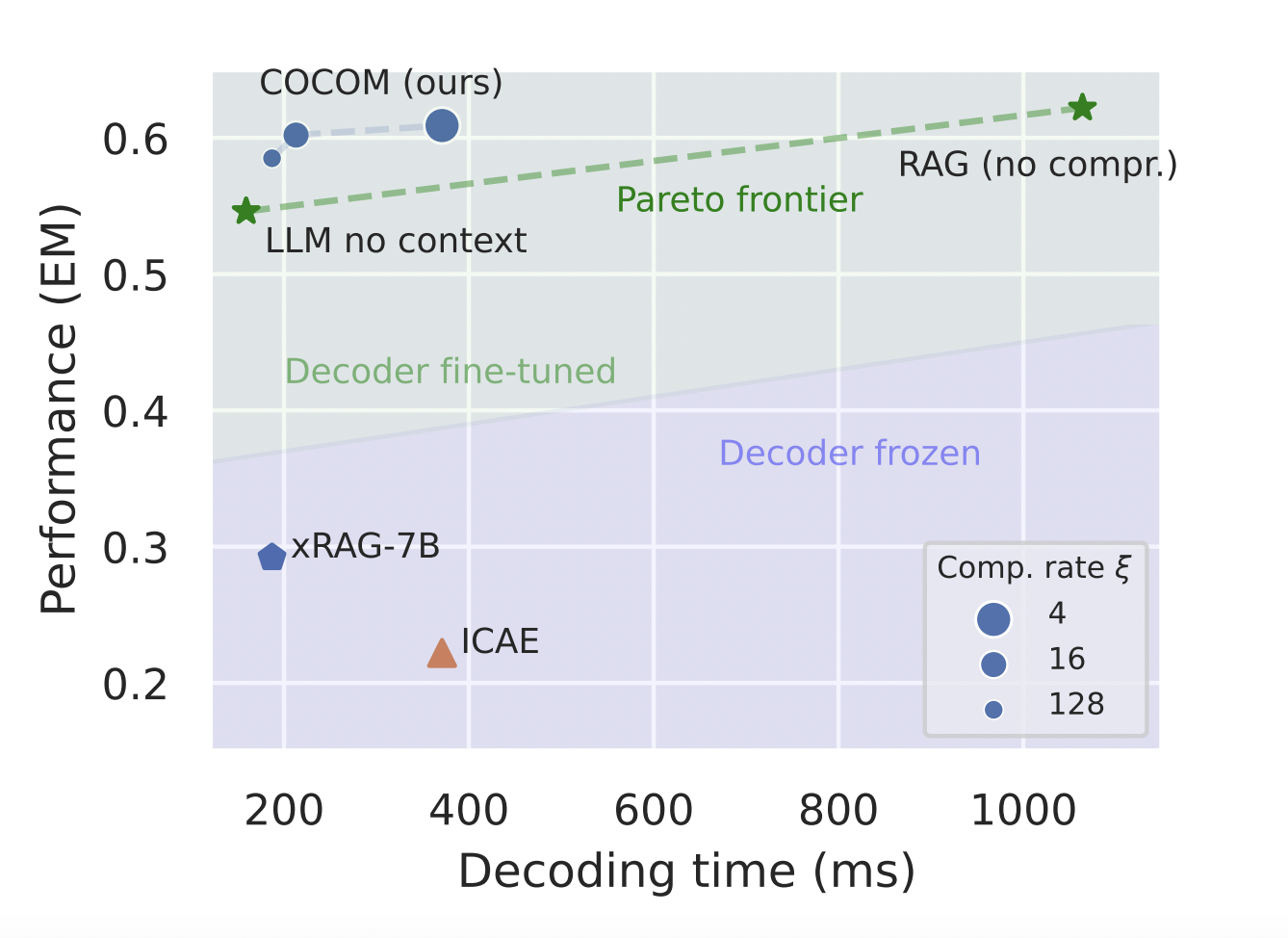
One of the central challenges in Retrieval-Augmented Generation (RAG) models is efficiently managing long contextual inputs. While RAG models enhance large language models (LLMs) by incorporating external information, this extension significantly increases input length, leading to longer decoding times. This issue is critical as it directly impacts user experience by prolonging response times, particularly in real-time applications such as complex question-answering systems and large-scale information retrieval tasks. Addressing this challenge is crucial for advancing AI research, as it makes LLMs more practical and efficient for real-world applications.
Current methods to address this challenge primarily involve context compression techniques, which can be divided into lexical-based and embedding-based approaches. Lexical-based methods filter out unimportant tokens or terms to reduce input size but often miss nuanced contextual information. Embedding-based methods transform the context into fewer embedding tokens, yet they suffer from limitations such as large model sizes, low effectiveness due to untuned decoder components, fixed compression rates, and inefficiencies in handling multiple context documents. These limitations restrict their performance and applicability, particularly in real-time processing scenarios.
A team of researchers from the University of Amsterdam, The University of Queensland, and Naver Labs Europe introduce COCOM (COntext COmpression Model), a novel and effective context compression method that overcomes the limitations of existing techniques. COCOM compresses long contexts into a small number of context embeddings, significantly speeding up the generation time while maintaining high performance. This method offers various compression rates, enabling a balance between decoding time and answer quality. The innovation lies in its ability to efficiently handle multiple contexts, unlike previous methods that struggled with multi-document contexts. By using a single model for both context compression and answer generation, COCOM demonstrates substantial improvements in speed and performance, providing a more efficient and accurate solution compared to existing methods.
COCOM involves compressing contexts into a set of context embeddings, significantly reducing the input size for the LLM. The approach includes pre-training tasks such as auto-encoding and language modeling from context embeddings. The method uses the same model for both compression and answer generation, ensuring effective utilization of the compressed context embeddings by the LLM. The dataset used for training includes various QA datasets like Natural Questions, MS MARCO, HotpotQA, WikiQA, and others. Evaluation metrics focus on Exact Match (EM) and Match (M) scores to assess the effectiveness of the generated answers. Key technical aspects include parameter-efficient LoRA tuning and the use of SPLADE-v3 for retrieval.
COCOM achieves significant improvements in decoding efficiency and performance metrics. It demonstrates a speed-up of up to 5.69 times in decoding time while maintaining high performance compared to existing context compression methods. For example, COCOM achieved an Exact Match (EM) score of 0.554 on the Natural Questions dataset with a compression rate of 4, and 0.859 on TriviaQA, significantly outperforming other methods like AutoCompressor, ICAE, and xRAG. These improvements highlight COCOM’s superior ability to handle longer contexts more effectively while maintaining high answer quality, showcasing the method’s efficiency and robustness across various datasets.
In conclusion, COCOM represents a significant advancement in context compression for RAG models by reducing decoding time and maintaining high performance. Its ability to handle multiple contexts and offer adaptable compression rates makes it a critical development for enhancing the scalability and efficiency of RAG systems. This innovation has the potential to greatly improve the practical application of LLMs in real-world scenarios, overcoming critical challenges and paving the way for more efficient and responsive AI applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post COCOM: An Effective Context Compression Method that Revolutionizes Context Embeddings for Efficient Answer Generation in RAG appeared first on MarkTechPost.