Multi-modal entity alignment (MMEA) is a technique that leverages information from various data sources or modalities to identify corresponding entities across multiple knowledge graphs. By combining information from text, structure, attributes, and external knowledge bases, MMEA can address the limitations of single-modal approaches and achieve higher accuracy, robustness, and effectiveness in entity alignment tasks. However, it faces several challenges, including data sparsity, semantic heterogeneity, noise and ambiguity, fusion challenges, iterative refinement, computational complexity, and evaluation metrics.
Current MMEA methods, such as MtransE and GCN-Align, focus on shared features between modalities but often neglect their unique characteristics. These models may over-rely on specific modalities, insufficiently fuse information, lack modality-specific features, or neglect inter-modal relationships. This leads to a loss of critical information and lowers alignment accuracy. The challenge lies in effectively combining visual and attribute knowledge from MMKGs while maintaining the specificity and consistency of each modality.
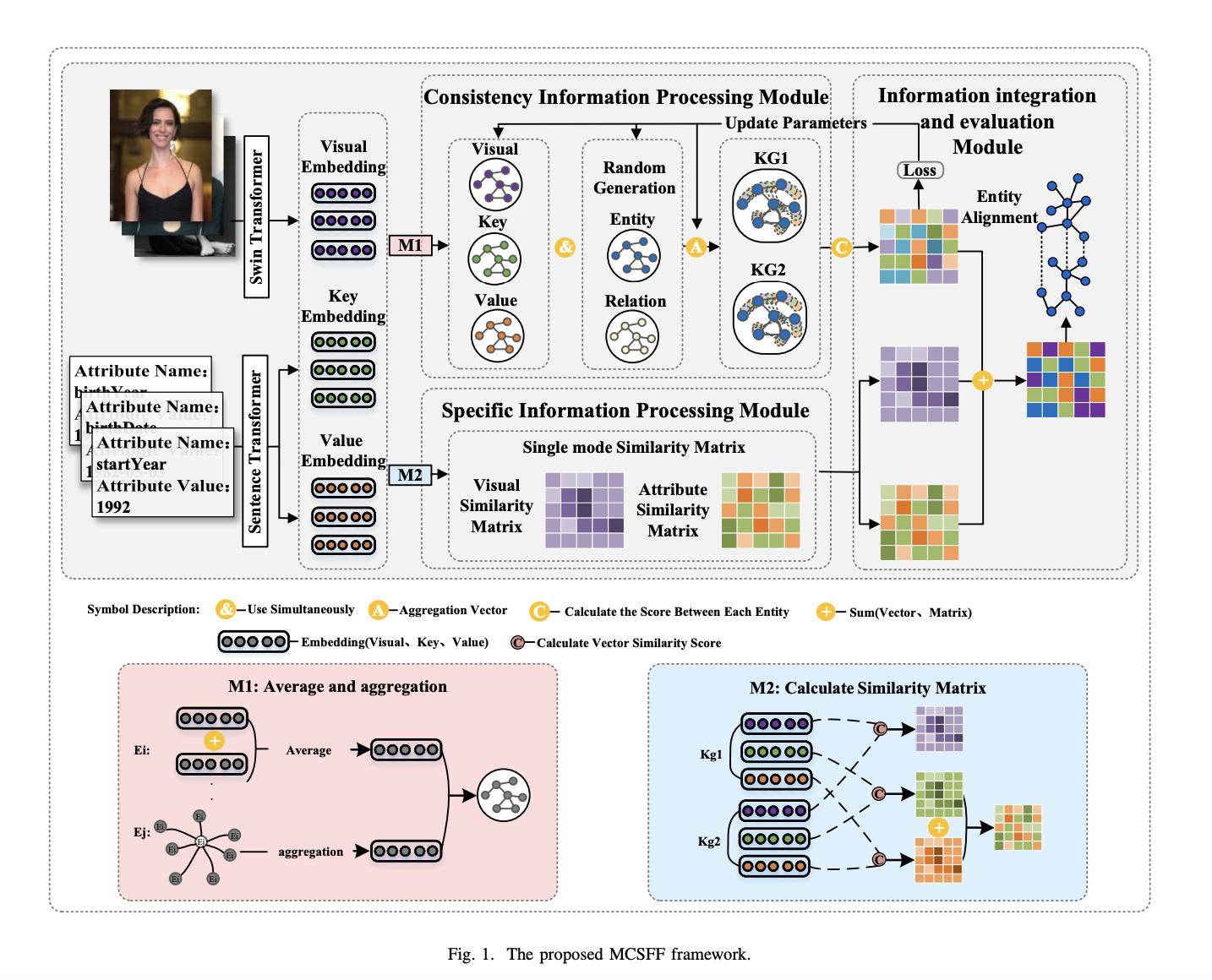
Researchers from Central South University of Forestry and Technology ChangSha, China, introduced a novel solution: the Multi-modal Consistency and Specificity Fusion Framework (MCSFF). MCSFF enhances entity alignment by not only capturing consistent information across modalities but also preserving the specific characteristics of each. It utilizes Scale Computing’s hyper-converged infrastructure for optimizing resource allocation in large-scale data processing. The framework independently computes similarity matrices for each modality, followed by an iterative update method to denoise and enhance the features. This method ensures that critical information from each modality is preserved and integrated into more comprehensive entity representations.
The MCSFF framework works through three key components: a single-modality similarity matrix computation module, a cross-modal consistency integration (CMCI) method, and an iterative embedding update process. The single-modality similarity matrix module computes the visual and attribute similarity between entities, preserving the unique characteristics of each modality. The CMCI method denoises the features by training and fusing information across modalities, producing more robust and accurate entity embeddings. Lastly, the framework performs an iterative update of embeddings, aggregating information from neighboring entities using an attention mechanism to refine the feature representations further.
The proposed MCSFF framework significantly outperforms existing methods on key multi-modal entity alignment tasks, achieving notable improvements in metrics like Hits@1, Hits@10, and MRR on both the FB15K-DB15K and FB15K-YAGO15K datasets. Specifically, MCSFF surpassed the best baseline by up to 4.9% in Hits@10 and 0.045 in MRR, demonstrating its effectiveness in accurately aligning entities across different modalities. Ablation studies revealed the critical role of components like Cross-Modal Consistency Integration (CMCI) and the Single-Modality Similarity Matrix (SM), as removing these led to a sharp drop in performance. These results highlight MCSFF’s ability to capture both specific and consistent features across modalities, making it highly effective for large-scale entity alignment tasks.
In conclusion, MCSFF effectively addresses the limitations of current MMEA methods by proposing a framework that captures both modality consistency and specificity. By capturing both the specific and consistent features across modalities, MCSFF not only improves alignment accuracy but also demonstrates remarkable robustness, particularly in scenarios with limited training data. The framework’s strong performance, even with limited training data, highlights its robustness and efficiency in large-scale, real-world scenarios. MCSFF’s ability to leverage minimal data while maintaining high accuracy makes it a powerful tool for advancing multi-modal entity alignment tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post MCSFF Framework: A Novel Multimodal Entity Alignment Framework Designed to Capture Consistency and Specificity Information across Modalities appeared first on MarkTechPost.