Alignment with human preferences has led to significant progress in producing honest, safe, and useful responses from Large Language Models (LLMs). Through this alignment process, the models are better equipped to comprehend and represent what humans think is suitable or important in their interactions. But, maintaining LLMs’ advancement in accordance with these inclinations is a difficult task. The process of collecting the kind of high-quality data needed for this alignment is costly and time-consuming. It is challenging to scale up and maintain over time since it frequently requires much human ingenuity and participation.
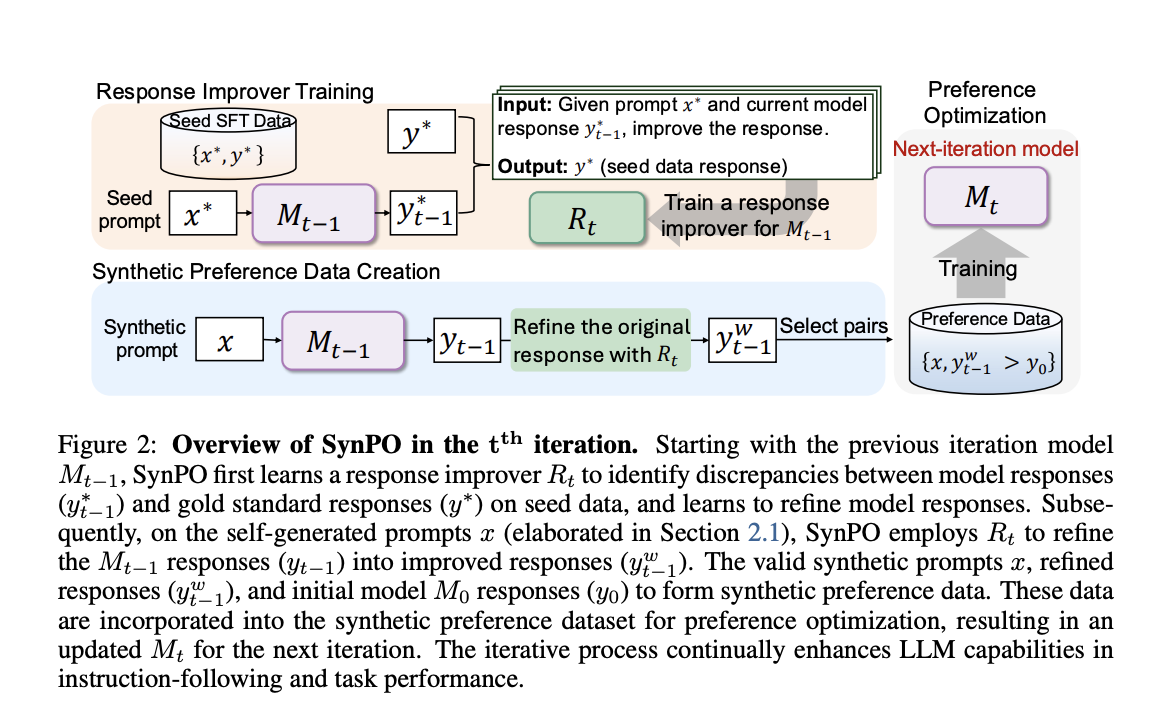
A unique technique known as SynPO (Synthetic Preference Optimisation) has been created to overcome these obstacles. SynPO is a self-boosting method that enhances LLM alignment without heavily depending on human annotations by creating synthetic data. By using an iterative process to produce and enhance synthetic prompts, this strategy enables the model to learn and get better with every cycle. A self-prompt generator and a response improver are its two primary parts.
- Self-Prompt Generator: This part uses the model’s built-in capabilities to produce a variety of prompts. Instead of relying on complicated datasets or outside human inputs, it makes use of the LLM itself to provide a range of cues that elicit various scenarios and replies. This generation procedure creates a richer training environment by enabling the model to investigate a variety of scenarios and difficulties.
- Response Improver: The response improver significantly improves the model’s outputs by improving the replies produced throughout each cycle. It guides the LLM to provide better outputs that more closely match the intended results by pointing out places where the model’s initial responses are inadequate and making the necessary adjustments. It educates the model on attaining that quality level with little tweaks after assisting it in identifying what constitutes a good answer.
SynPO combines these two elements to allow LLMs to learn from synthetic feedback loops on their own. The model steadily improves at comprehending and satisfying user expectations by training itself on the incentives it receives for producing better responses. This self-driven method is more effective and scalable since it drastically cuts down on the requirement for manual data labeling and preference gathering.
SynPO has proven to be beneficial in a number of crucial performance domains. Following instructions is much improved by LLMs such as Llama3-8B and Mistral-7B after only four iterations of this self-improving cycle. In particular, these models significantly improve their ability to generate desired reactions, as evidenced by victory rate increases of over 22.1% on evaluation benchmarks such as AlpacaEval 2.0 and ArenaHard. A 3.2% to 5.0% rise in average scores on the Open LLM leaderboard, a commonly used indicator of LLM ability, has shown that SynPO helps to further enhance LLM capabilities across a range of jobs.
The team has summarized their primary contribution as follows.
- SynPO is a self-boosting process that allows LLMs to iteratively produce high-quality synthetic training data. It improves the variety and caliber of generated prompts and responses by eliminating the requirement for human-annotated preference data.
- Using recurrent training cycles, SynPO helps LLMs improve their outputs. It enables LLMs to learn from generating feedback and progressively increase their capabilities by using pre- and post-refinement replies as synthetic preference pairs.
- SynPO enhances LLMs’ general performance as well as their capacity to follow directions. LLMs exhibit notable progress over three to four iterations, proving that this method is successful in increasing model capabilities.
In conclusion, SynPO is a viable way to improve LLMs without incurring the high expenses connected with conventional data collection techniques. Iterative self-training and synthetic data enable LLMs to continuously evolve and adapt, becoming more in line with human preferences while retaining adaptability for a variety of applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Meet SynPO: A Self-Boosting Paradigm that Uses Synthetic Preference Data for Model Alignment appeared first on MarkTechPost.