
Language Learning Models (LLMs), which are very good at reasoning and coming up with good answers, are sometimes honest about their mistakes and tend to hallucinate when asked questions they haven’t seen before. When the responses are more than just one token, it becomes much more important to determine how to get trustworthy confidence estimations from LLMs.
Both training-based and prompting-based approaches have been used in the past to elicit confidence from LLMs. Prompting-based approaches, for instance, use specific prompts to create confidence ratings or answer consistency as a confidence indication. To train LLMs to be confident, training-based methods create tailored datasets for tuning. However, these techniques frequently yield less-than-ideal or simplistic confidence estimates, which do not faithfully represent the models’ degrees of certainty.
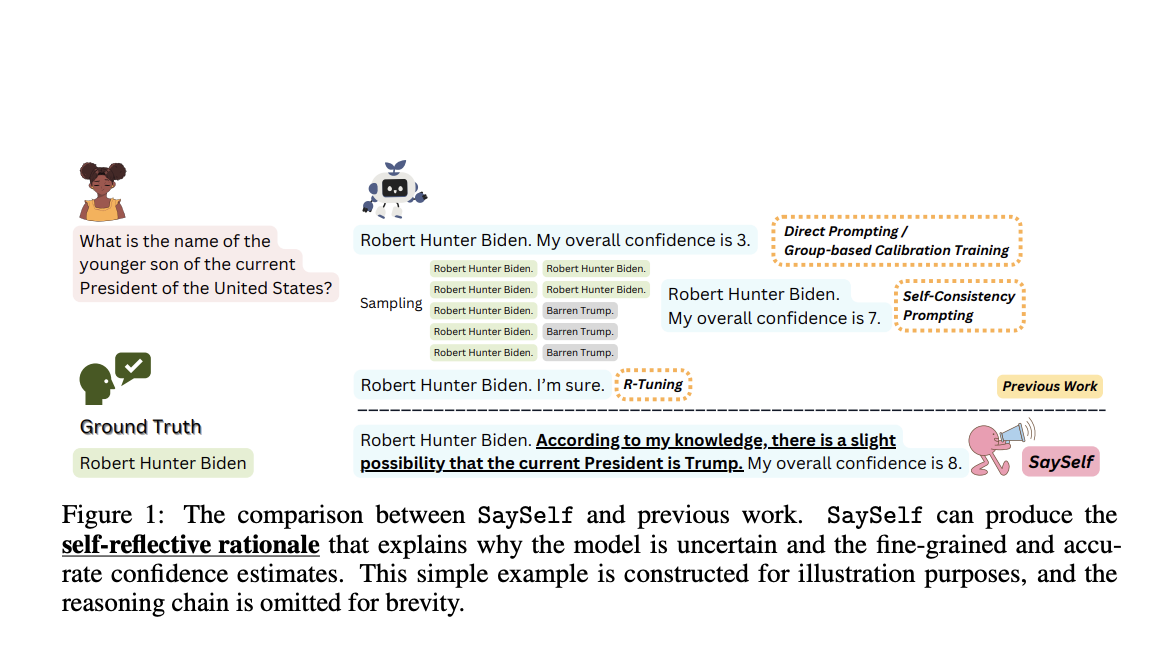
A new study by Purdue University, University of Illinois Urbana-Champaign, University of Southern California, and The Hong Kong University of Science and Technology introduce SaySelf, a training framework for LLMs that helps them produce confidence estimations with increased precision and accuracy. Significantly, unlike earlier work, SaySelf allows LLMs to provide self-reflective rationales that show where they lack knowledge and explain their confidence estimates. To achieve this, the researchers use a pre-made LLM (like GPT4) to automatically generate a dataset tailored to the model, which can then be used for supervised fine-tuning. They take a random sample of several reasoning chains, which are sequences of tokens that represent the LLM’s thought process, from LLMs for every query. After that, the reasoning chains are grouped into clusters according to their semantic similarity, and one example is kept from each grouping.
From a first-person viewpoint, GPT-4 is asked to examine the cases chosen from different clusters and to summarize the uncertainty about specific knowledge in plain language. The researchers calibrate the confidence estimate of LLMs in each response using reinforcement learning to ensure accurate confidence estimations. They devise a payment system that discourages LLMs from making overconfident predictions and punishes them when they get it wrong. Various knowledge-extensive question-answering tasks, such as complex medical diagnoses or legal case analysis, are used to assess SaySelf in this study’s experiments. The study demonstrates that SaySelf maintains task performance while drastically lowering confidence calibration errors. Further improvement of calibration performance is possible with the developed self-reflective rationales, which also successfully capture the internal uncertainty.
The following examples are incomplete regarding how this work could impact relevant scholarly investigations and practical applications: (1) From the standpoint of LLMs’ alignment, AI can benefit from a transparent confidence statement that includes explanations. (2) LLMs can improve their interaction and performance by following the self-reflective rationales to execute further activities, such as requesting external tools or asking clarification inquiries.
Upon completion of the SaySelf training process, the team hopes to see encouraging advances in training procedures, such as proactive learning algorithms that improve the learning outcomes of LLMs through their interactions with people.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post SaySelf: A Machine Learning Training Framework That Teaches LLMs To Express More Accurate Fine-Grained Confidence Estimates appeared first on MarkTechPost.