The concept of Instruction Pre-Training (InstructPT) is a collaborative effort between Microsoft Research and Tsinghua University. This method leverages supervised multitask learning to pre-train language models. Traditional pre-training methods, called Vanilla Pre-Training, rely on unsupervised learning from raw corpora. However, Instruction Pre-Training augments this approach by incorporating instruction-response pairs generated from raw text, enhancing the model’s generalization ability across diverse tasks.
Instruction Pre-Training Framework
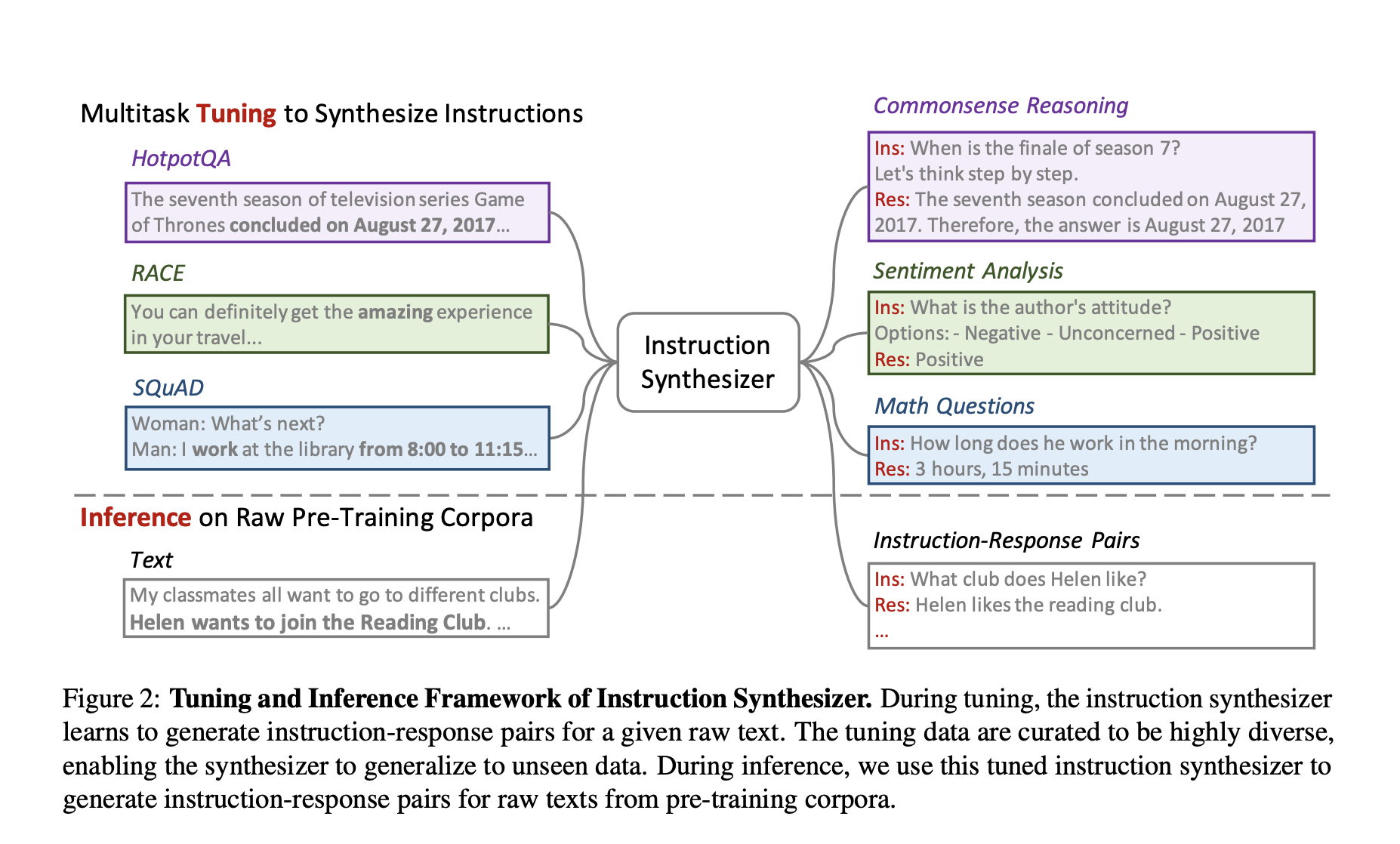
Instruction Pre-Training enriches raw text with synthesized instruction-response pairs before pre-training the language models. This process involves an instruction synthesizer that converts raw corpora into instruction-augmented corpora. The instruction synthesizer is fine-tuned on diverse data, enabling it to generate relevant and diverse instruction-response pairs from unseen raw texts.
