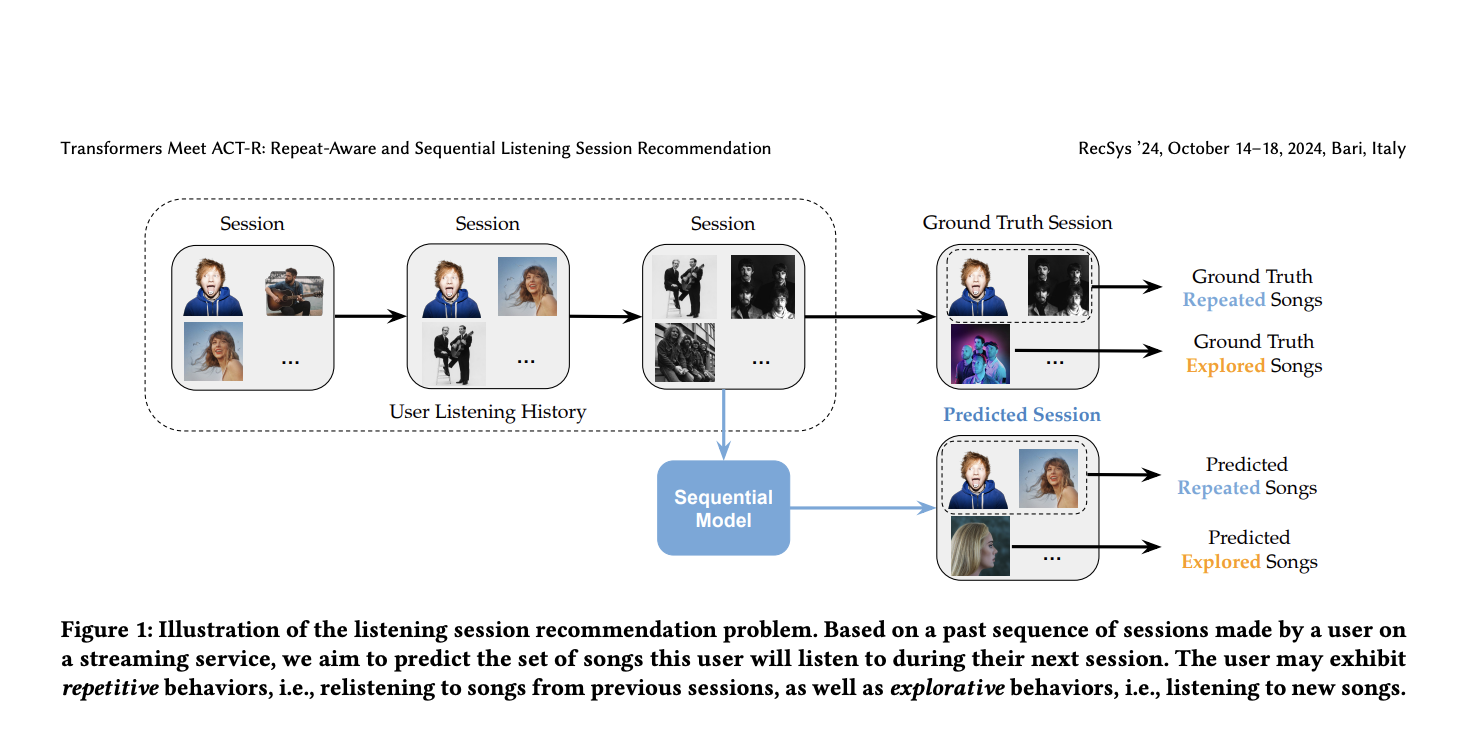
Music recommendation systems have become essential to streaming services, helping users discover new songs and re-listen to their favorites. These systems use algorithms that analyze users’ listening patterns, making personalized song recommendations. One key type of algorithm used in these services is sequential recommendation systems, which predict the next song a user will enjoy based on previous listening sessions. Unlike traditional static models, sequential systems focus on dynamic user preferences, which evolve, allowing users to explore new content while appreciating familiar songs.
