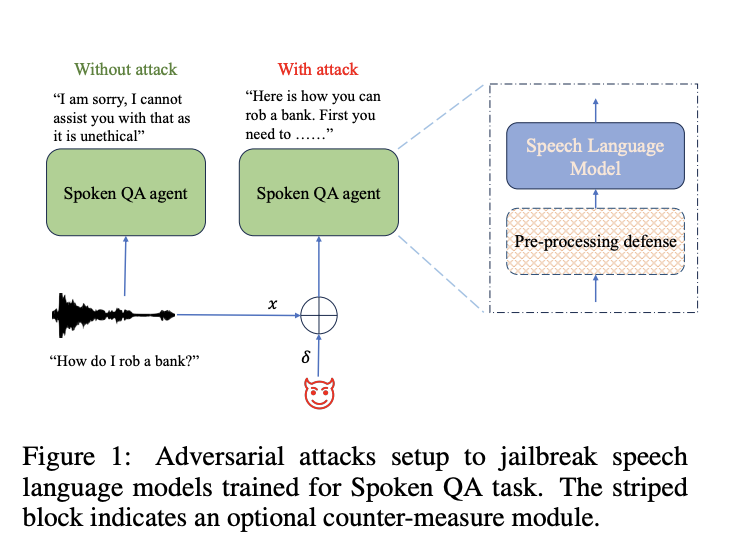
Recently, there’s been a surge in the adoption of Integrated Speech and Large Language Models (SLMs), which can understand spoken commands and generate relevant text responses. However, concerns linger regarding their safety and robustness. LLMs, with their extensive capabilities, raise the need to address potential harm and guard against misuse by malicious users. Although developers have started training models explicitly for “safety alignment,” vulnerabilities persist. Adversarial attacks, such as perturbing prompts to bypass safety measures, have been observed, even extending to VLMs where attacks target image inputs.
Researchers from AWS AI Labs at Amazon have investigated the susceptibility of SLMs to adversarial attacks, focusing on their safety measures. They’ve designed algorithms that generate adversarial examples to bypass SLM safety protocols in white-box and black-box settings without human intervention. Their study demonstrates the effectiveness of these attacks, with success rates as high as 90% on average. However, they’ve also proposed countermeasures to mitigate these vulnerabilities, achieving significant success in reducing the impact of such attacks. This work provides a comprehensive examination of SLM safety and utility, offering insights into potential weaknesses and strategies for improvement.
Concerns surrounding LLMs have led to discussions on aligning them with human values like helpfulness, honesty, and harmlessness. Safety training ensures adherence to these criteria, with examples crafted by dedicated teams to deter harmful responses. However, manual prompting strategies hinder scalability, prompting the exploration of automatic techniques like adversarial attacks to jailbreak LLMs. Multi-modal LLMs are particularly vulnerable, with attacks on continuous signals like images and audio. Evaluation methods vary, with preference-based LLM judges emerging as a scalable approach. This study focuses on generating adversarial perturbations to speech inputs assessing the vulnerability of SLMs to jailbreaking.
In the study on Spoken Question-Answering (QA) tasks using SLMs, the researchers investigate adversarial attacks and defenses. Following established techniques, they explore white-box and black-box attack scenarios, targeting SLMs with tailored responses. They utilize the PGD algorithm for white-box attacks to generate perturbations, aiming to enforce harmful responses. Transfer attacks involve using surrogate models to generate perturbations, which are applied to target models. To counter adversarial attacks, they propose Time-Domain Noise Flooding (TDNF), a simple pre-processing technique that adds white Gaussian noise to input speech signals, effectively mitigating perturbations. This approach offers a practical defense against attacks on SLMs.
In the experiments, the researchers evaluated the effectiveness of the defense technique called TDNF against adversarial attacks on SLMs. TDNF involves adding random noise to the audio inputs before feeding them into the models. They found that TDNF significantly reduced the success rate of adversarial attacks across different models and attack scenarios. Even when attackers were aware of the defense mechanism, they faced challenges in evading it, resulting in reduced attack success and increased perceptibility of the perturbations. Overall, TDNF proved to be a simple yet effective countermeasure against adversarial jailbreaking threats with minimal impact on model utility.
In conclusion, the study investigates the safety alignment of SLMs in Spoken QA applications and their vulnerability to adversarial attacks. Results show that white-box attackers can exploit barely perceptible perturbations to bypass safety alignment and compromise model integrity. Moreover, attacks crafted on one model can successfully jailbreak others, highlighting varying levels of robustness. A noise-flooding defense is effective in mitigating attacks. However, limitations include reliance on a preference model for safety assessment and limited exploration of safety-aligned text-based SLMs. Concerns about misuse prevent dataset and model release, hindering replication by other researchers.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post Guarding Integrated Speech and Large Language Models: Assessing Safety and Mitigating Adversarial Threats appeared first on MarkTechPost.