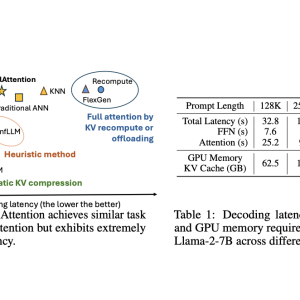
Large Language Models (LLMs) have made significant strides in processing extensive contexts, with some models capable of handling up to 10 million tokens. However, this advancement brings challenges in inference efficiency due to the quadratic complexity of attention computation. While KV caching has been widely adopted to prevent redundant computations, it introduces substantial GPU memory requirements and increased inference latency for long contexts. The Llama-2-7B model, for instance, requires approximately 500GB per million tokens in FP16 format. These issues highlight the critical need to reduce token access and storage costs to enhance inference efficiency. The solution to these challenges lies in utilizing the dynamic sparsity inherent in the attention mechanism, where each query vector significantly interacts with only a limited subset of key and value vectors.
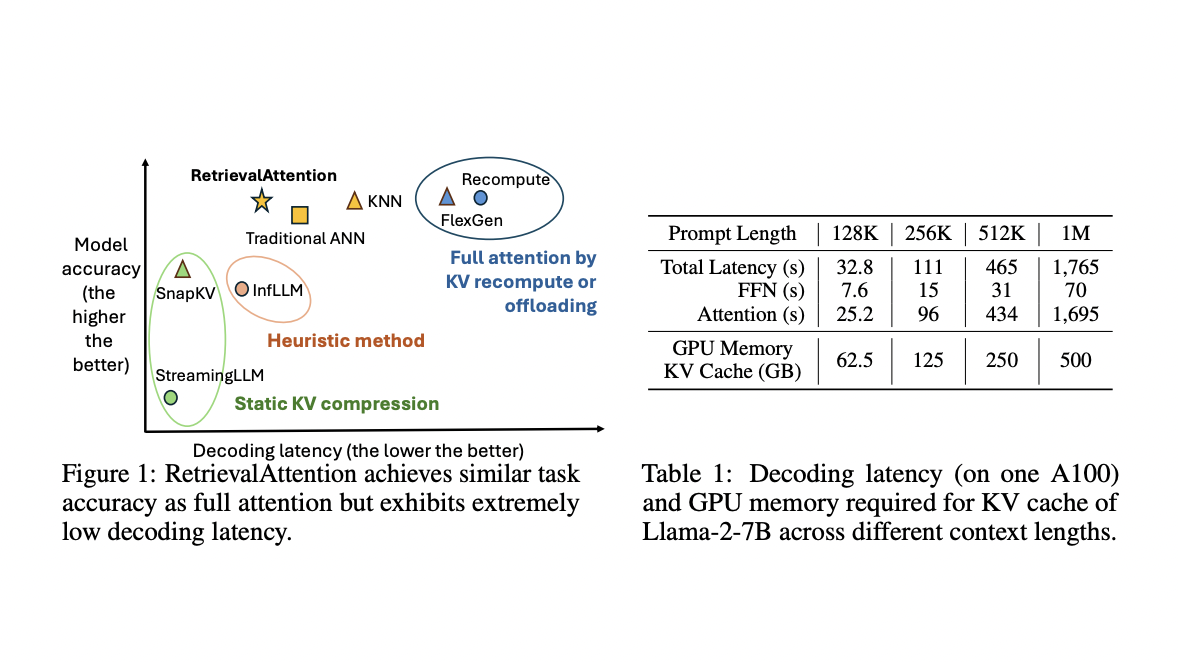
Existing attempts to accelerate long-context LLM inference have focused on compressing the KV cache size by utilizing attention sparsity. However, these methods often result in significant accuracy drops due to the dynamic nature of attention sparsity. Some approaches, like FlexGen and Lamina, offload the KV cache to CPU memory but face challenges with slow and costly full-attention computation. Other methods, such as Quest and InfLLM, partition the KV cache into blocks and select representative key vectors, but their effectiveness depends heavily on the accuracy of these representatives. SparQ, InfiniGen, and LoKi attempt to approximate the most relevant top-k keys by reducing head dimensions.
