The Qwen Team recently unveiled their latest breakthrough, the Qwen2-72B. This state-of-the-art language model showcases advancements in size, performance, and versatility. Let’s look into the key features, performance metrics, and potential impact of Qwen2-72B on various AI applications.
Qwen2-72B is part of the Qwen2 series, which includes a range of large language models (LLMs) with varying parameter sizes. As the name suggests, the Qwen2-72 B boasts an impressive 72 billion parameters, making it one of the most powerful models in the series. The Qwen2 series aims to improve upon its predecessor, Qwen1.5, by introducing more robust capabilities in language understanding, generation, and multilingual tasks.
The Qwen2-72B is built on the Transformer architecture and features advanced components such as SwiGLU activation, attention QKV bias, and group query attention. These enhancements enable the model to handle complex language tasks more efficiently. The improved tokenizer is adaptive to multiple natural and coding languages, broadening the model’s applicability in various domains.
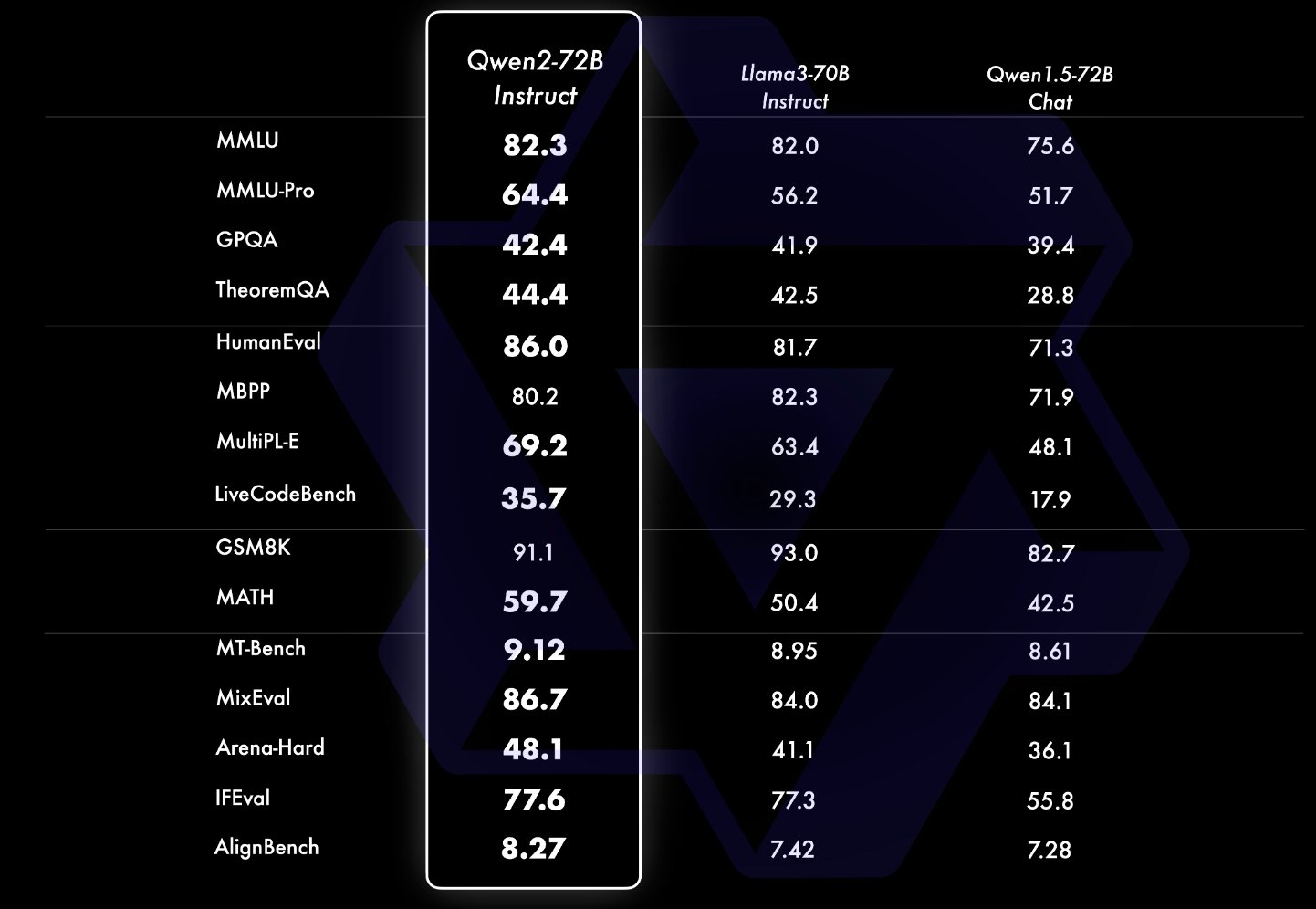
The Qwen2-72B has undergone extensive benchmarking to evaluate its performance across various tasks. It has demonstrated superior performance to state-of-the-art open-source language models and competitiveness against proprietary models. The evaluation focused on natural language understanding, general question answering, coding, mathematics, scientific knowledge, reasoning, and multilingual capabilities. Notable benchmarks include MMLU, MMLU-Pro, GPQA, Theorem QA, BBH, HellaSwag, Winogrande, TruthfulQA, and ARC-C.
One of the standout features of Qwen2-72B is its proficiency in multilingual tasks. The model has been tested on datasets such as Multi-Exam, BELEBELE, XCOPA, XWinograd, XStoryCloze, PAWS-X, MGSM, and Flores-101. These tests confirmed the model’s ability to handle languages and tasks beyond English, making it a versatile tool for global applications.
In addition to language tasks, Qwen2-72B excels in coding and mathematical problem-solving. It has been evaluated on coding tasks using datasets like HumanEval, MBPP, and EvalPlus, showing notable improvements over its predecessors. The model was tested on GSM8K and MATH datasets for mathematics, again demonstrating its advanced capabilities.
While the model’s size precludes loading it in a serverless Inference API, it is fully deployable on dedicated inference endpoints. The Qwen Team recommends post-training techniques such as Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and continued pretraining to enhance the model’s performance for specific applications.
The release of Qwen2-72B is poised to significantly impact various sectors, including academia, industry, and research. Its advanced language understanding and generation capabilities will benefit applications ranging from automated customer support to advanced research in natural language processing. Its multilingual proficiency opens up new global communication and collaboration possibilities.
In conclusion, the Qwen2-72B by the Qwen Team represents a major milestone in developing large language models. Its robust architecture, extensive benchmarking, and versatile applications make it a powerful tool for advancing the field of artificial intelligence. As the Qwen Team continues to refine and enhance its models, it can expect even greater future innovations.
The post Meet Qwen2-72B: An Advanced AI Model With 72B Parameters, 128K Token Support, Multilingual Mastery, and SOTA Performance appeared first on MarkTechPost.