LLMs can memorize and reproduce their training data, posing significant privacy and copyright risks, especially in commercial settings. This issue is critical for models generating code, as they might inadvertently reuse verbatim code snippets, potentially conflicting with downstream licensing terms, including those restricting commercial use. Additionally, models may expose personally identifiable information (PII) or other sensitive data. Efforts to address this include post-training “unlearning” techniques and model editing to prevent unauthorized data reproduction. However, the optimal approach is to address memorization issues during the initial model training rather than relying solely on after-the-fact adjustments.
Researchers from the University of Maryland, the ELLIS Institute Tübingen, and the Max Planck Institute for Intelligent Systems have developed a “goldfish loss” training technique to reduce memorization in language models. This method excludes a random subset of tokens from the loss computation during training, preventing the model from memorizing and reproducing exact sequences from its training data. Extensive experiments with large Llama-2 models showed that goldfish loss significantly reduces memorization with minimal impact on performance. While goldfish-trained models may require slightly longer training times, they are resistant to verbatim reproduction and less susceptible to data extraction attacks.
Researchers have explored various methods to quantify and mitigate memorization in LLMs in recent studies. Techniques include extracting training data via prompts, which measure “extractable memorization,” where a model completes a string from a given prefix. Spontaneous data reproduction has also been observed in both text and image models. Strategies like differentially private training and data deduplication have been employed to mitigate memorization, though these can reduce model performance and are resource-intensive. Regularization methods, including dropout and noise addition, aim to minimize overfitting but often fail to prevent memorization entirely. Innovative approaches like consistent token masking can effectively prevent the model from learning specific data passages verbatim.
The “goldfish loss” technique modifies how LLMs are trained by selectively excluding tokens from the loss computation. This prevents the model from memorizing complete sequences from its training data, reducing the risk of verbatim reproduction. A hashed masking approach further enhances this by ensuring consistent token masking based on the context of preceding tokens. This method is crucial for handling duplicate passages in web documents, where variations exist due to different attributions, headers, and other content. By hashing a localized context of preceding tokens, the model avoids leaking entire passages while learning important language patterns effectively during training.
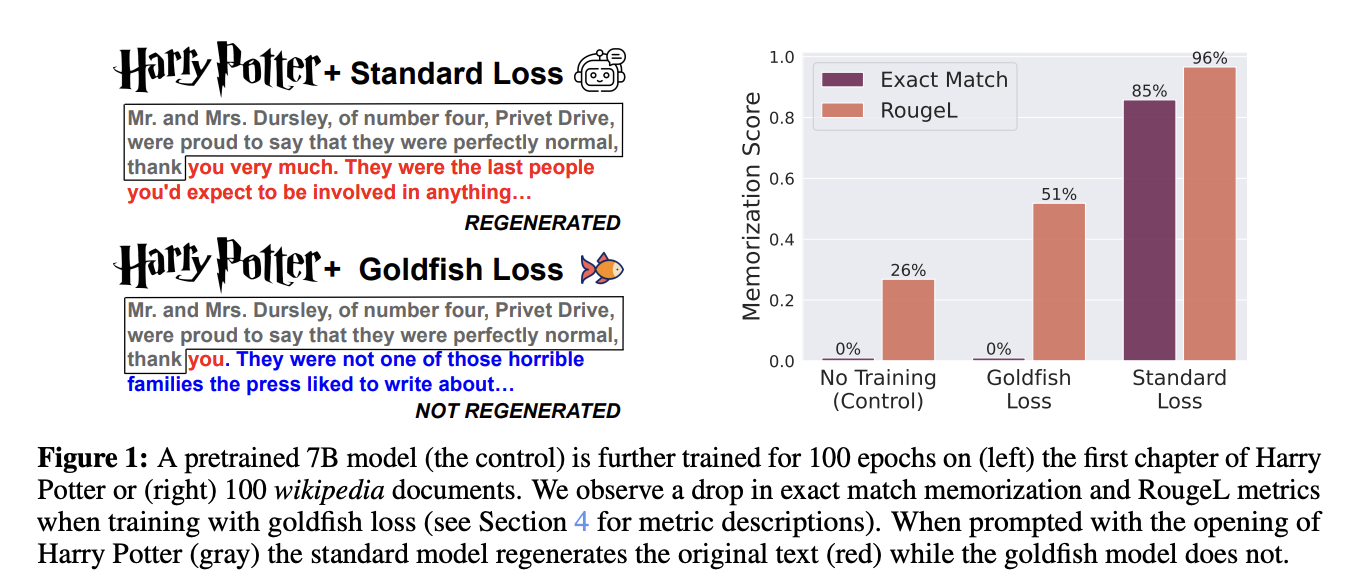
The goldfish loss effectively prevents memorization in large language models (LLMs) across different training scenarios. In extreme settings where models are trained on a small dataset intensely promoting memorization, such as 100 Wikipedia articles, standard training leads to significant memorization of exact sequences. In contrast, models trained with the goldfish loss, especially with a higher drop frequency (k = 4), show minimal memorization, as measured by RougeL scores and exact match rates. Under more standard training conditions with a larger dataset mix, goldfish loss models also demonstrate a reduced ability to reproduce specific target sequences from the training set compared to conventional models. Despite this prevention of memorization, goldfish-trained models perform comparably to standard-trained models across various benchmarks and exhibit similar language modeling capabilities, albeit requiring adjustments in training parameters to compensate for excluded tokens.
In conclusion, The goldfish loss offers a practical approach to mitigate memorization risks in LLMs without guaranteeing complete resistance to adversarial extraction methods. While effective in reducing exact sequence recall during autoregressive generation, it shows limitations against membership inference attacks (MIAs) and adaptive attacks like beam search. MIAs using loss and zlib metrics are less successful on goldfish-trained models, especially with lower drop frequencies (k values). However, resilience diminishes as k increases. Despite its limitations, the goldfish loss remains a viable strategy for enhancing privacy in industrial applications, with the potential for selective deployment in high-risk scenarios or specific document types.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Mitigating Memorization in Language Models: The Goldfish Loss Approach appeared first on MarkTechPost.