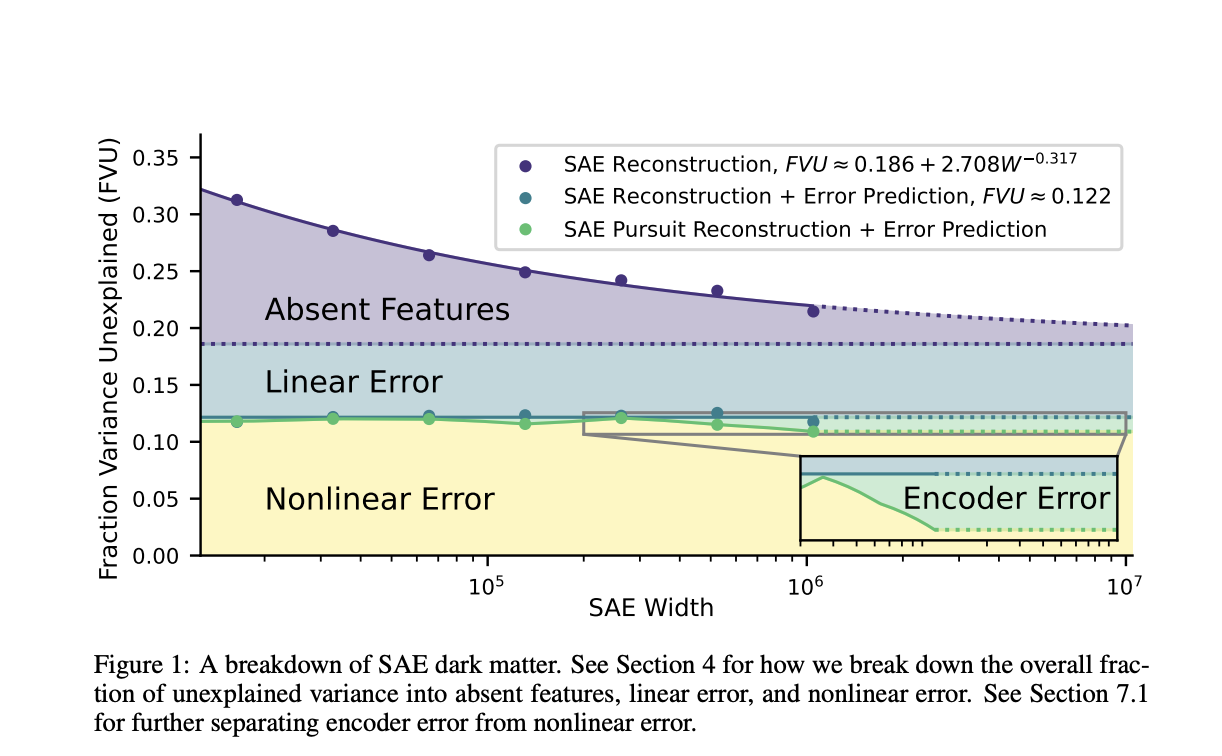
Sparse autoencoders (SAEs) are an emerging method for breaking down language model activations into linear, interpretable features. However, they fail to fully explain model behavior, leaving “dark matter” or unexplained variance. The ultimate aim of mechanistic interpretability is to decode neural networks by mapping their internal features and circuits. SAEs learn sparse representations to reconstruct hidden activations, but their reconstruction error follows a power law with a persistent error term, likely due to more complex activation patterns. This study analyzes SAE errors to understand better their limitations, scaling behavior, and the structure of model activations.
The linear representation hypothesis (LRH) suggests that language model hidden states can be broken down into sparse, linear feature directions. This idea is supported by work using sparse autoencoders and dimensionality reduction, but recent studies have raised doubts, showing non-linear or multidimensional representations in models like Mistral and Llama. Sparse autoencoders have been benchmarked for error rates using human analysis, geometry visualizations, and NLP tasks. Studies show that SAE errors can be more impactful than random perturbations, and scaling laws suggest larger SAEs capture more complex features and finer distinctions than smaller models.
Researchers from MIT and IAIFI investigated “dark matter” in SAEs, focusing on the unexplained variance in model activations. Surprisingly, they found that over 90% of SAE error can be linearly predicted from the initial activation vector. Larger SAEs struggle to reconstruct contexts similar to smaller ones, indicating predictable scaling behavior. They propose that nonlinear errors, unlike linear ones, involve fewer unlearned features and significantly impact cross-entropy loss. Two methods to reduce nonlinear error were explored: inference time optimization and SAE outputs from earlier layers, with the latter showing greater error reduction.
The paper studies neural network activations and SAE, aiming to minimize reconstruction error while using a few active latents. It focuses on predicting the error of SAEs and evaluates how well the SAE error norms and vectors can be predicted using linear probes. Results show that error norms are highly predictable, with 86%-95% of variance explained, while error vector predictions are less accurate (30%-72%). Nonlinear error prediction (FVU) remains constant as SAE width increases. The study also explores how scaling affects prediction accuracy across different SAE models and token contexts.
The study examines ways to reduce nonlinear error in SAEs by implementing various techniques. One method involves improving the encoder using a gradient pursuit optimization during inference, which resulted in a 3-5% decrease in overall error. However, most of the improvement came from reducing linear error. The results highlight that larger SAEs face similar challenges in reconstructing contexts as smaller ones, and simply increasing the size of SAEs doesn’t effectively reduce nonlinear error, pointing to limitations in this approach.
The study also explored the use of linear projections between adjacent SAEs to explain nonlinear error. By analyzing the outputs of previous components, researchers were able to predict small portions of the total error, showing that about 50% of the variance in nonlinear error can be accounted for. However, the nonlinear error remains challenging to reduce, indicating that improving SAEs might require alternative strategies beyond increasing their size, such as exploring new penalties or more effective learning methods.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Understanding and Reducing Nonlinear Errors in Sparse Autoencoders: Limitations, Scaling Behavior, and Predictive Techniques appeared first on MarkTechPost.