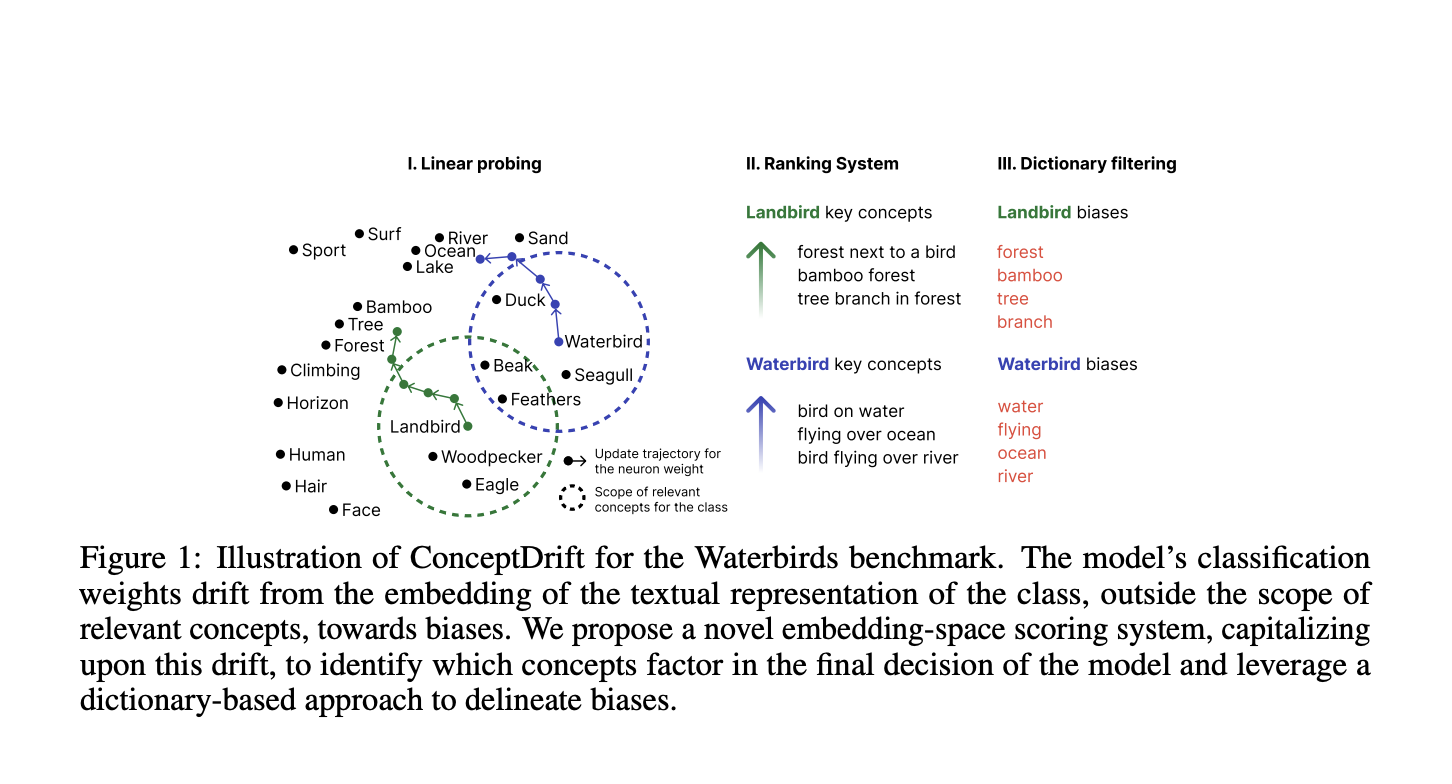
Datasets and pre-trained models come with intrinsic biases. Most methods rely on spotting them by analyzing misclassified samples in a semi-automated human computer validation. Deep neural networks, typically fine-tuned foundational models, are widely used in sectors like healthcare, finance, and criminal justice, where biased predictions can have serious societal impacts. These models often function as black boxes, lacking transparency and interpretability, which can obscure potential biases introduced during fine-tuning. Such biases arise from datasets and can lead to harmful outcomes by reinforcing existing inequalities. Recent methods for addressing biases in subpopulation shift scenarios primarily analyze validation data without investigating the model’s internal decision-making processes. For example, B2T [13] highlights biases only within the validation set, overlooking whether these biases impact the model’s weights. This gap underscores the need to examine model decision pathways to understand if dataset biases influence predictions.
Current methods for identifying biases often rely on analyzing misclassified samples through semi-automated human-computer validation. These methods provide explanations for wrong predictions but lack precision in highlighting unwanted correlations. Machine learning models often capture correlations or “shortcuts” that may solve a task but are not essential, leading to biases that hinder generalization outside the training distribution. Prior methods such as B2T, SpLiCE, and Lg have identified dataset biases through data analysis. Techniques for debiasing have become essential to ensure fairness and accuracy, with approaches like group-balanced subsampling, reweighting, and data augmentation commonly used. In cases without annotations, some methods involve training and refining a biased model based on its misclassifications to reduce bias. Fairness research in machine learning is extensive, aiming to create ethical, equitable outcomes across subpopulations while overlapping with domain generalization and worst-group performance improvements. Interpretability is crucial in fairness, as understanding model decisions aids in bias mitigation. Invariant learning approaches enhance robustness to distributional changes by enforcing that models remain consistent across environments; however, in cases without predefined environments, data subsets can be created to challenge invariant constraints, using algorithms like groupDRO to improve distributional robustness.
A team of researchers from the University of Bucharest, Romania Institute for Logic and Data Science, and the University of Montreal, have come up with ConceptDrift, a novel method designed to identify concepts critical to a model’s decision-making process. ConceptDrift is the first to employ a weight-space approach to detect biases in fine-tuned foundational models, moving beyond the limitations of current data-restricted protocols. The method also incorporates a unique embedding-space scoring technique that uncovers concepts with a significant impact on class prediction. Additionally, ConceptDrift assists in bias investigation, revealing previously unidentified biases in four datasets: Waterbirds, CelebA, Nico++, and CivilComments. It demonstrates substantial improvements in zero-shot bias prevention over existing state-of-the-art methods for bias identification. Tested across image and text data, ConceptDrift is very versatile and can be adapted to other data modalities with a foundational model that includes text-processing capabilities.
The method detects concepts incorrectly linked to class labels in classification tasks. Using a foundational model, it is trained on a linear layer of its frozen representations, and textual concepts that influence predictions are identified. By embedding both concepts and samples into a shared space, high cosine similarity is detected. The weights initialized to class names, shift through training toward discriminative concepts and are ranked. Concepts are filtered, keeping only those that distinguish one class from others and contribute to bias detection. An experiment showed that ConceptDrift consistently improves zero-shot classification accuracy across all datasets, surpassing baseline and state-of-the-art bias identification methods.
In conclusion, ConceptDrift offers a novel approach to identifying hidden biases in datasets by analyzing the weight update trajectory of a linear probe. This method provides a more precise identification of unwanted correlations, improving the transparency and interpretability of foundational models. The research empirically demonstrates its effectiveness in bias investigation across four datasets: Waterbirds, CelebA, Nico++, and CivilComments, revealing previously undetected biases and achieving notable improvements in zero-shot bias prevention over current state-of-the-art methods. Validated on image and text datasets, with a foundational model also endowed with text processing capabilities, ConceptDrift can accommodate any other modality.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post ConceptDrift: An AI Method to Identify Biases Using a Weight-Space Approach Moving Beyond Traditional Data-Restricted Protocols appeared first on MarkTechPost.