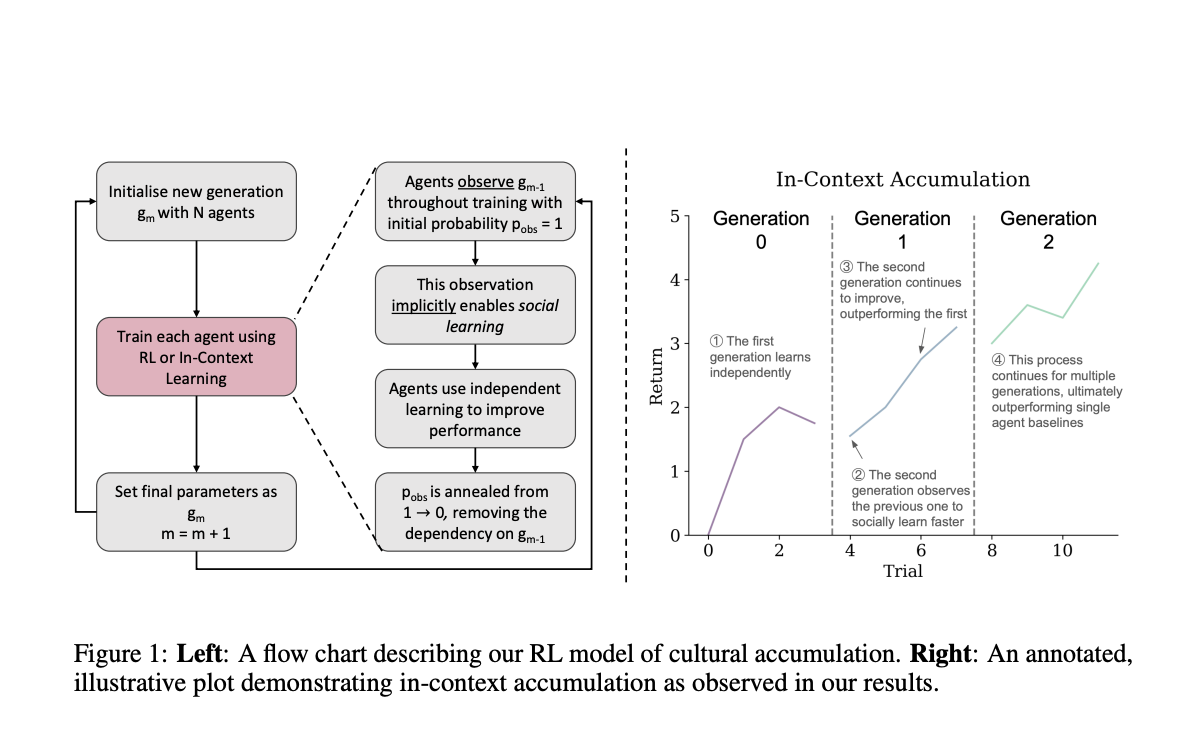
Cultural accumulation, the ability to learn skills and accumulate knowledge across generations, is considered a key driver of human success. However, current methodologies in artificial learning systems, such as deep reinforcement learning (RL), typically frame the learning problem as occurring over a single “lifetime.” This approach fails to capture the generational and open-ended nature of cultural accumulation observed in humans and other species. Achieving effective cultural accumulation in artificial agents poses significant challenges, including balancing social learning from other agents with independent exploration and discovery, as well as operating over multiple timescales that govern the acquisition of knowledge, skills, and technological advances.
Previous works have explored various approaches to social learning and cultural accumulation. The expert dropout method gradually increases the proportion of episodes without a demonstrator in a handpicked manner. Bayesian reinforcement learning with constrained inter-generational communication uses domain-specific languages to model social learning in human populations. Large language models have also been employed, with language acting as the communication medium across generations. While promising, these techniques rely on explicit communication channels, incremental adjustments, or domain-specific representations, limiting their broader applicability. There is a need for more general approaches that can facilitate knowledge transfer without such constraints.
The researchers propose a robust approach that balances social learning from other agents with independent exploration, enabling cultural accumulation in artificial reinforcement learning agents. They construct two distinct models to explore this accumulation under different notions of generations: episodic generations for in-context learning (knowledge accumulation) and train-time generations for in-weights learning (skill accumulation). By striking the right balance between these two mechanisms, the agents can continuously accumulate knowledge and skills over multiple generations, outperforming agents trained for a single lifetime with the same cumulative experience. This work represents the first general models to achieve emergent cultural accumulation in reinforcement learning, paving the way for more open-ended learning systems and presenting new opportunities for modeling human cultural evolution.
The researchers propose two distinct models to investigate cultural accumulation in agents: in-context accumulation and in-weights accumulation. For in-context accumulation, a meta-reinforcement learning process produces a fixed policy network with parameters θ. Cultural accumulation occurs during online adaptation to new environments by distinguishing between generations using the agent’s internal state ϕ. The length of an episode T represents a single generation. For in-weights accumulation, each successive generation is trained from randomly initialized parameters θ, with the network weights serving as the substrate for accumulation. The number of environment steps T used for training each generation represents a single generation.
The researchers introduce three environments to evaluate cultural accumulation: Goal Sequence, Travelling Salesperson Problem (TSP), and Memory Sequence. These environments are designed to require agents to discover and transmit information across generations, mimicking the processes of cultural accumulation observed in humans.
The results demonstrate the effectiveness of the proposed cultural accumulation models in outperforming single-lifetime reinforcement learning baselines across multiple environments.
In the Memory Sequence environment, in-context learners trained with the cultural accumulation algorithm exceeded the performance of single-lifetime RL2 baselines and even surpassed the noisy oracles they were trained with when evaluated on new sequences. Interestingly, the accumulation performance degraded when oracles were too accurate, suggesting an over-reliance on social learning that impedes independent in-context learning. For the Goal Sequence environment, in-context accumulation significantly outperformed single-lifetime RL2 when evaluated on new goal sequences. Higher but imperfect oracle accuracies during training produced the most effective accumulating agents, likely due to the challenging nature of learning to follow demonstrations in this partially observable navigation task. In the TSP, cultural accumulation enabled sustained improvements beyond RL2 over a single continuous context. The routes traversed by agents became more optimized across generations, with later generations exploiting a decreasing subset of edges.
Overall, the contributions of this research are the following:
- Proposes two models for cultural accumulation in reinforcement learning:
- In-context model operating on episodic timescales
- In-weights model operating over entire training runs
- Defines successful cultural accumulation as a generational process exceeding independent learning performance with the same experience budget
- Presents algorithms for in-context and in-weights cultural accumulation models
- Key findings:
- In-context accumulation can be impeded by oracles that are too reliable or unreliable, requiring a balance between social learning and independent discovery
- In-weights accumulation effectively mitigates primacy bias
- Network resets further improve in-weights accumulation performance
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Modeling Cultural Accumulation in Artificial Reinforcement Learning Agents appeared first on MarkTechPost.