Large language models (LLMs) have revolutionized code generation, but their autoregressive nature poses a significant challenge. These models generate code token by token, without access to the program’s runtime output from the previously generated tokens. This lack of a feedback loop, where the model can observe the program’s output and adjust accordingly, makes it difficult to correct errors. While LLMs can be trained to suggest edits to existing code, acquiring sufficient high-quality training data for this task remains an obstacle. Researchers are striving to overcome these limitations and develop more effective methodologies for utilizing LLMs in code generation and error correction.
Several existing approaches have tackled the challenges of code generation and error correction. Neural program synthesis methods generate programs from input-output examples, combining neural networks with search strategies. While effective, these techniques construct programs incrementally, exploring a vast space of partial programs. Neural diffusion models have shown impressive results for generative modeling of high-dimensional data like images. Recent work has extended diffusion to discrete and structured data such as graphs and molecules. Direct code editing using neural models has also been explored, training on datasets of real-world code patches or fine-tuning language models. However, these methods often require extensive code edit datasets or lack inherent guarantees of syntactic validity.
University of California, Berkeley researchers introduce an effective approach to program synthesis using neural diffusion models that operate directly on syntax trees. Utilizing diffusion allows the model to iteratively refine programs while ensuring syntactic validity. Crucially, the approach enables the model to observe the program’s output at each step, effectively facilitating a debugging process. Inspired by systems like AlphaZero, the iterative nature of diffusion lends itself well to search-based program synthesis. By training a value model alongside the diffusion model, the denoising process can be guided towards programs likely to achieve the desired output, enabling efficient exploration of the program space.
The core idea of this method is to develop denoising diffusion models for syntax trees, analogous to image diffusion models. Using context-free grammar (CFG), the method defines a noising process that randomly mutates programs while ensuring syntactic validity. This involves sampling mutations by constraining the program “size” within a range and replacing subtrees with alternate subtrees derived from the CFG’s production rules. A neural network is then trained to reverse this noising process, learning to denoise programs conditioned on the target program output (e.g., rendered image). Also, a value network is trained to predict edit distances between programs, enabling efficient beam search exploration guided by promising candidate programs.
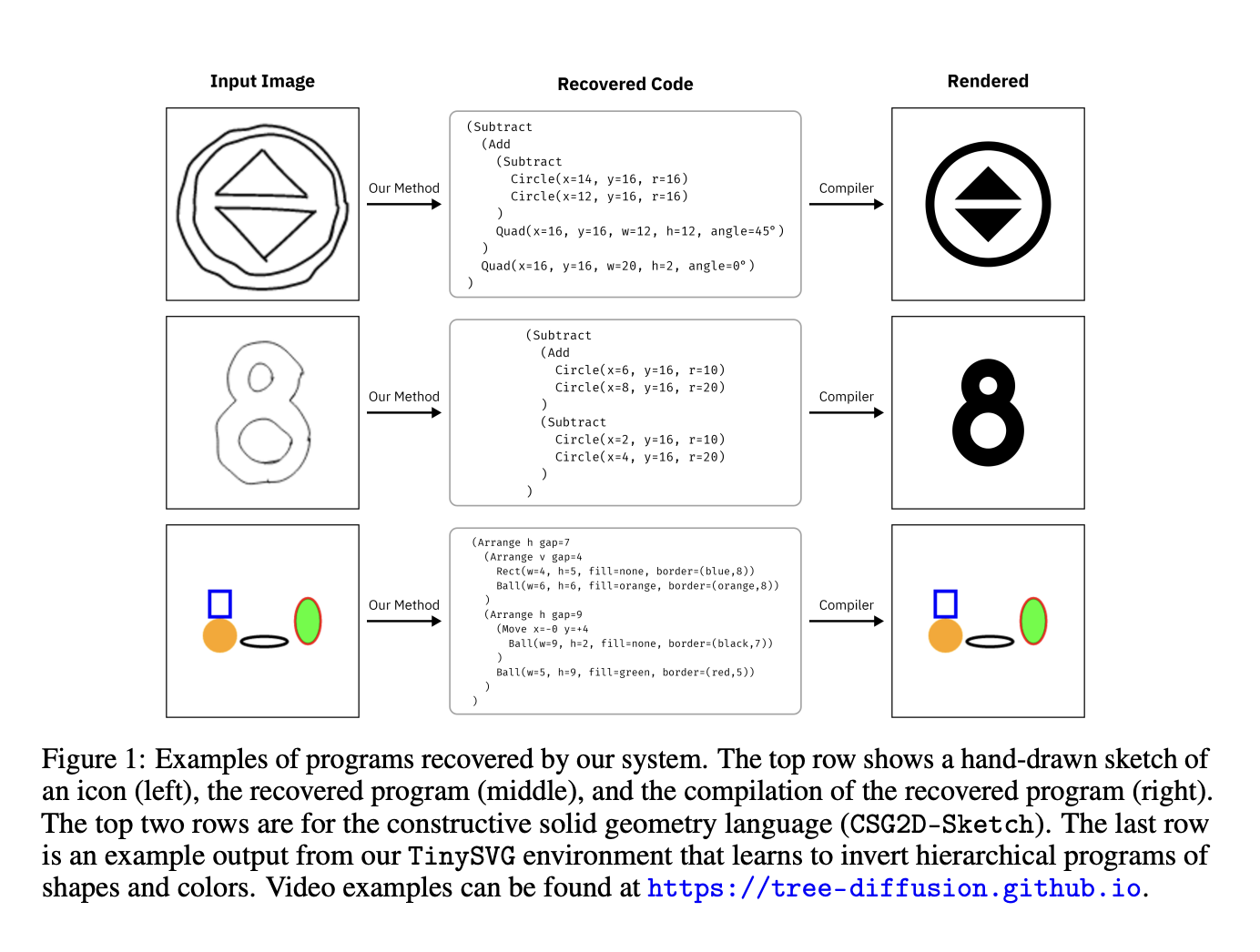
This method significantly outperforms two baseline approaches – CSGNet and REPL Flow – on inverse graphics tasks in the CSG2D and TinySVG domains. CSGNet represents a modern autoregressive approach, generating programs autoregressively until a match is found. REPL Flow is based on prior work building programs primitively with access to intermediate rendered outputs. Across both domains, the diffusion policy with beam search solves problems with fewer renderer calls than the baselines. Qualitative examples highlight the method’s ability to fix smaller issues missed by other approaches. Beyond that the observation model can handle stochastic hand-drawn sketches, successfully recovering programs from noisy sketch inputs.
This research work introduced a robust neural diffusion model that operates directly on syntax trees for program synthesis. The proposed approach was successfully implemented for inverse graphics tasks, aiming to find programs that render a given target image. Unlike prior methods, the model can iteratively construct, execute, and edit programs, enabling a crucial feedback loop to correct mistakes. Comprehensive evaluations across graphics domains demonstrated the superiority of this approach over baseline methods for inverse graphics program synthesis. Also, ablation experiments provided insights into the impact of key design choices behind the diffusion model’s architecture and training process.
Check out the Paper, Project, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Researchers at UC Berkeley Propose a Neural Diffusion Model that Operates on Syntax Trees for Program Synthesis appeared first on MarkTechPost.