The generated pairs are then used to pre-train the LMs, allowing the models to learn from many tasks embedded within the raw text. This supervised multitask learning framework ensures that the pre-trained models improve their base performance and benefit significantly from further instruction tuning.
Experimental Results
The experiments conducted as part of this research demonstrate the effectiveness of Instruction Pre-Training. When pre-training from scratch, models pre-trained using Instruction Pre-Training consistently outperformed those using Vanilla Pre-Training. For instance, a 500M parameter model pre-trained on 100B tokens using Instruction Pre-Training matched the performance of a 1B parameter model pre-trained on 300B tokens using traditional methods.
In domain-adaptive continual pre-training, Instruction Pre-Training significantly enhanced the performance of Llama3-8B models in specialized domains such as finance and biomedicine, enabling them to perform on par with or surpass the larger Llama3-70B models.
Benefits of Instruction Pre-Training
- Enhanced Generalization: Instruction pre-training significantly improves the generalization capabilities of LMs by incorporating a variety of tasks framed through natural language instructions. This is particularly beneficial for models that need to perform well across diverse and unseen tasks.
- Efficiency in Pre-Training: The instruction synthesizer, built on open-source models with approximately 7 billion parameters, is cost-effective and scalable. This efficiency generates a large volume of high-quality synthetic data, making the pre-training process more resource-efficient.
- Improved Task Performance: Models pre-trained with instruction-augmented data show superior performance on various benchmarks in both zero-shot and few-shot settings. This indicates that including instruction-response pairs helps models better understand and execute complex tasks.
Variants of InstructPT
The Instruction Pre-Training framework has been adapted to create several variants, each tailored to specific domains and tasks:
- instruction-pretrain/medicine-Llama3-8B: This variant is tailored for biomedical applications, leveraging domain-specific data to enhance performance in medical tasks.
- instruction-pretrain/InstructLM-1.3B: A mid-sized model suitable for general-purpose applications, balancing performance and computational requirements.
- instruction-pretrain/instruction-synthesizer: The core component responsible for generating instruction-response pairs, pivotal to the success of Instruction Pre-Training.
- instruction-pretrain/InstructLM-500M: A smaller, more efficient model designed for environments with limited computational resources.
- instruction-pretrain/finance-Llama3-8B: Optimized for financial tasks, this variant utilizes financial news and data to improve performance in finance-related applications.
The datasets used for fine-tuning and evaluation, such as the instruction-pretrain/ft-instruction-synthesizer-collection, play a crucial role in ensuring the diversity and quality of the synthetic data generated by the instruction synthesizer.
Conclusion
Instruction Pre-Training by integrating supervised multitask learning into the pre-training process enhances the base performance of language models and significantly improves their ability to generalize across various tasks. The success of this method, as demonstrated by the performance of Llama3-8B and other variants, underscores its potential to drive future innovations in artificial intelligence and natural language processing.
Check out the Paper and Models. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Microsoft AI Release Instruct Pre-Training: Enhancing Language Model Pre-Training with Supervised Multitask Learning appeared first on MarkTechPost.