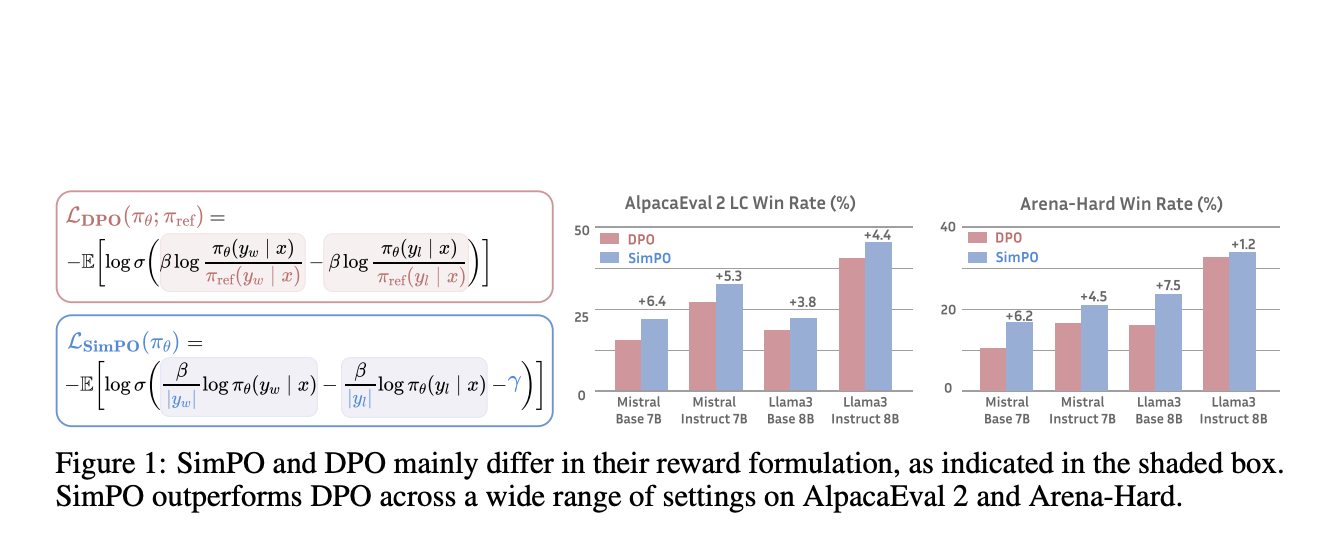
Artificial intelligence is continually evolving, focusing on optimizing algorithms to improve the performance and efficiency of large language models (LLMs). Reinforcement learning from human feedback (RLHF) is a significant area within this field, aiming to align AI models with human values and intentions to ensure they are helpful, honest, and safe.
One of the primary challenges in RLHF is optimizing the reward functions used in reinforcement learning. Traditional methods involve complex, multi-stage processes that require substantial computational resources and may lead to suboptimal performance due to discrepancies between training and inference metrics. These processes often include training a reward model separately from the policy model, which can introduce inefficiencies and potential mismatches in optimization objectives.
Existing research includes Direct Preference Optimization (DPO), which reparameterizes reward functions in RLHF to simplify processes and enhance stability. DPO removes the need for explicit reward models but still requires a reference model, adding computational overhead. Other methods include IPO, KTO, and ORPO, which offer variations on preference data handling and optimization without reference models. These approaches aim to streamline RLHF by addressing the complexities and inefficiencies inherent in traditional methods, providing more efficient and scalable solutions for aligning large language models with human feedback.
Researcher from the University of Virginia and Princeton University have introduced SimPO, a simpler and more effective approach to preference optimization. SimPO utilizes the average log probability of a sequence as the implicit reward, aligning better with model generation and removing the need for a reference model. This makes SimPO more compute and memory efficient. SimPO is designed to directly align the reward function with the generation likelihood, eliminating discrepancies between training and inference metrics. The method also incorporates a target reward margin to ensure a significant difference between winning and losing responses, which enhances performance stability.
SimPO’s core innovation is using a length-normalized reward, calculated as the average log probability of all tokens in a response. This approach ensures the reward aligns with the generation metric, enhancing the model’s performance. Additionally, SimPO introduces a target reward margin to the Bradley-Terry objective to encourage a larger margin between winning and losing responses. This margin is crucial as it promotes the generation of higher-quality sequences without exploiting response length, a common issue in previous models. The research team meticulously tuned the parameters for optimal performance across training setups, including base and instruction-tuned models like Mistral and Llama3.
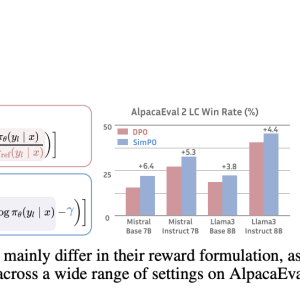
SimPO significantly outperforms DPO and its latest variants across various training setups, including base and instruction-tuned models. On the AlpacaEval 2 benchmark, SimPO outperformed DPO by up to 6.4 points, demonstrating a substantial improvement in generating accurate and relevant responses. SimPO showed an even more impressive performance on the challenging Arena-Hard benchmark, surpassing DPO by up to 7.5 points. The top-performing model, built on Llama3-8B-Instruct, achieved a remarkable 44.7% length-controlled win rate on AlpacaEval 2, outperforming Claude 3 Opus on the leaderboard, and a 33.8% win rate on Arena-Hard, making it the strongest 8B open-source model to date. These results highlight SimPO’s robustness and effectiveness in diverse settings and benchmarks.
SimPO’s practicality is a key advantage. It utilizes preference data more effectively, leading to a more accurate likelihood ranking of winning and losing responses on a held-out validation set. This translates to a better policy model, capable of generating high-quality responses consistently. The efficiency of SimPO also extends to its computational requirements, reducing the need for extensive memory and computational resources typically associated with reference models. This makes SimPO not only a powerful but also a practical solution for large-scale model training and deployment, providing reassurance about its feasibility and applicability in real-world scenarios.
To conclude, SimPO represents a significant advancement in preference optimization for RLHF, offering a simpler, more efficient method that consistently delivers superior performance. By eliminating the need for a reference model and aligning the reward function with the generation metric, SimPO addresses key challenges in the field, providing a robust solution for enhancing the quality of large language models. The introduction of a target reward margin further ensures that the generated responses are not only relevant but also of high quality, making SimPO a valuable tool for future AI developments.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Beyond the Reference Model: SimPO Unlocks Efficient and Scalable RLHF for Large Language Models appeared first on MarkTechPost.