A significant challenge in these systems is accurately reflecting users’ repetitive listening behaviors. Music consumption often involves listening to the same songs multiple times, yet many existing systems need to account for this behavior adequately. The failure to model repeat listening patterns can result in recommendations that miss key aspects of the user’s musical experience. This is particularly problematic in music, where users often return to the same tracks, albums, or artists and thus require a system that can effectively predict new and repeated content.
Current methods, such as collaborative filtering and deep learning models like recurrent neural networks, have been widely used to model user preferences. These models effectively capture the dynamic evolution of tastes over time but overlook the repetitive nature of music listening. While some models attempt to integrate past interactions to inform future recommendations, they often need to provide a robust solution for sequential music recommendations, especially in recognizing when users are likely to repeat their listening patterns. These limitations have sparked interest in developing more refined models to handle the complexity of repeat behavior in music consumption.
Researchers from Deezer have introduced a novel system called PISA (Psychology-Informed Session embedding using ACT-R), designed specifically to improve sequential listening recommendations by incorporating repetitive listening behavior into the predictive model. The system leverages insights from cognitive psychology, specifically the ACT-R (Adaptive Control of Thought-Rational) framework, to simulate how human memory processes information, particularly how users recall and re-listen to songs. By modeling these memory dynamics, PISA aims to deliver more accurate recommendations, balancing the suggestion of new and previously enjoyed songs. The researchers’ work at Deezer provides a practical application of cognitive theory to enhance user experiences on a global music streaming platform.
PISA operates through a Transformer-based architecture that captures dynamic and repetitive patterns in user behavior. The system creates embedding representations of listening sessions and users, enabling it to model session sequences effectively. It uses attention weights influenced by ACT-R components, including base-level activation, which reflects how recently and frequently a song has been listened to, and spreading activation, which captures the relationships between songs in the same session. This combination allows PISA to predict which songs users are likely to re-listen to while still being capable of introducing new content. The ACT-R framework also incorporates partial matching, helping the system recommend songs with similar characteristics, even if they haven’t been played together before.
The performance of PISA has been validated using two large-scale datasets: one from the public music website Last.fm and another from Deezer’s proprietary dataset. In the experiments, the system outperformed traditional models in several key metrics. For instance, regarding NDCG (Normalized Discounted Cumulative Gain), PISA scored 12.16% on Last.fm, demonstrating a superior ability to rank relevant songs higher in the recommendation list than other models. Moreover, PISA’s recall score, which measures how many of the recommended songs were listened to by the user, was significantly higher, reaching up to 12.09% in some cases. These improvements reflect PISA’s capability to model user preferences for songs users accurately have heard before and for new ones.
Particularly, PISA demonstrated its ability to handle repetitive behaviors in music listening. On Deezer, the system achieved a repetition accuracy of 88.27%, closely matching users’ listening behaviors, which involved frequently replaying favorite tracks. The system’s repetition bias, which measures whether the system overemphasizes repeated songs, was significantly lower than other models, indicating that PISA strikes a good balance between recommending repeated and new songs. Furthermore, PISA outperformed models like RepeatNet and SASRec in exploratory tasks, introducing users to new songs they hadn’t listened to before enhancing the discovery experience on music platforms.
In conclusion, the PISA system addresses a crucial gap in music recommendation by incorporating cognitive psychology into the design of a sequential recommender. By accounting for both repetitive and evolving listening behaviors, it offers a more accurate and user-friendly recommendation experience. The researchers at Deezer have demonstrated that combining dynamic user modeling with memory-based repetition modeling can significantly improve the performance of music recommendation systems. PISA provides more relevant recommendations and helps users discover new music while continuing to enjoy their favorite songs, ensuring a balanced and engaging listening experience.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post PISA: A Psychology-Informed Approach to Sequential Music Recommendation with Repeat Listening Awareness appeared first on MarkTechPost.