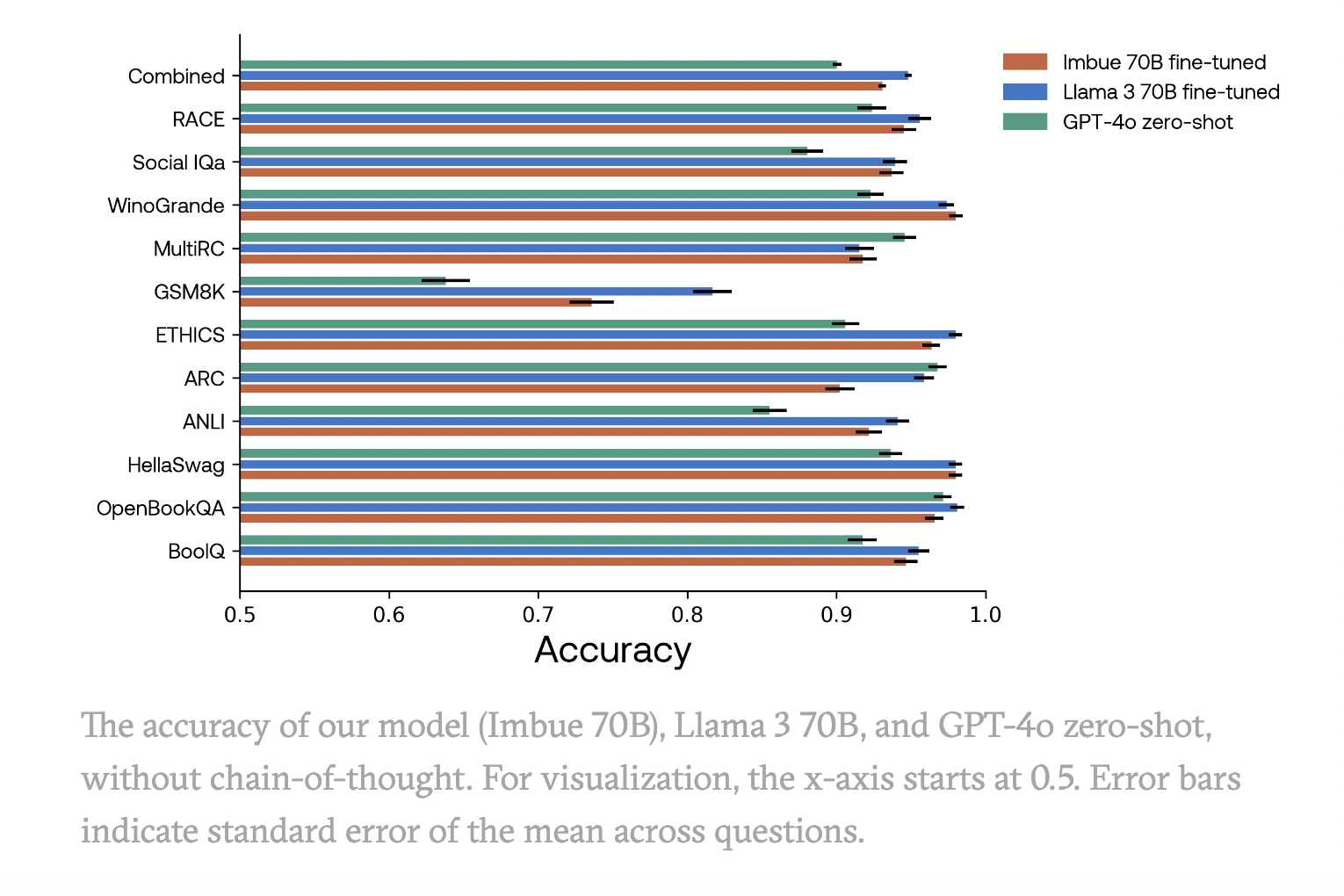
The Imbue Team recently undertook an ambitious project to train a 70-billion-parameter language model from scratch, achieving significant milestones in model performance and evaluation methodologies. Their team focused on creating a model that outperforms GPT-4 in zero-shot scenarios across various reasoning and coding benchmarks despite being pre-trained on only 2 trillion tokens compared to the much larger datasets used by comparable models.
The initiative addressed several critical questions about artificial intelligence and machine learning. One of the primary goals was to explore the practical requirements for building robust agents capable of writing and implementing reliable code. The team sought to understand the benefits of pre-training instead of fine-tuning or other post-training techniques. They also investigated the contributions of engineering optimizations in infrastructure, hardware, data, and evaluations towards developing a robust and accurate model.
The Imbue Team employed a cost-aware hyperparameter optimizer known as CARBS, which was pivotal in scaling their system to 70 billion parameters with minimal training instability. CARBS allowed the team to systematically fine-tune all hyperparameters, ensuring optimal performance for models of any size. This approach was crucial in mitigating the risks associated with training large models, particularly for smaller teams experimenting with novel architectures.
The project also emphasized the importance of clean evaluation datasets. The team updated and shared datasets to facilitate the accurate assessment of models on reasoning and coding tasks. This step was essential in ensuring that models achieved nearly 100% accuracy on unambiguous questions, thereby setting a high standard for evaluation. Additionally, the team released infrastructure scripts and best practices to assist other teams in training large language models efficiently, reducing the need to reproduce complex infrastructure code and knowledge from scratch.
Notable outcomes of this project were the development of a new code-focused reasoning benchmark and a dataset of 450,000 human judgments about ambiguity. These resources are designed to help other researchers and developers build and evaluate their models more effectively. By sharing these tools and insights, the Imbue Team aims to lower the barrier to entry for large-scale model training and encourage innovation in the field.
The team learned valuable lessons throughout the training, highlighting the importance of automated processes for diagnosing and resolving infrastructure issues, clean evaluation datasets, and resource-efficient pre-training experiments. These insights contribute to understanding how to build large, performant models that can operate reliably in real-world scenarios.
Key highlights of the research include the following:
- The Imbue Team trained a 70-billion-parameter model, outperforming GPT-4 in zero-shot reasoning and coding benchmarks.
- The project addressed practical requirements for building robust coding agents and explored the benefits of pre-training.
- Key tools and resources developed include CARBS, a cost-aware hyperparameter optimizer, clean evaluation datasets, infrastructure scripts, and a new code-focused reasoning benchmark.
- Lessons learned emphasized the importance of clean datasets, automated infrastructure processes, and resource-efficient pre-training experiments.
- The initiative aims to decrease the barrier to entry for large-scale model training and encourages innovation in AI research.
In conclusion, the Imbue Team’s work on this project is part of a broader effort to advance AI models’ research and development. Their focus areas include reinforcement learning, agent and reasoning architectures, data generation techniques, and user experience design. The team is committed to making these powerful capabilities accessible and intuitive for users and continues to explore new frontiers in AI research.
The post Imbue Team Trains 70B-Parameter Model From Scratch: Innovations in Pre-Training, Evaluation, and Infrastructure for Advanced AI Performance appeared first on MarkTechPost.