Charts are essential tools in various fields, but current models for chart understanding have limitations. They often rely on data tables rather than visual patterns and use weakly aligned vision-language models, limiting their effectiveness with complex charts. Although language-augmented vision models perform well in general tasks, they need help with specialized chart analysis. Researchers have tried instruction-tuning these models for better chart comprehension, but data quality and model alignment issues persist. A simple, improved approach is needed to develop a robust foundation model for effective chart understanding and reasoning in diverse, real-world scenarios.
Researchers from York University, MILA – Quebec AI Institute, Salesforce Research, and Nanyang Technological University developed ChartGemma, an advanced chart understanding and reasoning model. Unlike existing models, ChartGemma is trained on data generated directly from chart images, capturing detailed visual information. Built on the PaliGemma backbone, it is smaller and more efficient than other models. ChartGemma achieves state-of-the-art results in chart summarization, question answering, and fact-checking across five benchmarks. Qualitative studies show it generates realistic and accurate summaries, making it highly effective for real-world chart analysis.
Chart representation learning has evolved from models fine-tuned from language or vision-language bases to those pre-trained with chart-specific objectives. Instruction-tuning of pre-trained vision-language models (VLMs) has been explored to enhance chart applicability, but these methods rely on underlying data tables and weakly-aligned VLMs. Benchmarks for chart modeling range from question answering to open-ended tasks like explanation generation and summarization. Instruction-tuning has generalized language models across functions and is now standard for multimodal VLMs. However, domain-specific instruction-tuning for charts using data tables fails to capture the complexity of real-world charts, limiting model effectiveness.
ChartGemma uses the PaliGemma architecture, featuring the SigLIP vision encoder and the Gemma-2B language model. The vision encoder processes 448×448 pixel images, converting them into visual tokens mapped into the language model’s embedding space. These tokens are then combined with text embeddings and processed by the Gemma-2B model, which uses full attention for input tokens and causal masking for output tokens to enhance contextual understanding. Unlike existing chart VLLMs that require a two-stage training approach, ChartGemma employs a single-stage method, directly fine-tuning instruction-tuning data. This is facilitated by PaliGemma’s extensive pre-training on diverse image-text pairs, allowing for better adaptability and generalization.
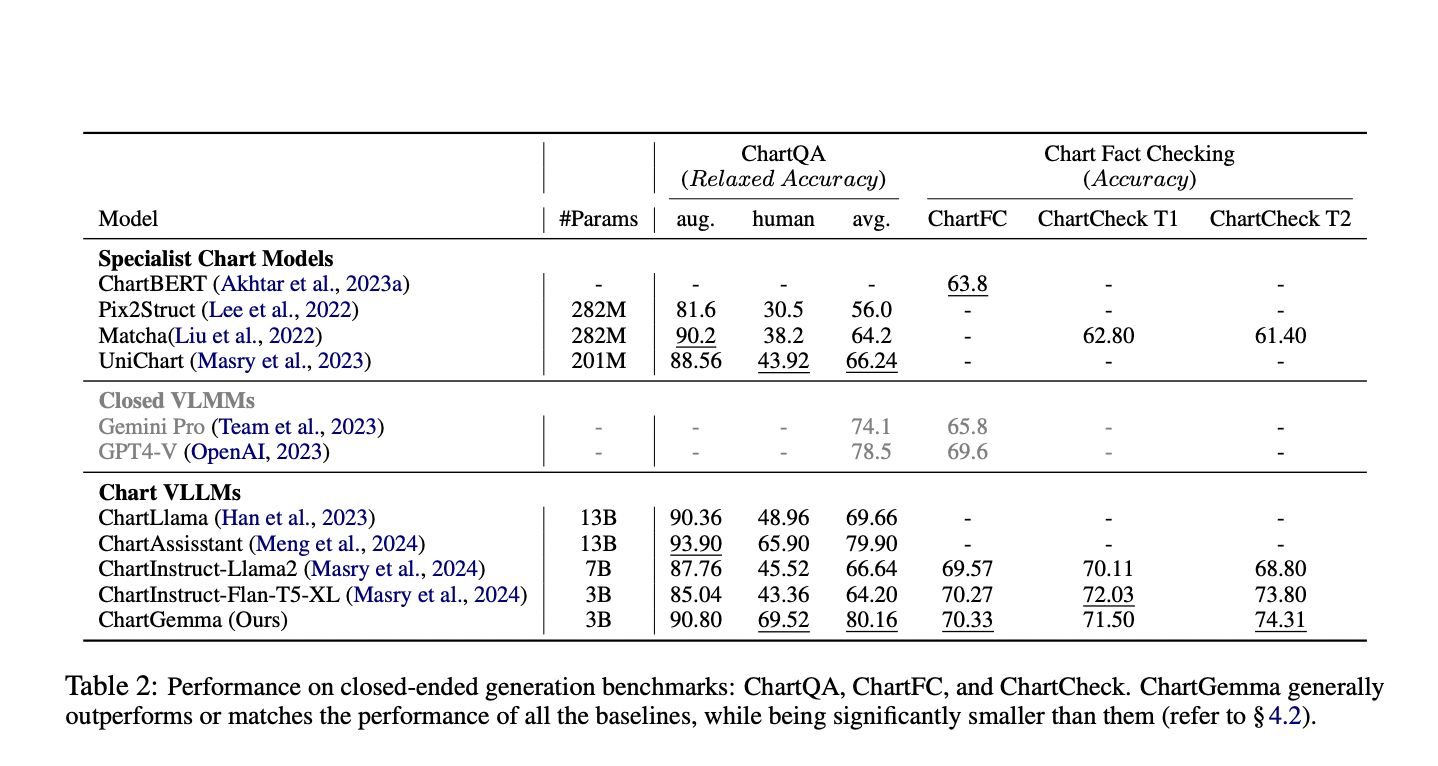
ChartGemma is compared with various open-source chart-specialist models, VLLMs tuned on chart data and state-of-the-art closed-source multimodal LLMs. It is evaluated on five benchmarks assessing chart representation and reasoning abilities: ChartQA, ChartFC, ChartCheck, OpenCQA, and Chart2Text, along with a manually curated set of 100 unseen charts. Performance metrics include relaxed accuracy, accuracy, and GPT-4 judged informativeness and factual correctness. ChartGemma outperforms other models on most tasks, demonstrating superior generalization, especially in understanding realistic instructions and complex charts, despite its relatively small size.
ChartGemma, a multimodal model instruction tuned on data generated from diverse real-world chart images using an advanced backbone architecture, addresses key shortcomings of current models. Unlike existing methods that generate instruction-tuning data from underlying tables and use weakly aligned backbones, ChartGemma uses actual chart images, enhancing adaptability and generalizability. The approach significantly improves performance, producing more realistic, informative, and factually correct outputs with a smaller parameter count. Future work includes creating a more diverse, human-instructed tuning dataset and proposing a generalized benchmark for evaluating complex visual elements in charts with relevant metrics.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post ChartGemma: A Multimodal Model Instruction-Tuned on Data Generated Directly from a Diverse Range of Real-World Chart Images appeared first on MarkTechPost.