The burgeoning expansion of the data landscape, propelled by the Internet of Things (IoT), presents a pressing challenge: ensuring data quality amidst the deluge of information. With IoT devices increasingly interconnected and data acquisition costs declining, enterprises are capitalizing on this wealth of data to inform strategic decisions.
However, the quality of that data is paramount, especially given the escalating reliance on Machine Learning (ML) across various industries. Poor-quality training data can introduce biases and inaccuracies, undermining the efficacy of ML applications. Real-world data often harbors inaccuracies such as duplications, null entries, anomalies, and inconsistencies, posing significant obstacles to data quality.
Efforts to mitigate data quality issues have led to the development of automated data cleaning tools. However, many of these tools need more context awareness, which is crucial for effectively cleaning data within ML workflows. Contextual information elucidates the data’s meaning, relevance, and relationships, ensuring alignment with real-world phenomena.
Context-aware data cleaning tools offer promise, leveraging Ontological Functional Dependencies (OFDs) extracted from context models. OFDs provide an advanced mechanism for capturing semantic relationships between attributes, enhancing error detection and correction precision.
Despite the efficacy of OFD-based cleaning tools, manual construction of context models presents practical challenges, particularly for real-time applications. The labor-intensive nature of manual methods, coupled with the need for domain expertise and scalability concerns, underscores the necessity for automation.
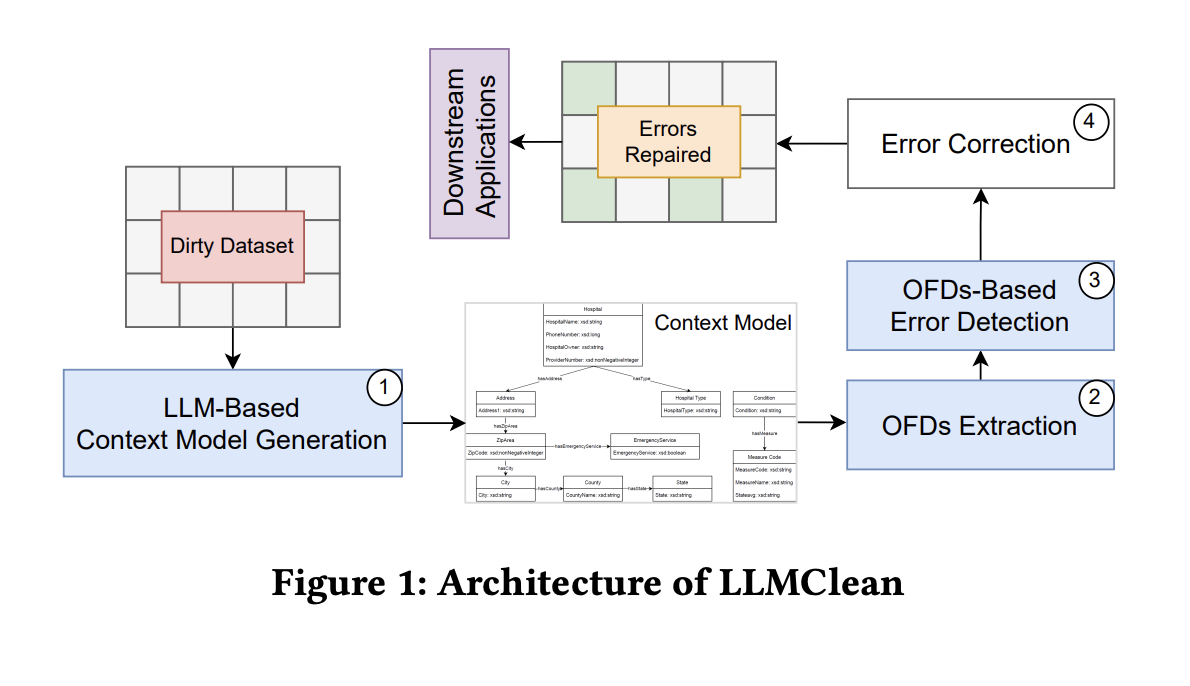
In response, the proposed solution, LLMClean, leverages large language models (LLMs) to automatically generate context models from real-world data, obviating the need for supplementary meta-information. By automating this process, LLMClean addresses the scalability, adaptability, and consistency challenges inherent in manual methods.
LLMClean encompasses a three-stage architectural framework, integrating LLM models, context models, and data-cleaning tools to effectively identify erroneous instances in tabular data. The method includes dataset classification, model extraction or mapping, and context model generation.
By leveraging automatically generated OFDs, LLMClean provides a robust data cleaning and analytical framework tailored to the evolving nature of real-world data, including IoT datasets. Additionally, LLMClean introduces Sensor Capability Dependencies and Device-Link Dependencies, which are critical for precise error detection.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
The post LLMClean: An AI Approach for the Automated Generation of Context Models Utilizing Large Language Models to Analyze and Understand Various Datasets appeared first on MarkTechPost.