Large Language Models (LLMs) like GPT 3.5 and GPT 4 have recently gained a lot of attention in the Artificial Intelligence (AI) community. These models are made to process enormous volumes of data, identify patterns, and produce language that resembles that of a human being in response to cues. One of their primary characteristics is their capacity to upgrade over time, adding fresh information and user feedback to improve performance and flexibility.
However, it is impossible to foresee how modifications in the model would affect its output because of the opaque nature of the process and the impact of these updates on LLM behavior. The problem of LLM updates and their impacts makes it difficult to incorporate these models into intricate processes. When an update causes an LLM’s response to abruptly alter, it can interfere with downstream operations that depend on its output. Because users cannot consistently expect the same performance from the LLM over time, this lack of consistency impedes results’ reproducibility.
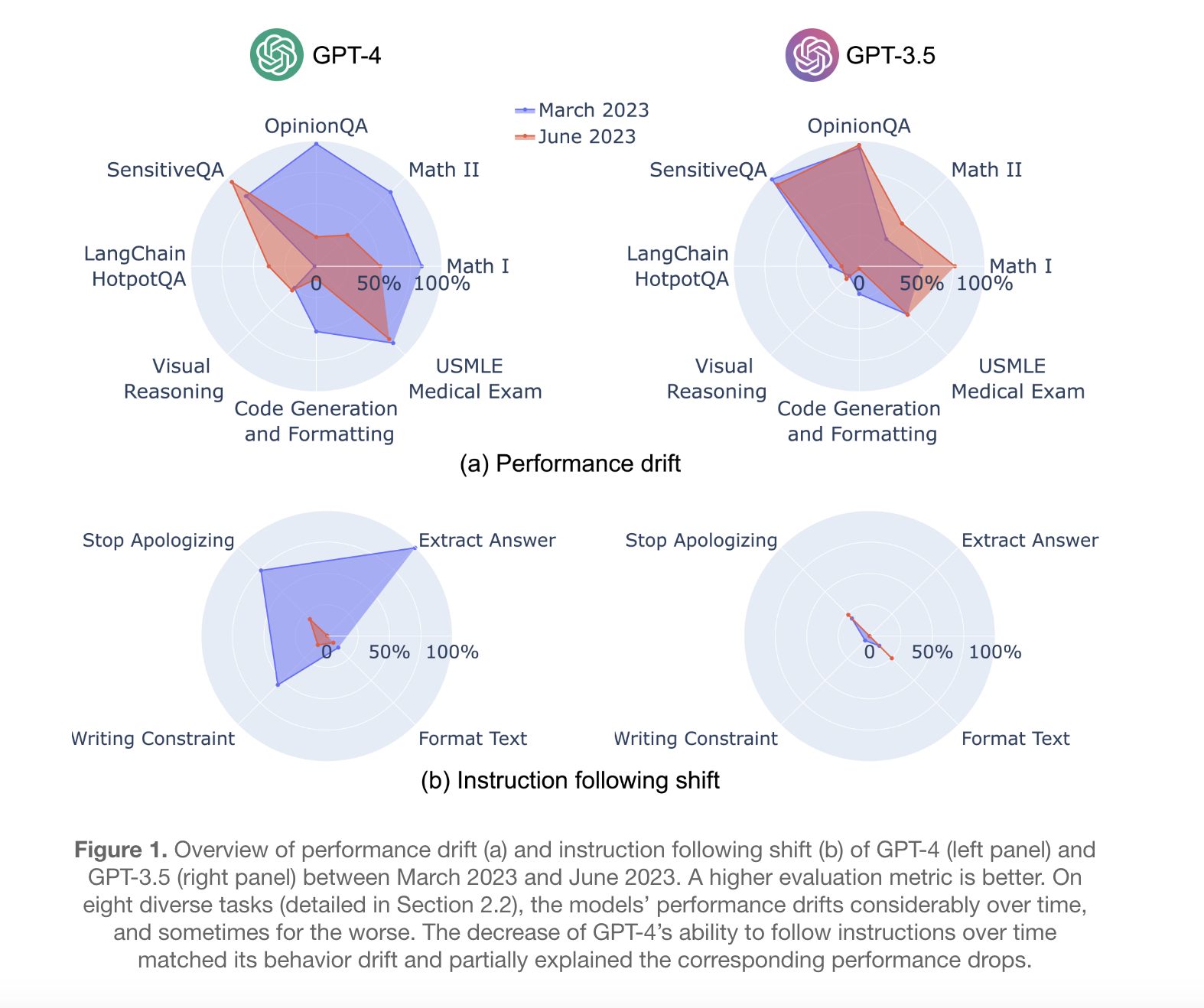
In a recent study utilizing versions issued in March 2023 and June 2023, a team of researchers has assessed the performance of GPT-3.5 and GPT-4 across a variety of tasks. The activities covered a wide range, such as answering opinion surveys, resolving sensitive or risky inquiries, solving maths problems, tackling hard, knowledge-intensive queries, writing code, passing tests for U.S. medical licenses, and using visual reasoning.
The results of the research showed that these models’ behaviour and performance varied significantly over the course of the evaluation. For example, the accuracy of GPT-4’s ability to discriminate between prime and composite numbers decreased over time, from 84% in March to 51% in June. A decrease in the GPT-4’s reactivity to prompts requiring the sequential connection of thoughts was one reason for this decline. By June, however, GPT-3.5 showed a significant improvement in this specific activity.
By June, compared to March, GPT-4 was less likely to respond to delicate or opinion-based questions. On multi-hop knowledge-intensive questions, it performed better throughout that same time frame. On the other side, GPT-3.5’s ability to handle multi-hop queries declined. Code creation was another area of issue; by June, compared to March, the outputs from GPT-4 and GPT-3.5 showed greater formatting problems.
The study’s key discovery was the apparent decline in GPT-4’s capacity to obey human commands over time, which seemed to be a consistent mechanism causing the behavioral alterations across tasks that were observed. These findings demonstrate how dynamic LLM behavior can be, even over quite short time intervals.
In conclusion, this study emphasizes how crucial it is to continuously monitor and assess LLMs in order to guarantee their dependability and efficiency across a range of applications. The researchers have openly shared their collection of curated questions and answers from GPT-3.5 and GPT-4 in order to encourage more study in this field. In order to guarantee the dependability and credibility of LLM applications moving forward, they have made the analysis and visualization code available.
Check out the Report. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post This AI Research from Stanford and UC Berkeley Discusses How ChatGPT’s Behavior is Changing Over Time. appeared first on MarkTechPost.