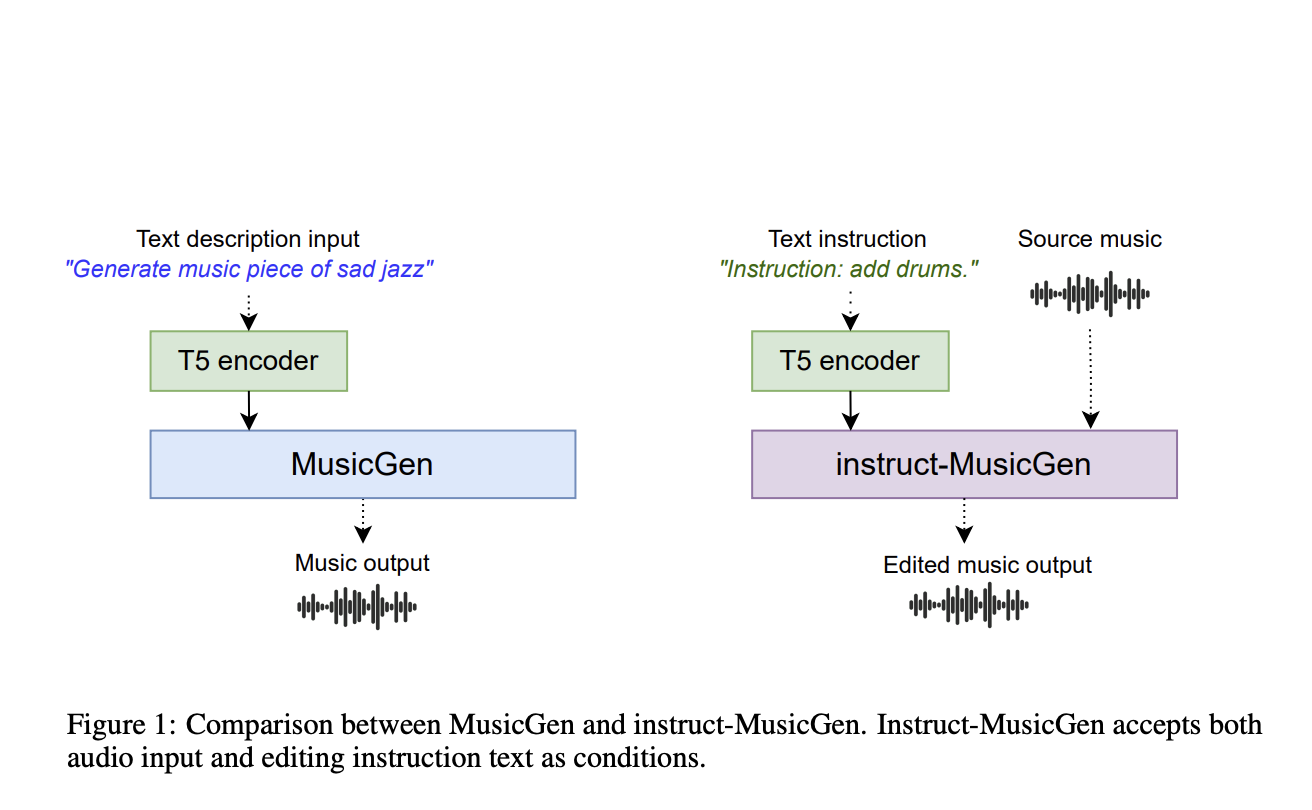

Researchers from C4DM, Queen Mary University of London, Sony AI, and Music X Lab, MBZUAI, have introduced Instruct-MusicGen to address the challenge of text-to-music editing, where textual queries are used to modify music, such as changing its style or adjusting instrumental components. Current methods are required to train specific models from scratch, are resource-intensive, and need some approaches to reconstruct edited audio, leading to subpar results precisely. The study aims to develop a more efficient and effective method that leverages pre-trained models to perform high-quality music editing based on textual instructions.
Current methods for text-to-music editing include training specialized models from scratch, which is inefficient and resource-heavy, and using large language models to interpret and edit music, often resulting in imprecise audio reconstruction. These methods are either too costly or fail to deliver accurate results. To overcome these challenges, the researchers propose Instruct-MusicGen, a novel approach that fine-tunes a pre-trained MusicGen model to follow editing instructions efficiently. This approach introduces a text fusion module and an audio fusion module to the original MusicGen architecture, allowing it to process instruction texts and audio inputs concurrently. Instruct-MusicGen significantly reduces the need for extensive training and additional parameters while achieving superior performance across various tasks.
Instruct-MusicGen enhances the original MusicGen model by incorporating two new modules: the audio fusion module and the text fusion module. The audio fusion module allows the model to accept and process external audio inputs, enabling precise audio editing. This is achieved by duplicating self-attention modules and incorporating cross-attention between the original music and the conditional audio. The text fusion module modifies the behavior of the text encoder to handle instruction inputs, allowing the model to follow text-based editing commands effectively. The combined modules enable Instruct-MusicGen to add, separate, and remove stems from music audio based on textual instructions.
The model was trained using a synthesized dataset created from the Slakh2100 dataset, which includes high-quality audio tracks and corresponding MIDI files. The training process was optimized to require only 8% additional parameters compared to the original MusicGen model and completed within 5,000 steps, significantly reducing resource usage. The performance of Instruct-MusicGen was evaluated on two datasets: the Slakh test set and the out-of-domain MoisesDB dataset. The model outperformed existing baselines in various tasks, demonstrating its efficiency and effectiveness in text-to-music editing. It achieved superior audio quality, alignment with textual descriptions, and signal-to-noise ratio improvements.
In conclusion, Instruct-MusicGen addresses the limitations of existing methods in text-to-music editing by leveraging pre-trained models and proposing efficient training techniques. The proposed approach significantly reduces the computational resources required and achieves high-quality results in music editing tasks. While it performs well across various metrics, some limitations remain, such as relying on synthetic training data and potential inaccuracies in signal-level precision. The development of Instruct-MusicGen marks a meaningful step forward in the field of AI-assisted music creation, combining efficiency with high performance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Instruct-MusicGen: A Novel Artificial Intelligence AI Approach to Text-to-Music Editing that Fosters Joint Musical and Textual Controls appeared first on MarkTechPost.