Imagine you’re trying to help a friend find their favorite movie to watch, but they’re not quite sure what they’re in the mood for. You could list random movie titles and see if any pique their interest, but that’s pretty inefficient, right? The researchers behind this work had a similar problem – they wanted to build conversational recommender systems that can quickly learn a user’s preferences for items (like movies, restaurants, etc.) through natural language dialogues without needing any prior data about those preferences.
The traditional approach would be to have the user rate or compare items directly. But that’s not feasible when the user is unfamiliar with most of the items. Large language models (LLMs) like GPT-3 can be a potential solution because these powerful AI models can understand and generate human-like text, so in theory, they could engage in back-and-forth conversations to intuitively elicit someone’s preferences.
However, the researchers realized that simply prompting an LLM with a bunch of item descriptions and telling it to have a preference-eliciting conversation has some major limitations. For one, feeding the LLM detailed descriptions of every item is computationally expensive. More importantly, monolithic LLMs lack the strategic reasoning to actively guide the conversation toward exploring the most relevant preferences while avoiding getting stuck on irrelevant tangents.
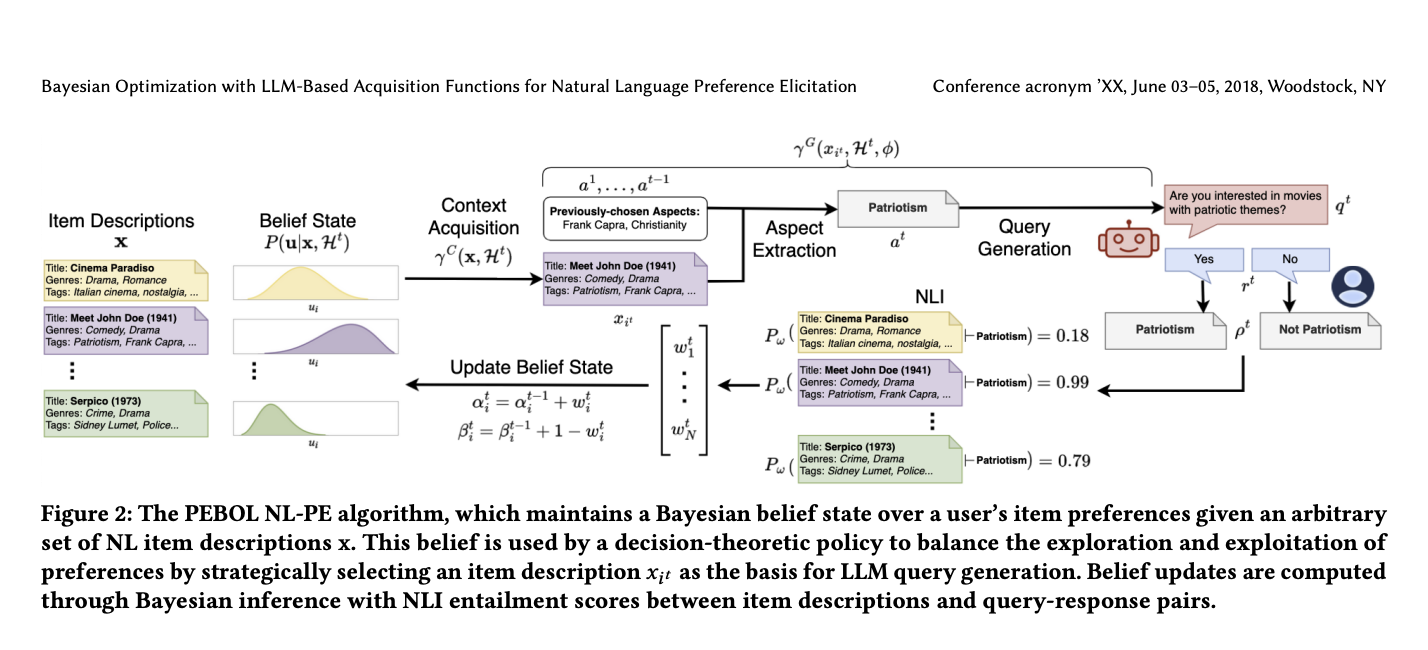
So, what did the researchers do? They developed a novel algorithm called PEBOL (Preference Elicitation with Bayesian Optimization Augmented LLMs) that combines the language understanding capabilities of LLMs with a principled Bayesian optimization framework for efficient preference elicitation. Here’s a high-level overview of how it works (shown in Figure 2):
1. Modeling User Preferences: PEBOL starts by assuming there’s some hidden “utility function” that determines how much a user would prefer each item based on its description. It uses probability distributions (specifically, Beta distributions) to model the uncertainty in these utilities.
2. Natural Language Queries: At each conversation turn, PEBOL uses decision-theoretic strategies like Thompson Sampling and Upper Confidence Bound to select one item description. It then prompts the LLM to generate a short, aspect-based query about that item (e.g., “Are you interested in movies with patriotic themes?”).
3. Inferring Preferences via NLI: When the user responds (e.g., “Yes” or “No”), PEBOL doesn’t take that at face value. Instead, it uses a Natural Language Inference model to predict how likely it is that the user’s response implies a preference for (or against) each item description.
4. Bayesian Belief Updates: Using these predicted preferences as observations, PEBOL updates its probabilistic beliefs about the user’s utilities for each item. This allows it to systematically explore unfamiliar preferences while exploiting what it’s already learned.
5. Repeat: The process repeats, with PEBOL generating new queries focused on the items/aspects it’s most uncertain about, ultimately aiming to identify the user’s most preferred items.
The key innovation here is using LLMs for natural query generation while leveraging Bayesian optimization to strategically guide the conversational flow. This approach reduces the context needed for each LLM prompt and provides a principled way to balance the exploration-exploitation trade-off.
The researchers evaluated PEBOL through simulated preference elicitation dialogues across three datasets: MovieLens25M, Yelp, and Recipe-MPR. They compared it against a monolithic GPT-3.5 baseline (MonoLLM) prompted with full item descriptions and dialogue history.
For fair comparison, they limited the item set size to 100 due to context constraints. Performance was measured by Mean Average Precision at 10 (MAP@10) over 10 conversational turns with simulated users.
In their experiments, PEBOL achieved MAP@10 improvements of 131% on Yelp, 88% on MovieLens, and 55% on Recipe-MPR over MonoLLM after just 10 turns. While MonoLLM exhibited major performance drops (e.g., on Recipe-MPR between turns 4-5), PEBOL’s incremental belief updates made it more robust against such catastrophic errors. PEBOL also consistently outperformed MonoLLM under simulated user noise conditions. On Yelp and MovieLens, MonoLLM was the worst performer across all noise levels, while on Recipe-MPR, it trailed behind PEBOL’s UCB, Greedy, and Entropy Reduction acquisition policies.
While PEBOL is a promising first step, the researchers acknowledge there’s still more work to be done. For example, future versions could explore generating contrastive multi-item queries or integrating this preference elicitation approach into broader conversational recommendation systems. But overall, by combining the strengths of LLMs and Bayesian optimization, PEBOL offers an intriguing new paradigm for building AI systems that can converse with users in natural language to understand their preferences better and provide personalized recommendations.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
The post Bayesian Optimization for Preference Elicitation with Large Language Models appeared first on MarkTechPost.