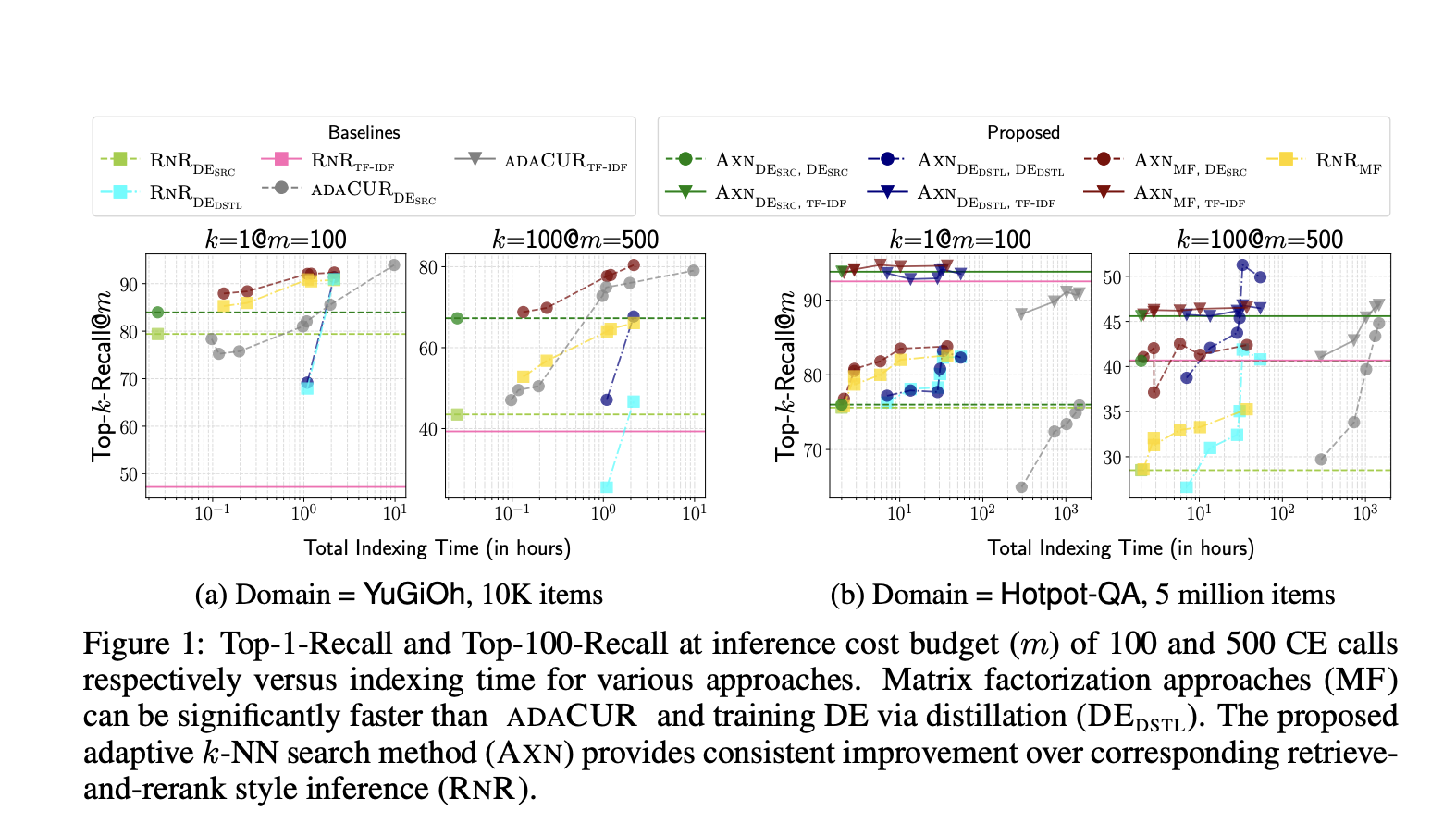
Cross-encoder (CE) models evaluate similarity by simultaneously encoding a query-item pair, outperforming the dot-product with embedding-based models at estimating query-item relevance. Current methods perform k-NN search with CE by approximating the CE similarity with a vector embedding space fit with dual-encoders (DE) or CUR matrix factorization. However, DE-based methods face challenges from poor recall because its new domains are not generalized well, and the test-time retrieval with DE is decoupled from the CE. So, DE-based and CUR-based methods are insufficient for a certain application setting in k-NN search.
Matrix factorization is widely used for evaluating low-rank approximation of dense distance and matrices, non-PSD matrices, and missing entries in sparse matrices. In this paper, researchers explored the methods for factorizing sparse matrices instead of dense matrices. An important assumption for matrix completion methods is that the underlying matrix M is low-rank, so it helps to recover missing entries by analysis of a small fraction of entries in M. Also, when features describing the rows and columns of the matrix are available, the complexity of samples used in this method to recover an m × n matrix of rank r with m ≤ n can be enhanced.
Researchers from the University of Massachusetts Amherst and Google DeepMind have introduced a novel sparse-matrix factorization-based method. This method optimally computes latent query and item representations to approximate CE scores and performs a kNN search using the approximate CE similarity. In comparison to CUR-based methods, the proposed method generates a high-quality approximation using a fraction of CE similarity calls. The factorization of a sparse matrix that contains query-item CE scores is done to evaluate item embeddings, and this embedding space is initiated by utilizing DE models.
The methods and baselines are rigorously evaluated on tasks like finding k-nearest neighbors for CE models and downstream tasks. Notably, CE models are utilized for tasks like zero-shot entity linking and zero-shot information retrieval, demonstrating how different design decisions impact the time it takes to index data and the retrieval accuracy during testing. The experimentation is conducted on two datasets, ZESHEL and BEIR, where separate CE models trained on ground-truth labeled data are used for both datasets. Two test domains from ZESHEL with 10K and 34K items(entities) and two test domains from BEIR with 25K and 5M items(documents) are used.
Researchers have also proposed an impressive k-NN search method that can be used with dense item embeddings generated by methods such as baseline dual-encoder models. This method yields up to 5% and 54% improvement in k-NN recall for k =1 and 100, respectively, over retrieve and rerank style inference with the same DE. Moreover, this approach to align item embeddings with the cross-encoder achieves up to 100 times and 5 times speedup over CUR-based methods and training DE through distillation-based, respectively, parallel matching or enhancing test-time k-NN search recall over baseline methods.
In conclusion, researchers from the University of Massachusetts Amherst and Google DeepMind introduced a sparse-matrix factorization-based method that efficiently computes latent query and item representations. This method optimally performs k-NN search with cross-encoders by efficiently approximating the cross-encoder scores using the dot product of learned test query and item embeddings. Also, two datasets, ZESHEL and BEIR, were used during the experiment, and both used separate CE models trained on ground-truth labeled data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post Sparse-Matrix Factorization-based Method: Efficient Computation of Latent Query and Item Representations to Approximate CE Scores appeared first on MarkTechPost.