Large Language Models (LLMs) have demonstrated remarkable abilities in tackling various reasoning tasks expressed in natural language, including math word problems, code generation, and planning. However, as the complexity of reasoning tasks increases, even the most advanced LLMs struggle with errors, hallucinations, and inconsistencies due to their auto-regressive nature. This challenge is particularly evident in tasks requiring multiple reasoning steps, where LLMs’ “System 1” thinking—fast and instinctive but less accurate—falls short. The need for more deliberative, logical “System 2” thinking becomes crucial for solving complex reasoning problems accurately and consistently.
Several attempts have been made to overcome the challenges faced by LLMs in complex reasoning tasks. Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) aim to align LLM outputs with human expectations. Direct Preference Optimization (DPO) and Aligner methods have also been developed to improve alignment. In the realm of enhancing LLMs with planning capabilities, Tree-of-Thoughts (ToT), A* search, and Monte Carlo Tree Search (MCTS) have been applied. For math reasoning and code generation, techniques such as prompt engineering, fine-tuning with task-specific corpora, and training reward models have been explored. However, these methods often require extensive expertise, significant computational resources, or task-specific modifications, limiting their generalizability and efficiency.
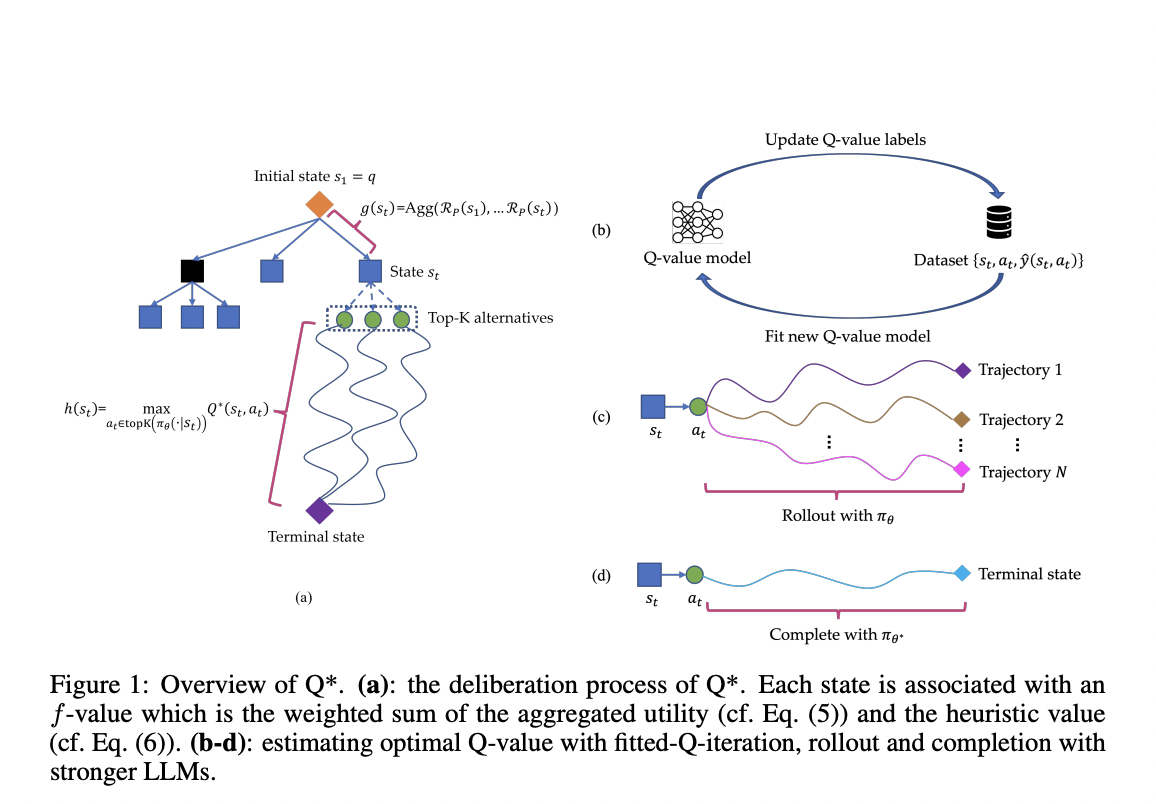
Researchers from Skywork AI and Nanyang Technological University present Q*, a robust framework designed to enhance the multi-step reasoning capabilities of LLMs through deliberative planning. This approach formalizes LLM reasoning as a Markov Decision Process (MDP), where the state combines the input prompt and previous reasoning steps, the action represents the next reasoning step, and the reward measures task success. Q* introduces general methods for estimating optimal Q-values of state-action pairs, including offline reinforcement learning, best sequence selection from rollouts, and completion using stronger LLMs. By framing multi-step reasoning as a heuristic search problem, Q* employs plug-and-play Q-value models as heuristic functions within an A* search framework, guiding LLMs to select the most promising next steps efficiently.
The Q* framework employs a sophisticated architecture to enhance LLMs’ multi-step reasoning capabilities. It formalizes the process as a heuristic search problem, utilizing an A* search algorithm. The framework associates each state with an f-value, computed as a weighted sum of aggregated utility and a heuristic value. The aggregated utility is calculated using a process-based reward function, while the heuristic value is estimated using the optimal Q-value of the state. Q* introduces three methods for estimating optimal Q-values: offline reinforcement learning, learning from rollouts, and approximation using stronger LLMs. These methods enable the framework to learn from training data without task-specific modifications. The deliberative planning process follows an A* search algorithm. It maintains two sets of states: unvisited and visited. The algorithm iteratively selects the state with the highest f-value from the unvisited set, expands it using the LLM policy, and updates both sets accordingly. This process continues until a terminal state (complete trajectory) is reached, at which point the answer is extracted from the final state.
Q* demonstrated significant performance improvements across various reasoning tasks. On the GSM8K dataset, it enhanced Llama-2-7b to achieve 80.8% accuracy, surpassing ChatGPT-turbo. For the MATH dataset, Q* improved Llama-2-7b and DeepSeekMath-7b, reaching 55.4% accuracy, outperforming models like Gemini Ultra (4-shot). In code generation, Q* boosted CodeQwen1.5-7b-Chat to 77.0% accuracy on the MBPP dataset. These results consistently show Q*’s effectiveness in enhancing LLM performance across math reasoning and code generation tasks, outperforming traditional methods and some closed-source models.
Q* emerges as an effective method to overcome the challenge of multi-step reasoning in LLMs by introducing a robust deliberation framework. This approach enhances LLMs’ ability to solve complex problems that require in-depth, logical thinking beyond simple auto-regressive token generation. Unlike previous methods that rely on task-specific utility functions, Q* uses a versatile Q-value model trained solely on ground-truth data, making it easily adaptable to various reasoning tasks without modifications. The framework employs plug-and-play Q-value models as heuristic functions, guiding LLMs effectively without the need for task-specific fine-tuning, thus preserving performance across diverse tasks. Q*’s agility stems from its single-step consideration approach, contrasting with more computationally intensive methods like MCTS. Extensive experiments in math reasoning and code generation demonstrate Q*’s superior performance, highlighting its potential to improve LLMs’ complex problem-solving capabilities significantly.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Q*: A Versatile Artificial Intelligence AI Approach to Improve LLM Performance in Reasoning Tasks appeared first on MarkTechPost.