The domain of artificial intelligence has been significantly shaped by the emergence of large language models (LLMs), showing vast potential across various fields. However, enabling LLMs to effectively utilize computer science knowledge and serve humanity more efficiently remains a key challenge. Despite existing studies covering multiple fields, including computer science, there’s a lack of comprehensive evaluation specifically focused on LLMs’ performance in computer science. This gap overlooks the importance of thoroughly assessing the field and guiding LLM development to advance their capabilities in computer science.
Recent research has explored LLMs’ potential in various industries and scientific fields. However, studies on LLMs in computer science fall into two main categories: broad evaluation benchmarks where computer science constitutes only a small fraction, and explorations of specific LLM applications within computer science. Neither approach provides a comprehensive evaluation of LLMs’ foundational knowledge and reasoning abilities in the field. While individual capabilities like mathematics, coding, and logical reasoning have been well-studied, research on their integrated application and interrelationships remains sparse.
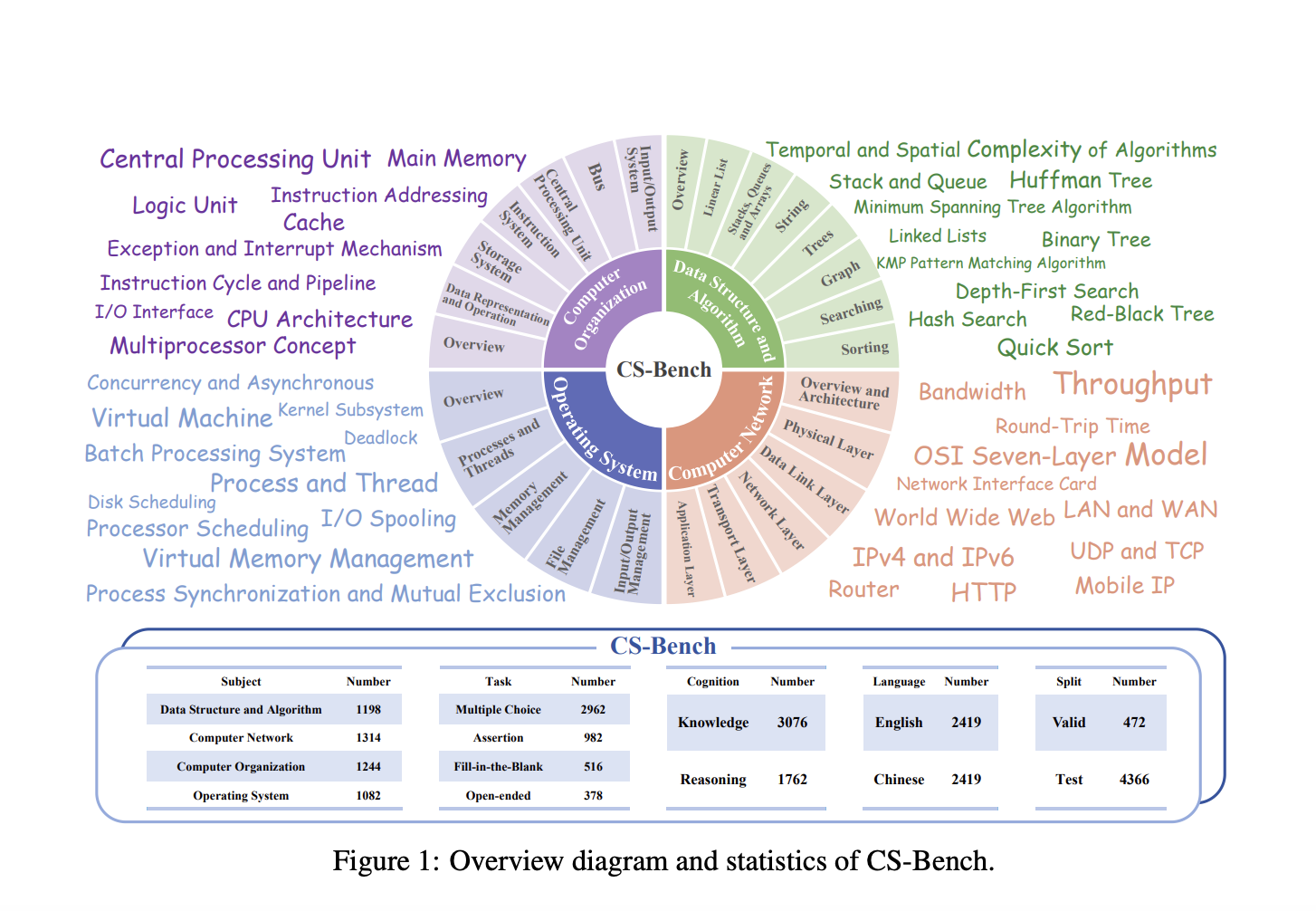
Researchers from Beijing University of Posts and Telecommunications propose CS-Bench, the first benchmark dedicated to evaluating LLMs’ performance in computer science. CS-Bench features high-quality, diverse task forms, varying capacities, and bilingual evaluation. It comprises approximately 5,000 carefully curated test items spanning 26 sections across 4 key computer science domains. The benchmark includes multiple-choice, assertion, fill-in-the-blank, and open-ended questions to better simulate real-world scenarios and assess LLMs’ robustness to different task formats. CS-Bench evaluates both knowledge-type and reasoning-type questions, supporting bilingual evaluation in Chinese and English.
CS-Bench covers four key domains: Data Structure and Algorithm (DSA), Computer Organization (CO), Computer Network(CN), and Operating System(OS). It includes 26 fine-grained subfields and diverse task forms to enrich assessment dimensions and simulate real-world scenarios. The data for CS-Bench comes from various sources, including publicly available online channels, adapted blog articles, and authorized teaching materials. The data processing involves a team of computer science graduates who parse questions and answers, label question types, and ensure quality through thorough manual checks. The benchmark supports bilingual assessment with a total of 4,838 samples across various task formats.
Evaluation results show that overall scores of models range from 39.86% to 72.29%. GPT-4 and GPT-4o represent the highest standard on CS-Bench, being the only models exceeding 70% proficiency. Open-source models like Qwen1.5-110B and Llama3-70B have surpassed previously strong closed-source models. Newer models demonstrate significant improvements compared to earlier versions. All models perform worse on reasoning compared to knowledge scores, indicating that reasoning poses a greater challenge. LLMs generally perform best in Data Structure and Algorithm and worst in Operating Systems. Stronger models demonstrate a better ability to use knowledge for reasoning and show more robustness across different task formats.
This study introduces CS-Bench to provide valuable insights into LLMs’ performance in computer science. Even top-performing models like GPT-4o have significant room for improvement. The benchmark highlights the close interconnections between computer science, mathematics, and coding abilities in LLMs. These findings offer directions for enhancing LLMs in the field and provide valuable insights into their cross-abilities and applications, paving the way for future advancements in AI and computer science.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post CS-Bench: A Bilingual (Chinese-English) Benchmark Dedicated to Evaluating the Performance of LLMs in Computer Science appeared first on MarkTechPost.