Reinforcement learning (RL) is a type of learning approach where an agent interacts with an environment to collect experiences and aims to maximize the reward received from the environment. This usually involves a looping process of experience collecting and enhancement, and due to the requirement of policy rollouts, it is called online RL. Both on-policy and off-policy RL need online interaction, which can be impractical in certain domains due to experimental or environmental constraints. Offline RL algorithms are framed so that they can extract optimal policies from static datasets.
Offline RL algorithms are used to learn effective and well-applicable policies with the help of static datasets. Many approaches to this algorithm have achieved major success recently. However, they demand significant hyperparameter tuning specific to each dataset to achieve reported performance, which needs policy rollouts in the environment to evaluate. This can create a major problem because the need for significant tuning can affect the adoption of these algorithms in practical domains. Offline RL faces challenges during the evaluation of out-of-distribution (OOD) actions.
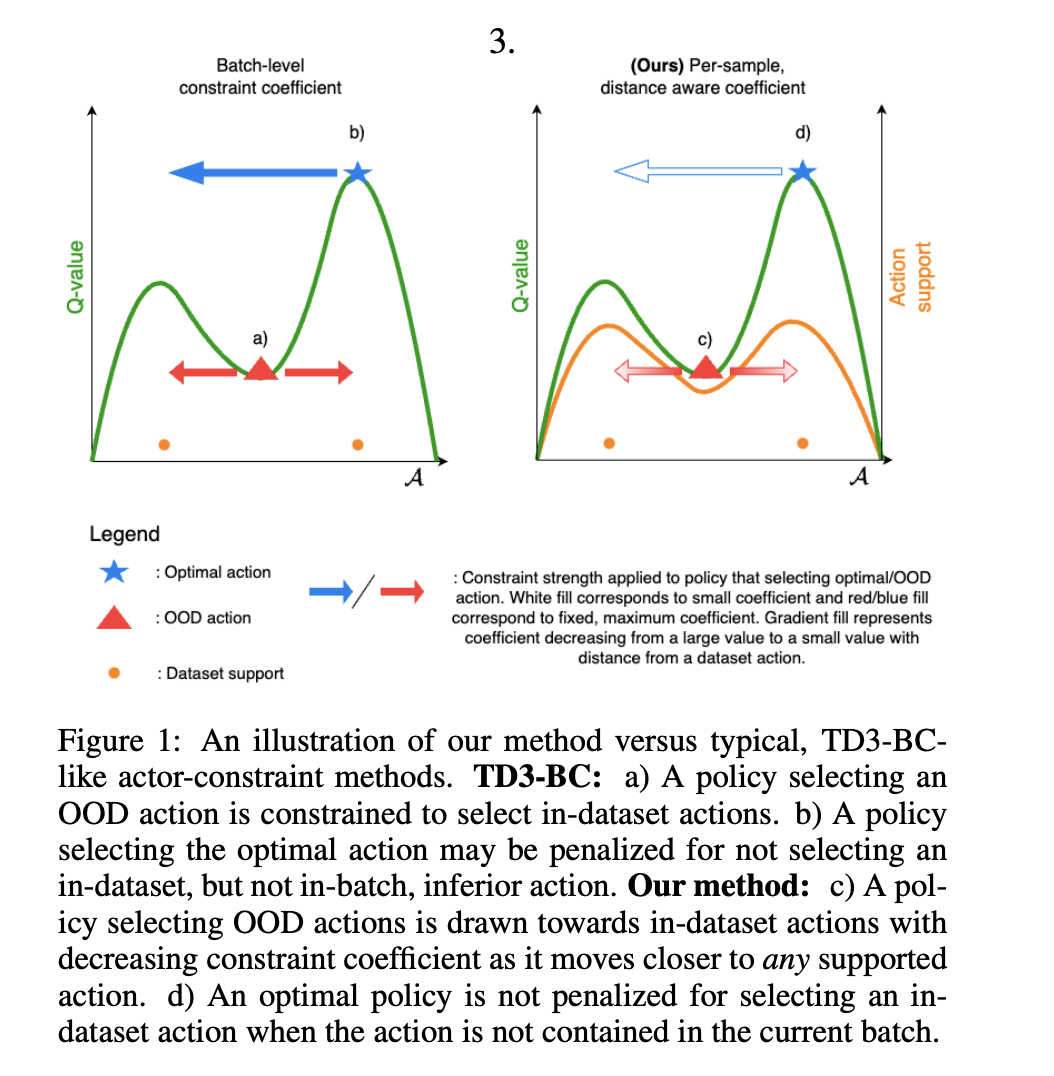
Researchers from Imperial College London introduced TD3-BST (TD3 with Behavioral Supervisor Tuning), an algorithm that uses an uncertainty model to adjust the strength of regularization dynamically. The trained uncertainty model is incorporated into the regularized policy yield TD3 with behavioral supervisor tuning (TD3-BST). TD3-BST helps adjust regularization dynamically using an uncertainty network, helping the learned policy optimize Q-values around dataset modes. TD3-BST outperforms other methods, showcasing state-of-the-art performance when tested on D4RL datasets.
Tuning TD3-BST is simple and straight, which involves selecting the choice and scale of the kernel (λ), along with the temperature, using primary hyperparameters of the Morse network. For high-dimensional actions, increasing λ helps hold the region around modes tight. Training with Morse-weighted behavioral cloning (BC) reduces the impact of BC loss for distant modes, allowing the policy to focus on selecting and optimizing errors for a single mode. Moreover, the study has proven the importance of letting some OOD actions in the TD3-BST framework, and it depends on λ.
Simple versions of RL, called One-step algorithms, have the potential to learn a policy from an offline dataset. They depend on weighted BC, which has some limitations, and to improve the performance, relaxing the policy objective will play a major role. A BST objective is integrated into an existing IQL algorithm to overcome this issue and learn an optimal policy while retaining an in-sample policy evaluation. This new approach, IQL-BST, is tested using the same setup as the original IQL, and the results obtained match closely with the original IQL with a very slight drop in performance on larger datasets. However, relaxing weighted BC with a BST objective performs well, especially on difficult-medium and large datasets.
In conclusion, researchers from Imperial College London introduced TD3-BST, an algorithm that uses an uncertainty model to adjust the strength of regularization dynamically. On comparing with previous methods in Gym Locomotion tasks, TD3-BST achieves the best score resulting in strong performance when learning from suboptimal data. In addition, integrating policy regularization with an ensemble-based source of uncertainty enhances the performance. Future work includes: working on different methods to estimate uncertainty, alternative uncertainty measures, and the best way to combine multiple sources of uncertainty.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post TD3-BST: A Machine Learning Algorithm to Adjust the Strength of Regularization Dynamically Using Uncertainty Model appeared first on MarkTechPost.