Language models (LMs) are designed to reflect a broad range of voices, leading to outputs that don’t perfectly match any single perspective. To avoid generic responses, one can use LLMs through supervised fine-tuning (SFT) or reinforcement learning with human feedback (RLHF). However, these methods need huge datasets, making them impractical for new and specific tasks. Moreover, there is often a mismatch between the universal style trained into an LLM through instruction and preference tuning needed for specific applications. This mismatch results in LLM outputs feeling generic and lacking a distinctive voice.
Several methods have been developed to address these challenges. One of the approaches involves LLMs and Preference Finetuning in which LLMs are trained on huge datasets to perform well with careful prompting. However, designing prompts can be difficult and sensitive to variations, so it is often necessary to finetune these models on large datasets and use RLHF. Another strategy is self-improvement, where iterative sampling is used to enhance LLMs. For example, methods like STaR are supervised by verifying the correctness of its outputs. Lastly, Online Imitation Learning can improve a policy beyond the demonstrator’s performance. However, these approaches need to learn a reward function and are not applicable to LLMs.
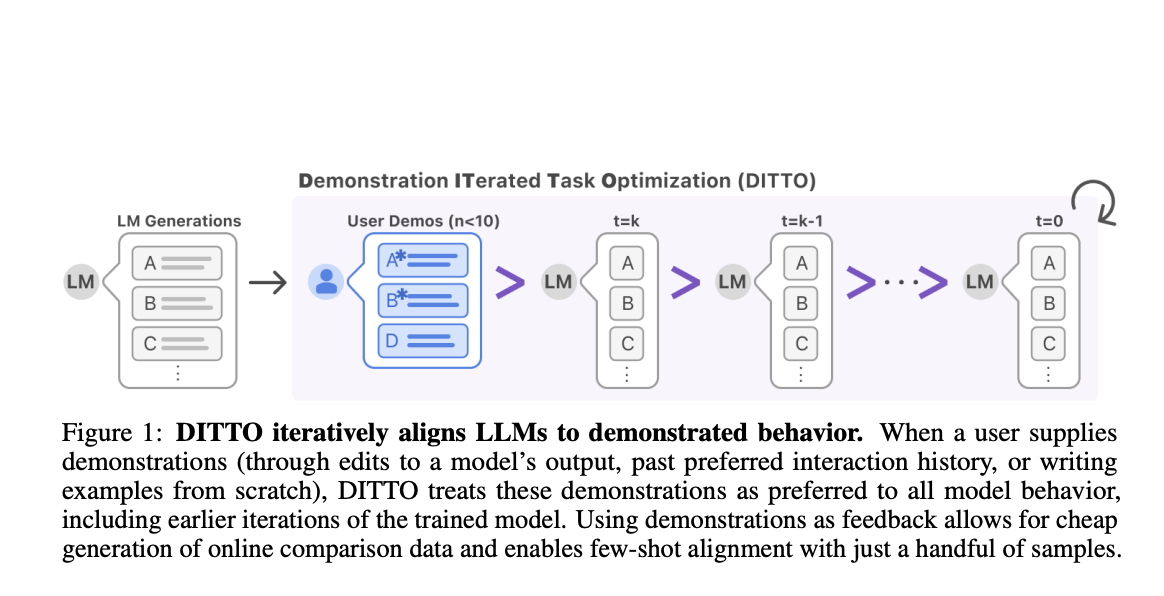
Researchers from Standford University have introduced Demonstration ITerated Task Optimization (DITTO), a method that aligns language model outputs directly with the user’s demonstrated behaviors. It is derived using ideas from online imitation learning and can generate online comparison data at a low cost. To generate these data, DITTO prioritizes users’ demonstrations over output from the LLM and its intermediate checkpoints. Moreover, the win rates of this method outperform few-shot prompting, supervised fine-tuning, and other self-play methods by an average of 19% points. Also, it provides a novel way to effectively customize LLMs using direct feedback from demonstrations.
DITTO is capable of learning fine-grained style and task alignment across domains like news articles, emails, and blog posts. It is an iterative process that contains three components: (a) On the set of expert demonstrations, supervised fine-tuning is executed for a limited number of gradient steps; (b) a New dataset is constructed during the training process by sampling completions for each demonstration and adding it to the ranking over policies, and (c) RLHF is used for updating the policy, particularly using batches sampled through the previously mentioned process.
The results of DITTO is evaluated with GPT-4 eval and averaged across all authors, where it outperforms all baselines with an average win rate of 77.09% across CMCC (71.67%) and CCAT50 (82.50%). It provides an average increase of 11.7% win rate as compared to SFT which serves as a strong baseline (56.78% on CMCC, 73.89% on CCAT). Further, in user study results, DITTO outperforms baseline methods with DITTO (72.1% win-rate) > SFT (60.1%) > few-shot (48.1%) > self-prompt (44.2%) > zero-shot (25.0%). Also, self-promoting performs a little worse than giving examples in a few-shot prompt and underperforms DITTO.
In conclusion, researchers from Standford University have introduced Demonstration ITerated Task Optimization (DITTO), a method that aligns language model outputs directly with the user’s demonstrated behaviors and generates online comparison data from demonstrations. In this paper, researchers highlighted the importance of using demonstrations as feedback and proved that even a small number of demonstrated behaviors can provide a strong signal of an individual’s specific preferences. However, other model sizes are not tested by researchers because of computational cost, and additional analysis is needed by the types of preference data needed. So, there is a need for future work in this domain.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Demonstration ITerated Task Optimization (DITTO): A Novel AI Method that Aligns Language Model Outputs Directly with User’s Demonstrated Behaviors appeared first on MarkTechPost.