Large Language Models (LLMs) have revolutionized artificial intelligence, impacting various scientific and engineering disciplines. The Transformer architecture, initially designed for machine translation, has become the foundation for GPT models, significantly advancing the field. However, current LLMs face challenges in their training approach, which primarily focuses on predicting the next token based on previous context while maintaining causality. This straightforward method has been applied across diverse domains, including robotics, protein sequences, audio processing, and video analysis. As LLMs continue to grow in scale, reaching hundreds of billions to even trillions of parameters, concerns arise about the accessibility of AI research, with some fearing it may become confined to industry researchers. The central problem researchers are tackling is how to enhance model capabilities to match those of much larger architectures or achieve comparable performance with fewer training steps, ultimately addressing the challenges of scale and efficiency in LLM development.
Researchers have explored various approaches to enhance LLM performance by manipulating intermediate embeddings. One method involved applying hand-tuned filters to the Discrete Cosine Transform of the latent space for tasks like named entity recognition and topic modeling in non-causal architectures such as BERT. However, this approach, which transforms the entire context length, is not suitable for causal language modeling tasks.
Two notable techniques, FNet and WavSPA, attempted to improve attention blocks in BERT-like architectures. FNet replaced the attention mechanism with a 2-D FFT block, but this operation was non-causal, considering future tokens. WavSPA computed attention in wavelet space, utilizing multi-resolution transforms to capture long-term dependencies. However, it also relied on non-causal operations, examining the entire sequence length.
These existing methods, while innovative, face limitations in their applicability to causal decoder-only architectures like GPT. They often violate the causality assumption crucial for next-token prediction tasks, making them unsuitable for direct adaptation to GPT-like models. The challenge remains to develop techniques that can enhance model performance while maintaining the causal nature of decoder-only architectures.
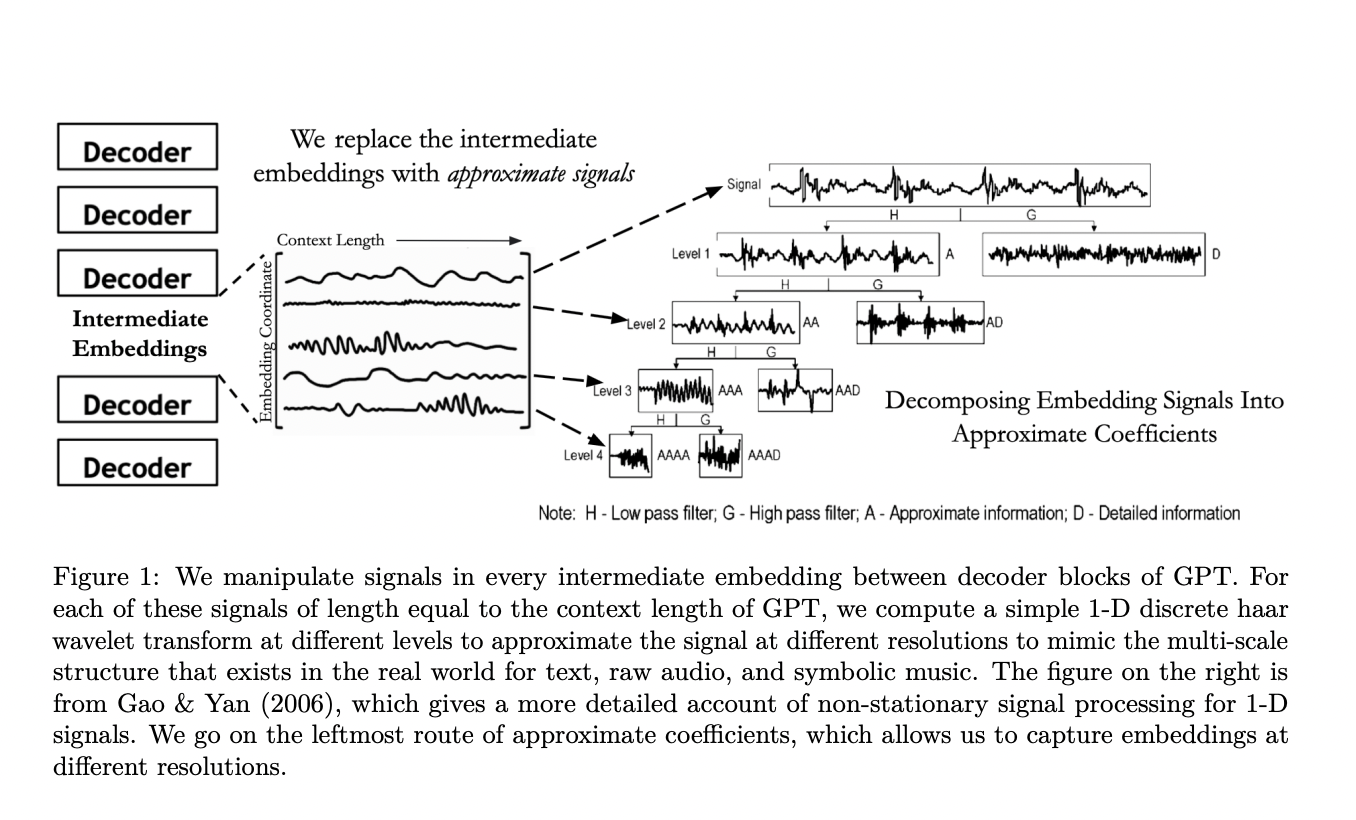
Researchers from Stanford propose the first instance of incorporating wavelets into LLMs, WaveletGPT, to enhance LLMs by incorporating wavelets into their architecture. This technique, believed to be the first of its kind, adds multi-scale filters to the intermediate embeddings of Transformer decoder layers using Haar wavelets. The innovation allows each next-token prediction to access multi-scale representations at every layer, rather than relying on fixed-resolution representations.
