (TQA) datasets, FunnelRAG achieved answer recall rates of 75.22% and 80.00%, respectively, when retrieving top-ranked documents. In the same datasets, the candidate pool size was reduced dramatically, from 21 million candidates to around 600,000 clusters, while maintaining high retrieval accuracy.
Another noteworthy result is the balance between efficiency and effectiveness. FunnelRAG’s ability to handle large datasets while ensuring accurate retrieval makes it particularly useful for open-domain QA tasks, where speed and precision are critical. The system’s ability to progressively refine data using mixed-capacity retrievers significantly improves retrieval performance, especially when the goal is to extract the most relevant passages from vast datasets. Using sparse and dense retrievers at different stages, FunnelRAG ensures that the computational load is distributed effectively, enabling high-capacity models to focus only on the most relevant data.
In conclusion, the researchers have effectively addressed the inefficiencies of flat retrieval systems by introducing FunnelRAG. This method represents a significant improvement in retrieval efficiency and accuracy, particularly in the context of large-scale open-domain QA tasks. Combined with its progressive approach, the coarse-to-fine granularity of FunnelRAG reduces time overhead while maintaining retrieval performance. The work from the Harbin Institute of Technology and Peking University demonstrates the feasibility of this new framework and its potential to transform the way large language models retrieve and generate information.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post FunnelRAG: A Novel AI Approach to Improving Retrieval Efficiency for Retrieval-Augmented Generation appeared first on MarkTechPost.