
Text embedding, a central focus within natural language processing (NLP), transforms text into numerical vectors capturing the essential meaning of words or phrases. These embeddings enable machines to process language tasks like classification, clustering, retrieval, and summarization. By structuring data in vector form, embeddings provide a scalable and effective way for machines to interpret and act on human language, enhancing machine understanding in applications ranging from sentiment analysis to recommendation systems.
A significant challenge in text embedding is generating the vast quantities of high-quality training data needed to develop robust models. Manually labeling large datasets is costly and time-intensive, and while synthetic data generation offers a potential solution, many approaches depend heavily on proprietary language models such as GPT-4. These methods, though effective, pose a substantial cost barrier due to the extensive resources needed to operate large-scale models, making advanced embedding technologies inaccessible to a broader research community and limiting opportunities to refine and adapt embedding methods.
Most current methods for creating training data for embedding models rely on proprietary large language models (LLMs) to generate synthetic text. For example, GPT-4 generates triplets—a query paired with positive and hard negative documents—to produce diverse, contextually rich examples. This approach, while powerful, comes with high computational costs and often involves black-box models, which restricts researchers’ ability to optimize and adapt the process to their specific needs. Such reliance on proprietary models can limit scalability and efficiency, highlighting the need for innovative, resource-conscious alternatives that maintain data quality without excessive costs.
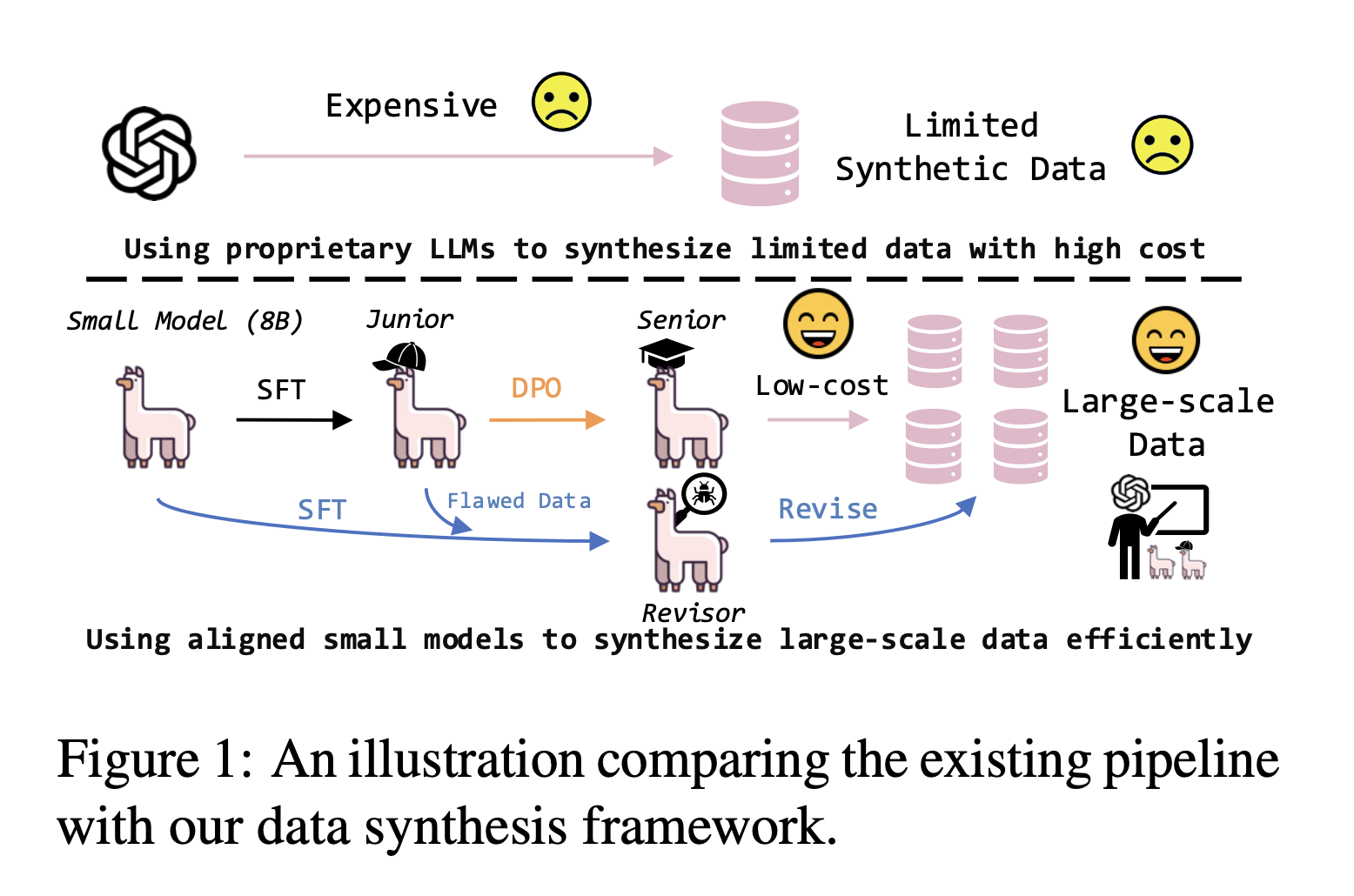
Researchers from the Gaoling School of Artificial Intelligence and Microsoft Corporation have introduced a novel framework called SPEED. This approach leverages small, open-source models to generate high-quality embedding data while significantly reducing resource demands. By replacing expensive proprietary models with an efficient, open-source alternative, SPEED aims to democratize access to scalable synthetic data generation. This framework is designed to produce data for training high-performing text embeddings while using less than a tenth of the API calls required by conventional proprietary LLMs.
