
Large language models (LLMs) are a significant advancement in NLP. They are designed to understand, interpret, and generate human language. These models are trained on huge datasets and can perform translation, summarization, and conversational responses. Despite their capabilities, a persistent challenge is enhancing their ability to follow complex instructions accurately and reliably. This challenge is crucial because precise instruction-following is fundamental for practical applications, from customer service bots to advanced AI assistants.
A critical problem in improving LLMs’ instruction-following capabilities is the difficulty in automatically generating high-quality training data without manual annotation. Traditional methods involve human annotators designing instructions and corresponding responses, which is time-consuming and difficult to scale. Additionally, even advanced models from which behavior is imitated can make mistakes, leading to unreliable training data. This limitation hampers the development of models that can execute complex tasks correctly, especially in critical scenarios where errors can have significant consequences.
Current methods to enhance instruction-following abilities include manual annotation and behavior imitation. Manual annotation requires extensive human effort to create diverse and complex instructions, which is challenging due to the limitations of human cognition. Behavior imitation, on the other hand, involves training models to mimic the responses of more advanced LLMs. However, this approach restricts the new models to the capabilities of the source models and does not guarantee accuracy. While powerful, advanced models like GPT-4 are not infallible, errors in their responses can propagate to new models, reducing their reliability.
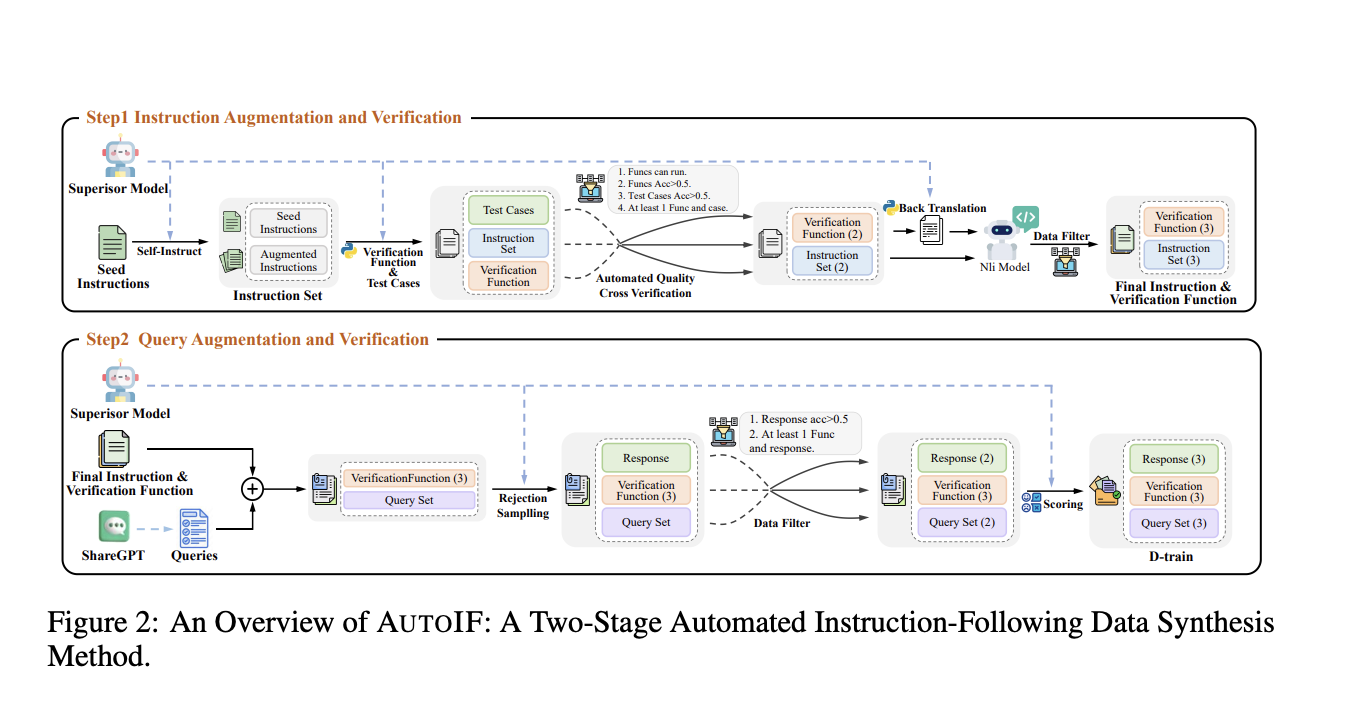
Researchers from Alibaba Inc. have introduced AUTOIF, a novel method designed to address these challenges by automatically generating instruction-following training data. AUTOIF transforms the validation process into code verification, requiring LLMs to create instructions, corresponding code to check response correctness, and unit test samples to verify the code. This approach leverages execution feedback-based rejection sampling to generate data suitable for Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). By automating these steps, AUTOIF eliminates the need for manual annotation, making the process scalable and reliable.
The core idea of AUTOIF involves three main components: generating verifiable instructions, creating verification codes, and ensuring reliability. The method begins with a small set of hand-written seed instructions, augmented by LLMs to produce diverse instructions. Verification codes and unit test cases are then generated for each instruction. If an instruction cannot be verified by code, it is discarded. The process includes generating responses that pass or fail the verification code, which are then used to create training data. This method ensures that only high-quality data is used for training, significantly improving the instruction-following capabilities of LLMs.
The performance of AUTOIF has been rigorously tested, showing substantial improvements across several benchmarks. Applied to open-source LLMs like Qwen2-72B and LLaMA3-70B, AUTOIF achieved Loose Instruction accuracy rates of up to 90.4% on the IFEval benchmark, marking the first instance of surpassing 90% accuracy. In the FollowBench benchmark, the models showed significant improvements, with average increases of over 5% in the SSR metric. Additionally, AUTOIF enabled Qwen2-7B and LLaMA3-8B to achieve average performance gains of over 4% in both benchmarks. Replacing Qwen2-72B and LLaMA3-70B with GPT-4 resulted in further improvements. The researchers have also open-sourced the SFT and DPO datasets constructed using AUTOIF on Qwen2-72B, representing the first open-source complex instruction-following dataset at a scale of tens of thousands.

In conclusion, AUTOIF represents a significant breakthrough in enhancing the instruction-following capabilities of large language models. Automating the generation and verification of instruction-following data addresses previous methods’ scalability and reliability issues. This innovative approach ensures that models can accurately execute complex tasks, making them more effective and reliable in various applications. The extensive testing and notable improvements in benchmarks highlight AUTOIF’s potential to transform the development of LLMs. Researchers have demonstrated that AUTOIF can achieve high-quality, scalable, and reliable instruction-following capabilities, paving the way for more advanced and practical AI applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Alibaba Researchers Introduce AUTOIF: A New Scalable and Reliable AI Method for Automatically Generating Verifiable Instruction Following Training Data appeared first on MarkTechPost.