Document understanding is a critical field that focuses on converting documents into meaningful information. This involves reading and interpreting text and understanding the layout, non-textual elements, and text style. The ability to comprehend spatial arrangement, visual clues, and textual semantics is essential for accurately extracting and interpreting information from documents. This field has gained significant importance with the advent of large language models (LLMs) and the increasing use of document images in various applications.
The primary challenge addressed in this research is the effective extraction of information from documents that contain a mix of textual and visual elements. Traditional text-only models often need help interpreting spatial arrangements and visual elements, resulting in incomplete or inaccurate understanding. This limitation is particularly evident in tasks such as Document Visual Question Answering (DocVQA), where understanding the context requires seamlessly integrating visual and textual information.
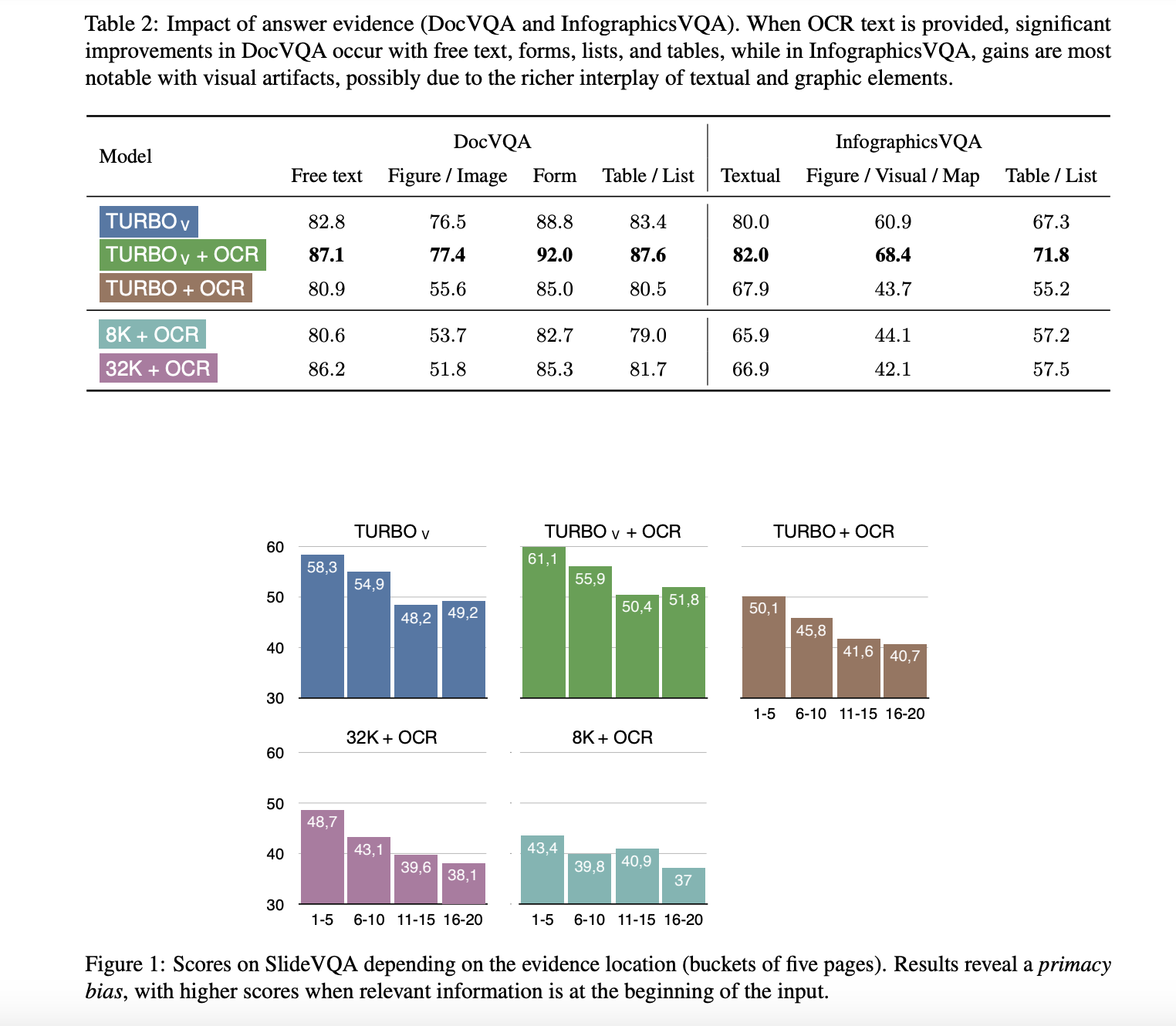
Existing methods for document understanding typically rely on Optical Character Recognition (OCR) engines to extract text from images. However, these methods could improve their ability to incorporate visual clues and the spatial arrangement of text, which are crucial for comprehensive document understanding. For instance, in DocVQA, the performance of text-only models is significantly lower compared to models that can process both text and images. The research highlighted the need for models to integrate these elements to improve accuracy and performance effectively.
Researchers from Snowflake evaluated various configurations of GPT-4 models, including integrating external OCR engines with document images. This approach aims to enhance document understanding by combining OCR-recognized text with visual inputs, allowing the models to simultaneously process both types of information. The study examined different versions of GPT-4, such as the TURBO V model, which supports high-resolution images and extensive context windows up to 128k tokens, enabling it to handle complex documents more effectively.
