
Hugging Face has introduced FineWeb, a comprehensive dataset designed to enhance the training of large language models (LLMs). Published on May 31, 2024, this dataset sets a new benchmark for pretraining LLMs, promising improved performance through meticulous data curation and innovative filtering techniques.
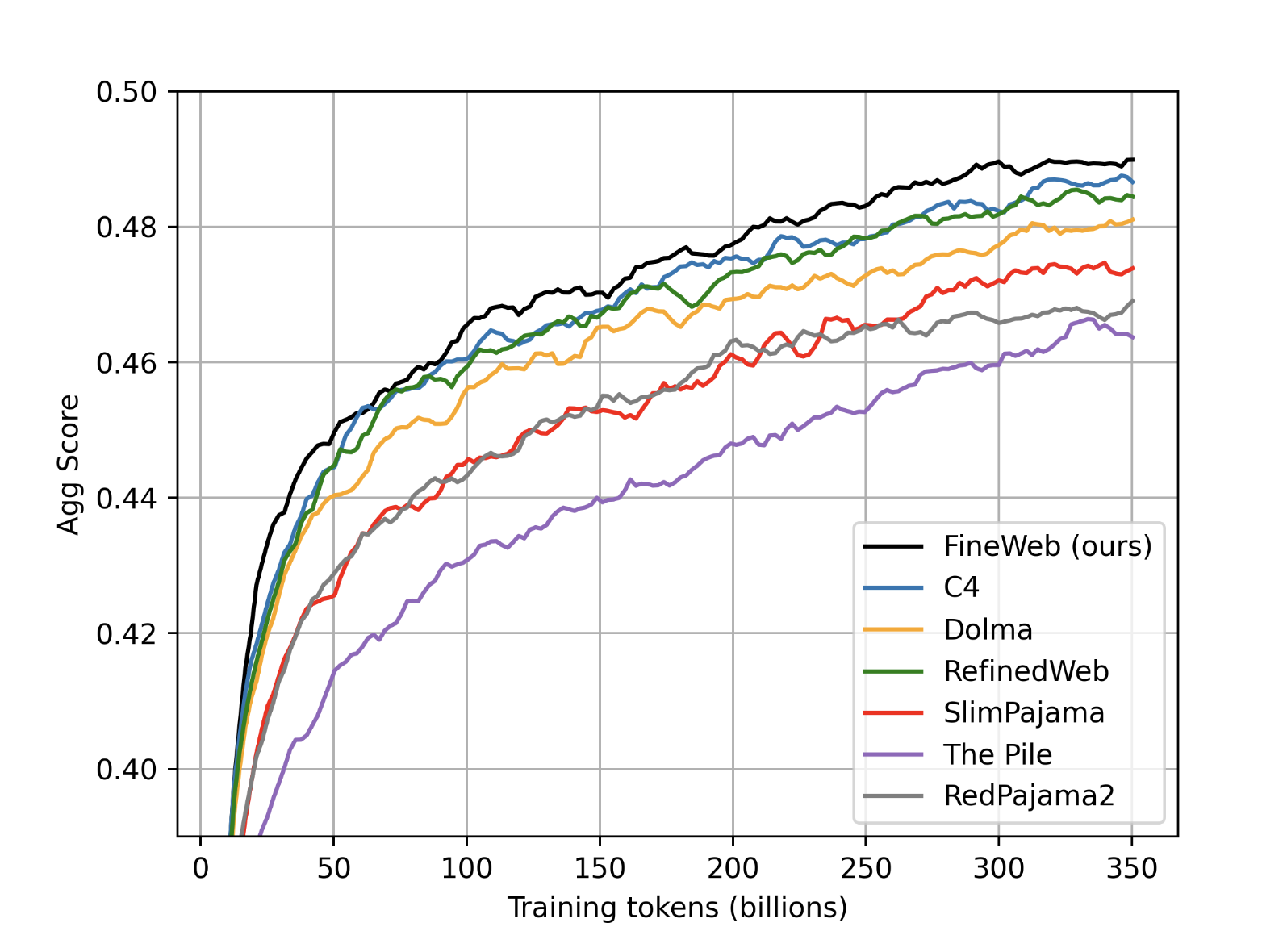
FineWeb draws from 96 CommonCrawl snapshots, encompassing a staggering 15 trillion tokens and occupying 44TB of disk space. CommonCrawl, a non-profit organization that has been archiving the web since 2007, provided the raw material for this dataset. Hugging Face leveraged these extensive web crawls to compile a rich and diverse dataset, aiming to surpass the capabilities of previous datasets like RefinedWeb and C4.
One of the standout features of FineWeb is its rigorous deduplication process. Using MinHash, a fuzzy hashing technique, the team at Hugging Face ensured that redundant data was effectively eliminated. This process improves the model’s performance by reducing duplicate content memorization and enhancing training efficiency. The dataset underwent individual and global deduplication, with the former proving more beneficial in retaining high-quality data.
Quality is a cornerstone of FineWeb. The dataset employs advanced filtering strategies to remove low-quality content. Initial steps involved language classification and URL filtering to exclude non-English text and adult content. Building on the foundation laid by C4, additional heuristic filters were applied, such as removing documents with excessive boilerplate content or those failing to end lines with punctuation.
Accompanying the primary dataset, Hugging Face introduced FineWeb-Edu, a subset tailored for educational content. This subset was created using synthetic annotations generated by Llama-3-70B-Instruct, which scored 500,000 samples on their academic value. A classifier trained on these annotations was then applied to the full dataset, filtering out non-educational content. The result is a dataset of 1.3 trillion tokens optimized for educational benchmarks such as MMLU, ARC, and OpenBookQA.
FineWeb-Edu, in particular, showed remarkable improvements, demonstrating the effectiveness of synthetic annotations for high-quality educational content filtering.
Hugging Face’s release of FineWeb marks a pivotal moment in the open science community. It provides researchers and users with a powerful tool to train high-performance LLMs. The dataset, released under the permissive ODC-By 1.0 license, is accessible for further research and development. Looking ahead, Hugging Face aims to extend the principles of FineWeb to other languages, thus broadening the impact of high-quality web data across diverse linguistic contexts.
The post HuggingFace Releases 🍷 FineWeb: A New Large-Scale (15-Trillion Tokens, 44TB Disk Space) Dataset for LLM Pretraining appeared first on MarkTechPost.