Remarkably, this method accelerates pre-training of transformer-based LLMs by 40-60% without adding extra parameters, a significant advancement given the widespread use of Transformer Decoder-based architectures across various modalities. The approach also demonstrates substantial performance improvements with the same number of training steps, comparable to adding several layers or parameters.
The wavelet-based operation shows performance boosts across three different modalities: language (text-8), raw audio (YoutubeMix), and symbolic music (MAESTRO), highlighting its versatility for structured datasets. Also, by making the wavelet kernels learnable, which adds only a small fraction of parameters, the model achieves even greater performance increases, allowing it to learn multi-scale filters on intermediate embeddings from scratch.
The proposed method incorporates wavelets into transformer-based Large Language Models while maintaining the causality assumption. This approach can be applied to various architectures, including non-transformer setups. The technique focuses on manipulating intermediate embeddings from each decoder layer.
For a given signal xl(i), representing the output of the lth decoder layer along the ith coordinate, the method applies a discrete wavelet transform. With N+1 layers and an embedding dimension E, this process generates N*E signals of length L (context length) from intermediate embeddings between decoder blocks.
The wavelet transform, specifically using Haar wavelets, involves passing the signal through filters with different resolutions. Haar wavelets are square-shaped functions derived from a mother wavelet through scaling and shifting operations. This process creates child wavelets that capture signal information at various time-scales.
The discrete wavelet transform is implemented by passing the signal through low-pass and high-pass filters, followed by downsampling. For Haar wavelets, this equates to averaging and differencing operations. The process generates approximation coefficients (yapprox) and detail coefficients (ydetail) through convolution and downsampling. This operation is performed recursively on the approximation coefficients to obtain multi-scale representations, allowing each next-token prediction to access these multi-resolution representations of intermediate embeddings.
This method connects wavelets and LLM embeddings by focusing on approximation coefficients, which capture structured data at various levels. For text, this structure ranges from letters to topic models, while for symbolic music, it spans from notes to entire pieces. The approach uses Haar wavelets, simplifying the process to a moving average operation. To maintain causality and original sequence length, the method computes moving averages of prior samples within a specific kernel length for each token dimension. This creates multi-scale representations of the input signal, allowing the model to capture information at different resolutions across embedding dimensions without altering the structure of intermediate Transformer embeddings.
The method introduces a unique approach to incorporate multi-scale representations without increasing architectural complexity. Instead of computing all levels of approximate signals for each embedding dimension, it parameterized the level by the index of the embedding dimension itself. This approach retains half of the intermediate embedding signals unchanged, while processing the other half based on their index. For the processed half, a simple mapping function f determines the kernel size for each coordinate, ranging from level I to IX approximations. The modified signal xnl(i) is computed using a causal moving average filter with a kernel size determined by f(i). This operation maintains the causality assumption critical in LLMs and prevents information leakage from future tokens. The technique creates a structure where different embedding dimensions move at different rates, allowing the model to capture information at various scales. This multi-rate structure enables the attention mechanism to utilize multi-scale features at every layer and token, potentially enhancing the model’s ability to capture complex patterns in the data.
Results across three modalities – text, symbolic music, and audio waveforms – demonstrate substantial performance improvements with the wavelet-based intermediate operation. For natural language, the decrease in validation loss is equivalent to expanding from a 16-layer to a 64-layer model on the text-8 dataset. The modified architecture achieves the same loss nearly twice as fast as the original in terms of training steps. This speedup is even more pronounced for raw audio, potentially due to the quasi-stationary nature of audio signals over short time scales. The convergence for raw waveform LLM setups occurs almost twice as quickly compared to text-8 and symbolic music.
Comparing absolute clock run times, the modified architecture shows computational efficiency in both learnable and non-learnable setups. The time required to complete one epoch relative to the baseline architecture is reported. The method proves to be computationally inexpensive, as the primary operation involves simple averaging for Haar wavelets or learning a single filter convolutional kernel with variable context lengths across embedding dimensions. This efficiency, combined with the performance improvements, underscores the effectiveness of the wavelet-based approach in enhancing LLM training across diverse modalities without significant computational overhead.
This study presents WaveletGPT, introducing the integration of wavelets, a core signal processing technique, into large language model pre-training. By introducing a multi-scale structure to intermediate embeddings, performance speed is enhanced by 40-60% without adding any extra parameters. This technique proves effective across three different modalities: raw text, symbolic music, and raw audio. When trained for the same duration, it demonstrates substantial performance improvements. Potential future directions include incorporating advanced concepts from wavelets and multi-resolution signal processing to optimize large language models further.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!
The post WaveletGPT: Leveraging Wavelet Theory for Speedier LLM Training Across Modalities appeared first on MarkTechPost.