Researchers from Microsoft Research, Shanghai Jiao Tong University, and Fudan University introduce RetrievalAttention, an innovative method designed to accelerate long-context LLM generation. It employs dynamic sparse attention during token generation, allowing the most critical tokens to emerge from extensive context data. To tackle the out-of-distribution (OOD) challenge, RetrievalAttention introduces a vector index specifically tailored for the attention mechanism, focusing on query distribution rather than key similarities. This approach enables the traversal of only 1% to 3% of key vectors, effectively identifying the most relevant tokens for accurate attention scores and inference results. RetrievalAttention also optimizes GPU memory consumption by retaining a small number of KV vectors in GPU memory following static patterns, while offloading the majority to CPU memory for index construction. During token generation, it efficiently retrieves critical tokens using vector indexes on the CPU and merges partial attention results from both CPU and GPU. This strategy enables RetrievalAttention to perform attention computation with reduced latency and minimal GPU memory footprint.
RetrievalAttention employs a CPU-GPU co-execution strategy to accelerate attention computation for long-context LLM inference. The method decomposes attention computation into two disjoint sets of KV cache vectors: predictable ones on GPU and dynamic ones on CPU. It utilizes patterns observed in the prefill phase to predict consistently activated KV vectors during token generation, persisting them in the GPU cache. The current implementation uses fixed initial tokens and the last sliding window of the context as the static pattern, similar to StreamingLLM. For CPU-side computation, RetrievalAttention builds an attention-aware vector search index to efficiently retrieve relevant KV vectors. This index is constructed using KNN connections from query vectors to key vectors, which are then projected onto key vectors to streamline the search process. This approach allows for scanning only 1-3% of key vectors to achieve high recall, significantly reducing index search latency. To minimize data transfer over the PCIe interface, RetrievalAttention independently computes attention results for CPU and GPU components before combining them, inspired by FastAttention.
RetrievalAttention demonstrates superior performance in both accuracy and efficiency compared to existing methods. It achieves comparable accuracy to full attention while significantly reducing computational costs. In complex tasks like KV retrieval, RetrievalAttention outperforms static methods such as StreamingLLM and SnapKV, which lack dynamic token retrieval capabilities. It also surpasses InfLLM, which struggles with accuracy due to low-quality representative vectors. RetrievalAttention’s ability to accurately identify relevant key vectors allows it to maintain high task accuracy across various context lengths, from 4K to 128K tokens. In the needle-in-a-haystack task, effectively focuses on critical information regardless of position within the context window. Regarding latency, RetrievalAttention shows significant improvements over full attention and other methods. It achieves 4.9× and 1.98× latency reduction compared to Flat and IVF indexes respectively for 128K context, while scanning only 1-3% of vectors. This combination of high accuracy and low latency demonstrates RetrievalAttention’s effectiveness in handling complex, dynamic tasks with long contexts.
This study presents RetrievalAttention, an innovative solution for accelerating long-context LLM inference by offloading most KV vectors to CPU memory and employing dynamic sparse attention through vector search. The method addresses the distribution differences between query and key vectors, utilizing an attention-aware approach to efficiently identify critical tokens for model generation. Experimental results demonstrate RetrievalAttention’s effectiveness, achieving 4.9× and 1.98× decoding speedup compared to exact KNN and traditional ANNS methods, respectively, on a single RTX4090 GPU with a context of 128K tokens. RetrievalAttention is the first system to support running 8B-level LLMs with 128K tokens on a single 4090 (24GB) GPU, maintaining acceptable latency and preserving model accuracy. This breakthrough significantly enhances the efficiency and accessibility of large language models for extensive context processing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post RetrievalAttention: A Training-Free Machine Learning Approach to both Accelerate Attention Computation and Reduce GPU Memory Consumption appeared first on MarkTechPost.