The proposed method was evaluated using several datasets, including DocVQA, InfographicsVQA, SlideVQA, and DUDE. These datasets represent many document types, from text-intensive to vision-intensive and multi-page documents. The results demonstrated significant performance improvements, particularly when text and images were used. For instance, the GPT-4 Vision Turbo model achieved an ANLS score of 87.4 on DocVQA and 71.9 on InfographicsVQA when both OCR text and images were provided as input. These scores are notably higher than those achieved by text-only models, highlighting the importance of integrating visual information for accurate document understanding.
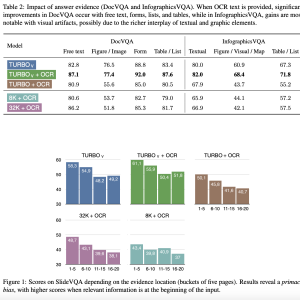
The research also provided a detailed analysis of the model’s performance on different types of input evidence. For example, the study found that OCR-provided text significantly improved results for free text, forms, lists, and tables in DocVQA. In contrast, the improvement was less pronounced for figures or images, indicating that the model benefits more from text-rich elements structured within the document. The analysis revealed a primacy bias, with the model performing better when relevant information was located at the beginning of the input document.
Further evaluation showed that the GPT-4 Vision Turbo model outperformed heavier text-only models in most tasks. The best performance was achieved with high-resolution images (2048 pixels on the longer side) and OCR text. For example, on the SlideVQA dataset, the model scored 64.7 with high-resolution images, compared to lower scores with lower-resolution images. This highlights the importance of image quality and OCR accuracy in enhancing document understanding performance.
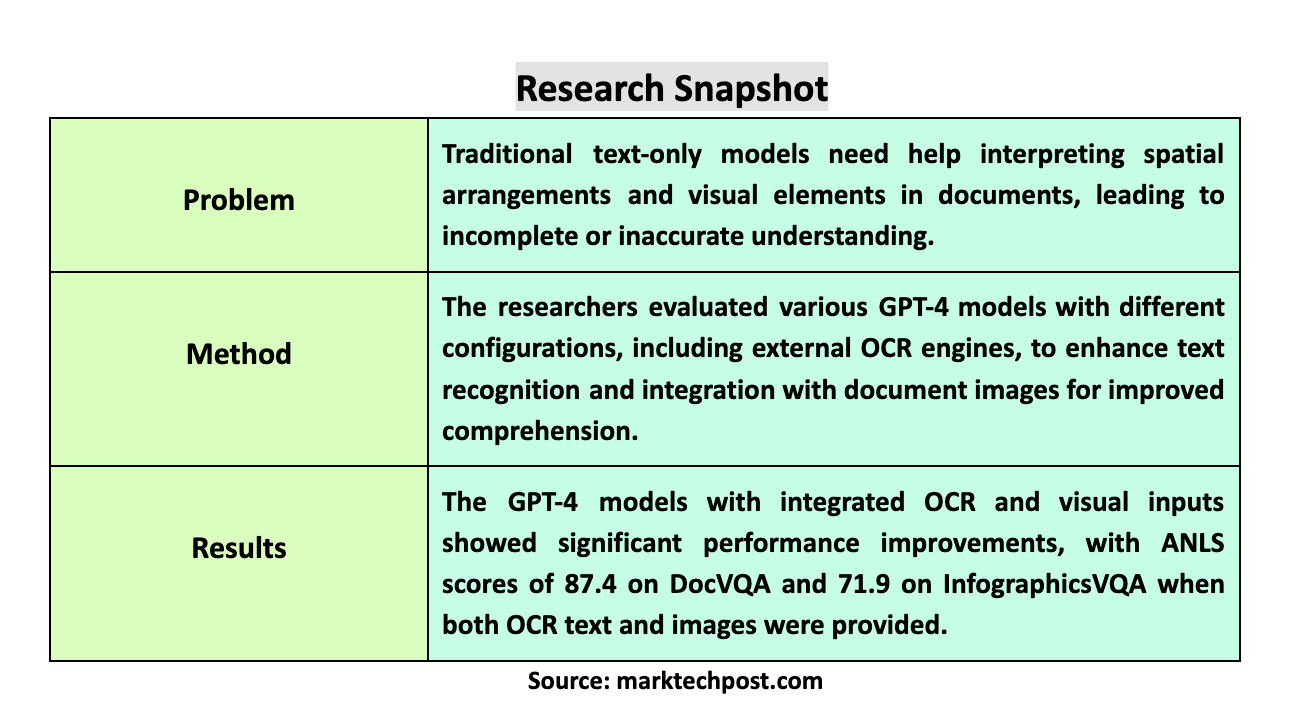
In conclusion, the research advanced document understanding by demonstrating the effectiveness of integrating OCR-recognized text with document images. The GPT-4 Vision Turbo model performed superior on various datasets, achieving state-of-the-art results in tasks requiring textual and visual comprehension. This approach addresses the limitations of text-only models and provides a more comprehensive understanding of documents. The findings underscore the potential for improved accuracy in interpreting complex documents, paving the way for more effective and reliable document understanding systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post This AI Paper from Snowflake Evaluates GPT-4 Models Integrated with OCR and Vision for Enhanced Text and Image Analysis: Advancing Document Understanding appeared first on MarkTechPost.