SPEED operates through a structured alignment pipeline comprising three primary components: a junior generator, a senior generator, and a data revisor. The process begins with task brainstorming and seed data generation, where GPT-4 is employed to develop diverse task descriptions. These descriptions form a foundational set of instructions, providing the junior generator model with supervised fine-tuning to produce initial, low-cost synthetic data. The data generated by the junior model is then processed by the senior generator, which uses preference optimization to enhance quality based on evaluation signals provided by GPT-4. In the final stage, the data revisor model refines these outputs, addressing any inconsistencies or quality issues and further improving the alignment and quality of the generated data. This process enables SPEED to synthesize data efficiently and aligns small, open-source models with the task requirements traditionally handled by larger, proprietary models.
The results from SPEED demonstrate significant advancements in embedding quality, cost-efficiency, and scalability. SPEED outperformed the leading embedding model, E5mistral, with significantly fewer resources. SPEED achieved this by using just 45,000 API calls, compared to E5mistral’s 500,000, representing a cost reduction of more than 90%. On the Massive Text Embedding Benchmark (MTEB), SPEED showed an average performance of 63.4 across tasks, including classification, clustering, retrieval, and pair classification, underscoring the model’s high versatility and quality. SPEED achieved superior results across various benchmarks and task types in zero-shot settings, closely matching the performance of proprietary, high-resource models despite its low-cost structure. For example, SPEED’s performance reached 78.4 in classification tasks, 49.3 in clustering, 88.2 in pair classification, 60.8 in reranking, 56.5 in retrieval, 85.5 in semantic textual similarity, and 31.1 in summarization, placing it competitively across all categories.
The SPEED framework offers a practical, cost-effective alternative for the NLP community. By achieving high-quality data synthesis at a fraction of the cost, researchers can be provided with an efficient, scalable, and accessible method for training embedding models without relying on high-cost, proprietary technologies. SPEED’s alignment and preference optimization techniques illustrate the feasibility of training small, open-source models to meet the complex demands of synthetic data generation, making this approach a valuable resource for advancing embedding technology and facilitating broader access to sophisticated NLP tools.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Microsoft Asia Research Introduces SPEED: An AI Framework that Aligns Open-Source Small Models (8B) to Efficiently Generate Large-Scale Synthetic Embedding Data appeared first on MarkTechPost.